

Spoiler alert!
A lot of neat things have just been added to the Arm Neoverse datacenter compute roadmap, but one of them is not a datacenter-class, discrete GPU accelerator. And another one that is also not there is a more specific matrix math accelerator like the ones that Intel (well Habana Labs), SambaNova Systems, Tenstorrent, Groq, or Cerebras Systems have created.
And that is a shame, really.
Considering all of the money that Nvidia – former almost-owner of Arm Holdings and a company that promised to run its GPU designs through the Arm licensing mill if its $40 billion takeover of Arm was allowed to pass muster with the regulatory authorities on Earth – is raking in, not hand over fist but with a acre-wide combine, you would think that the market would be demanding that Arm come up with a cheaper alternative to Nvidia’s existing “Hopper” H100/H200 and impending “Blackwell” B100/B200 discrete GPUs and AMD’s existing “Antares” Instinct MI300 and future Instinct MI400 discrete GPUs.
We know what you are thinking. Why didn’t you mention Intel’s discrete datacenter GPU? Well, Intel’s “Ponte Vecchio” Max Series GPUs, excepting the ones inside the “Aurora” supercomputer at Argonne National Laboratory, are not really a contender in the discrete GPU space, but sadly if Intel could make a million of them right now, it would have sold a million of them, and it is a long time until Intel will converge the Max Series GPU with the Gaudi matrix accelerators to create something that might be competitive.
No, that ship has long since set sail, with Google having already created its TPU, Amazon Web Services having already created its Trainium and Inferentia, Microsoft having already created its Maia, and Meta Platforms already working on its MTIA family. With close to half the market, in terms of datacenter infrastructure revenue, already doing their own thing, there is too much risk in trying to build a new GPU or matrix architecture or else Arm would be doing it. Because of that that risk, we could argue that only Arm can do it and have a hope of success.
If someone had the gumption to create a GPU that was bug-for-bug compatible with Nvidia’s devices, we could at least be amused by a reprise of the mainframe clone wars that IBM fought with Amdahl, Fujitsu, and Hitachi – which IBM eventually won despite several antitrust lawsuits – or the epic battles between Intel and AMD with the X86 architecture in the datacenter – by the way, AMD won, twice.
But alas, it looks like Arm doesn’t have the stomach for that. No one else does, either. Precisely because of what happened with the mainframe and X86 architecture.
So Arm Holdings, a public company again in its own right and the thing that is more valuable than its SoftBank parent company thanks to a skinny stock float and irrational exuberance, is going to stick to its CPU knitting and catch whatever part of the AI training and inference money it can with its Neoverse CPU designs. Nothing makes it more clear than this chart that is part of the Arm 2024 Neoverse roadmap briefing that we sat in on:

Know your place. Don’t make trouble. Quit while you are ahead.
To be fair, all three of the CPUs above are based on Arm architecture alongside those homegrown accelerators, and at least two our of the three DPUs running along the bottom are Arm architecture, too. (We are not sure about Azure Boost, but if there is a CPU in there, it is almost certainly based on Arm cores of some sort.) This kind of chart was a dream back in 2011, when Arm started its assault on the X86 CPU in the datacenter in earnest. And the rise of Arm CPUs in the hyperscaler and cloud builder datacenters is an absolute success.
We just want more is all. And we think that the complexity and uniqueness of the AI workloads in the datacenter warrant more. A cynic might say that Nvidia was willing to pay $40 billion for Arm Holdings to keep the IP company from creating and licensing a killer GPU, and that the deal kept Arm on the backburner while Nvidia saw the GenAI wave coming.
Even Arm’s own spider graphs outlining the performance vectors for different kinds of datacenter workloads argues for more:
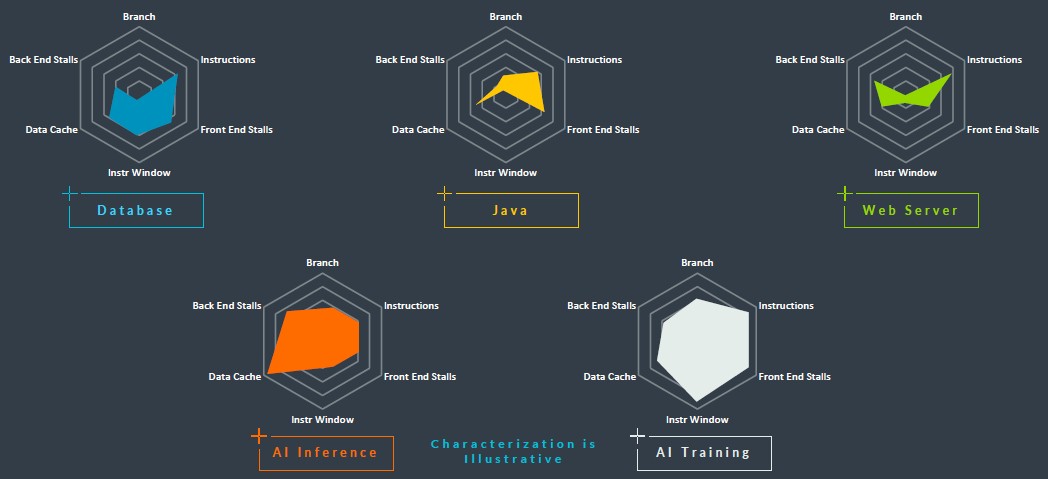
Alas, here in 2024, the more that we are getting from Arm Holdings is the continuation of the wide variety of Neoverse core types as the roadmap is extended, and Compute Subsystem, or CSS, licensing packages that will be available for the high performance V-class cores alongside the N-class cores that were already announced last summer with the “Genesis” intellectual property wrapped around the “Perseus” N2 cores.
Nvidia’s “Grace” CG100 and Amazon’s Graviton4 are based on the “Demeter” V2 cores, which we drilled down into last summer. Microsoft’s 128-core Cobalt 100 processor is based on the Genesis CSS N2 design, and we strongly suspect that the rumored “Maple” Arm server CPU from Google will be based on CSS jump-starting, too – perhaps on the CSS stack for the “Poseidon” V3 core or the “Hermes” N3 core. A lot will depend on what Google is trying to accomplish, and when. Inevitably, we think all of the hyperscalers and cloud builders will deploy Arm CPUs with a mix of N and V cores in their datacenters, and E cores at the edges. They will have a mix of X86 processors, too, of course, and those will likely be the dominant CPU for a long time. But, change can happen quickly sometimes, so don’t rest on your laurels, AMD, and don’t rest on AMD’s laurels, either, Intel.
Let’s dive into the Neoverse CPU roadmap, starting with the roadmap from September 2022 as a refresher because, frankly, it has more detail on it than the 2024 roadmap:
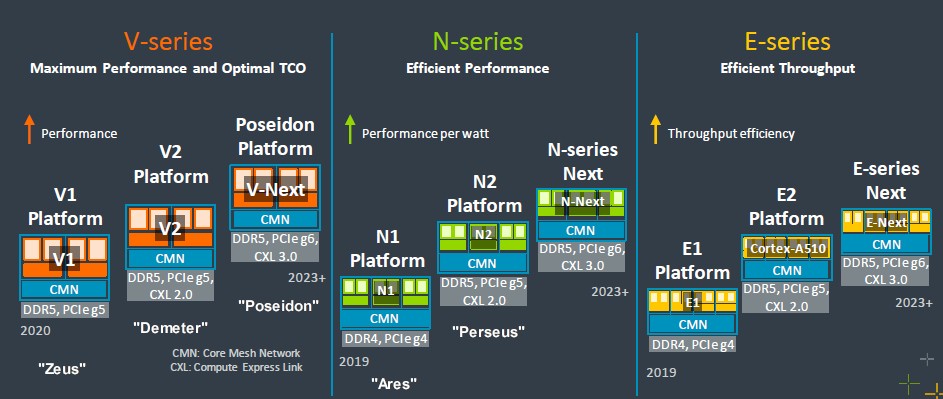
The Neoverse effort is now six years old, and back in October 2018 when it started the idea was to do a new core and server platform every year and climb through the manufacturing process step changes at Taiwan Semiconductor Manufacturing Co every year. The “Ares” platform for 2019 was etched with 7 nanometer transistors, and “Zeus” was expected on enhanced 7 nanometer processes in 2020 and “Poseidon” was expected in 2021 on 5 nanometer processes. More importantly perhaps than this clock-work cadence was the expectation – hope, really – that Arm could deliver 30 percent performance improvements with each generational step – partly through architecture and partly through features – for the foreseeable future.
Then the Neoverse roadmap was trifurcated into the N, V, and E cores and it has taken a bit more time to get the cores into the field. Poseidon V3 cores, for instance, are only now available when they were originally expected in 2021 and then revised to be coming in the much vaguer “2023+” in the roadmap from two years ago. These things take time, and the hyperscalers and cloud builders who are really driving the Neoverse roadmap needed to get their chip plans in order in the middle of a global pandemic that really upset supply chains and plans.
We think it will be smoother sailing for Arm and its customers with Neoverse going forward.
Just for reference, here is last year’s Neoverse roadmap, which came out with the CSS launch and to which we added codenames for clarity:
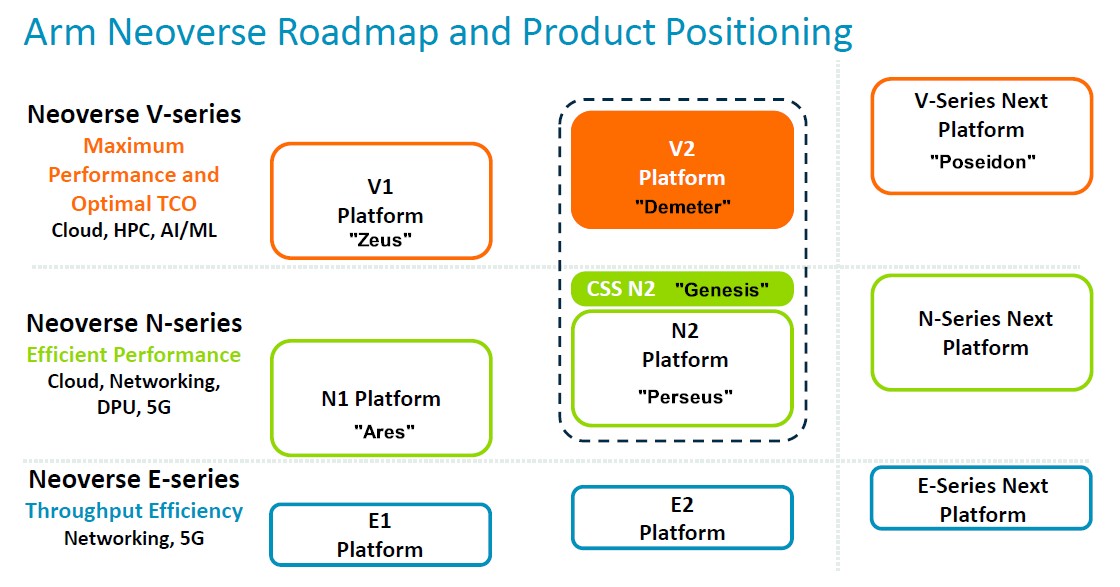
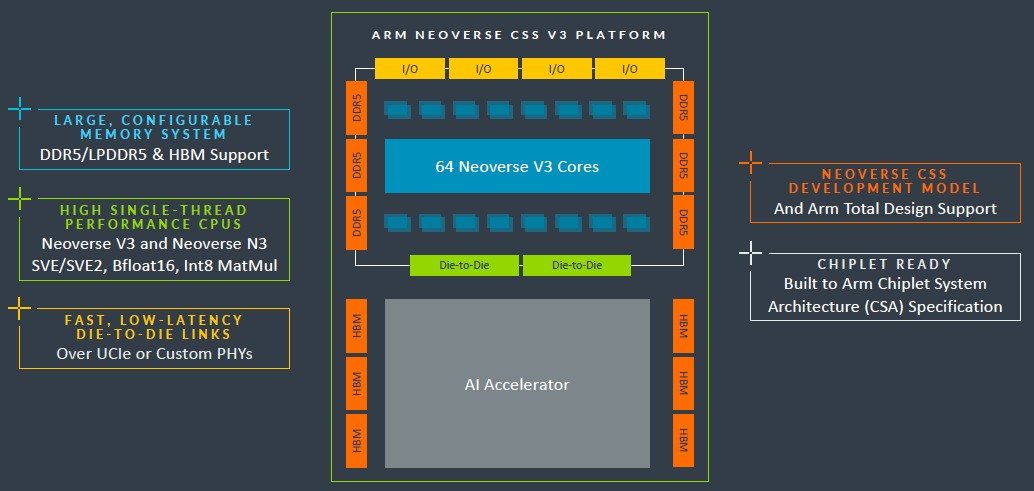
We said last year that there needed to be a CSS package for the Demeter V2 core that was being deployed by Nvidia initially, and it doesn’t look like that will happen. The good news is that the Poseidon core and its CSS package are available now, and so is the Hermes N3 core and its CSS package, as the 2024 Neoverse roadmap shows:
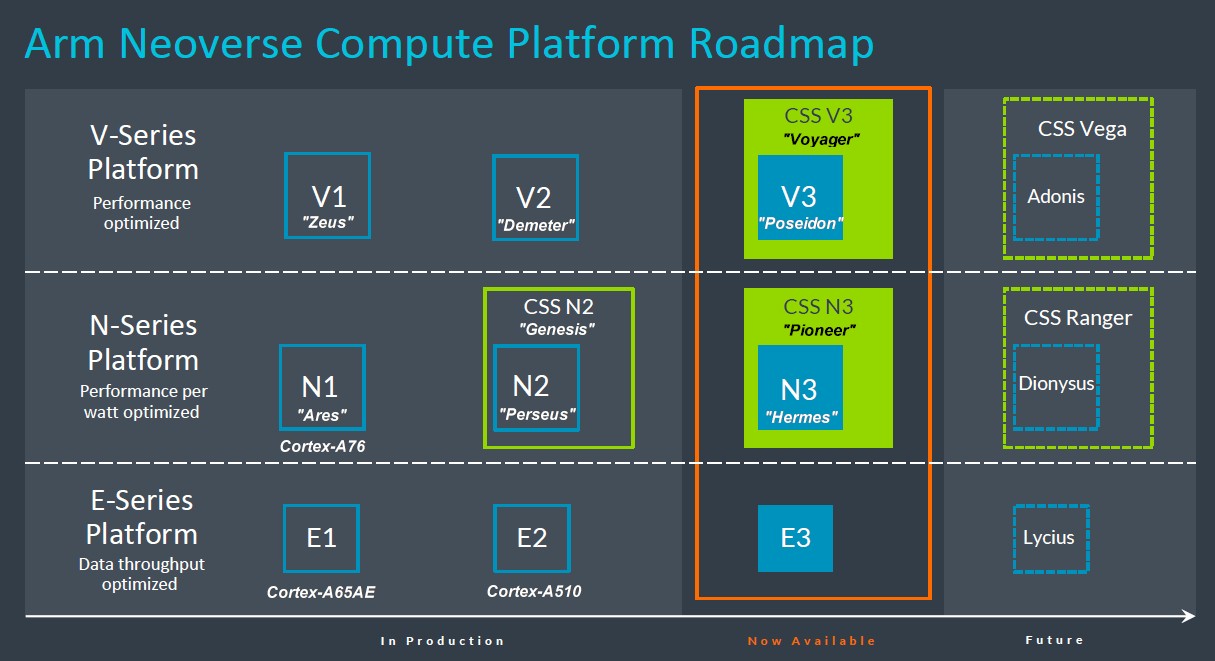
We didn’t know what the codenames were for the N3 and V3 CSS packages, but we did not were going to be “Exodus” and “Leviticus” in keeping with the books of the Old Testament that is suggested by the Genesis name for the Neoverse N2 IP stack. As it turns out, they are “Voyager” for CSS V3 and “Pioneer” for CSS N3.
Arm has left off the years on the X axis on this 2024 roadmap, so we don’t know precisely when the follow-on “Adonis” V4 cores and their “Vega” CSS package, the follow-on “Dionysus” N4 cores and their “Ranger” CSS package, and the follow-on “Lycius” E4 cores will be available. More details are promised in the future by the Arm Neoverse top brass.
Here is what we do know. The CSS N3 package starts with a block of 32 N3 cores and has a pair of DDR5 memory controllers, a pair of I/O controllers, and optional die-to-die interconnects to create compute complexes that have what we expect will be two complexes glued together to create a socket, yielding 64 cores. Those N3 cores are build to the latest Armv9.2 specification.
The process technology was not announced for the N3 cores or the CSS N3 package, but we believe it will have options for 5 nanometers and 3 nanometers from TSMC and whatever analogs there are at Samsung and Intel.
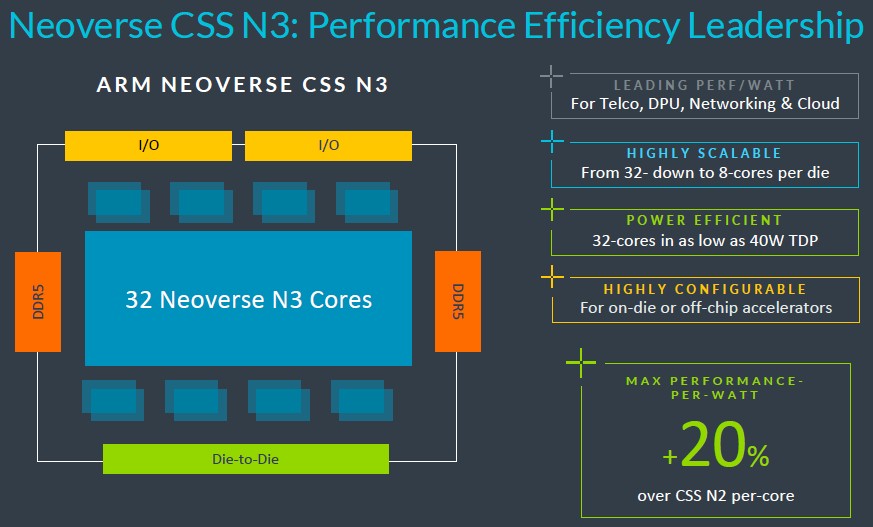
The data point above that an N3 CSS package can deliver 32 cores in a 40 watt thermal design point strongly suggests that this design will lead with TSMC’s 3N 3 nanometer process.
The N3 package can scale down as small as eight cores, according to Arm, presumably with one DDR controller and one I/O controller. From the prior September 2022 roadmap, we would have suspected that the N3 cores will be put into packages that support DDR5 memory and PCI-Express 6.0 peripheral controllers with a CXL 3.0 coherency overlay. But it might be held back to PCI-Express 5.0 peripherals and CXL 2.0, if the CSS V3 package described below is a guide. (And we are not saying that it is.)
We don’t know how wide the vector units are on the N3 cores, or how many of them there are, but if the N3 cores are going to do AI inferencing and some AI training on CPUs – and that is what Arm believes will happen – then they will have to be beefed up compared to the N2 cores, which had a pair of 128-bit vectors that could do four FP64 operations per clock and then carve that down for mixed precision performance. A proper matrix math unit – a tensor core, as it were – will probably be added to the N3 core as well, but Arm is not saying.
The Poseidon V3 core will probably be beefed up in similar ways, having twice as much vector and matrix oomph as the Hermes N3 core if history is any guide. But we don’t know that yet. The Zeus V1 core had a pair of 256-bit vectors and with the Demeter V2 cores, this was changed to four 128-bit vectors; both did eight FP64 operations per clock, but the latter design was more efficient. It will be interesting to see what happens here with the V3 core. Four 256-bit vectors would be weird, given what we know about the V1 core, and eight 128-bit vectors might sound weird until you realize that is precisely how Intel created the AMX matrix math unit in the “Sapphire Rapids” Xeon SP CPU.
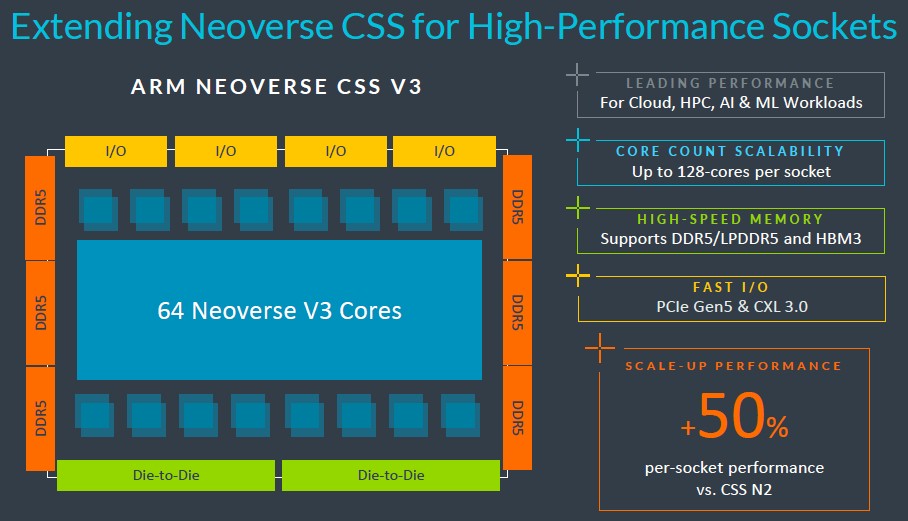
In any event, the base CSS V3 building block is 64 V3 cores with six DDR% memory controllers, four PCI-Express 5.0 I/O controllers, and a pair of die-to-die interconnects. The September 2022 roadmap told us to expect PCI-Express 6.0 and CXL 3.0 with the V3 generation. This is not going to happen until V4 and possibly the N4 generations. (It is also possibly that N3 gets PCI-Express 6.0 first and V3 doesn’t get it at all.)
This CSS V3 complex offers 50 percent better performance than the stock CSS N2 complex, according to Arm, and two of these can be put onto a package to scale to 128 cores in a single socket. We are surprised that it can’t scale to 256 cores, but that may be a limitation of CSS, not the V3 architecture itself. We are certain that someone could build a 256-core V3 socket; it may not make sense technically or economically, however.
The V3 packages will support DDR5 memory or HBM stacked memory, and it will be interesting to see if any of the CPU makers of the world will do HBM. Why not? The benefits for HPC and AI are obvious, and when money is no object, as seems to be the case with GenAI, why not build a hot rod?
Arm is keen to point out that the CSS V3 package is designed to hook directly and tightly to accelerators, which is something that is clearly important to Nvidia given its Grace-Hopper superchip complexes.
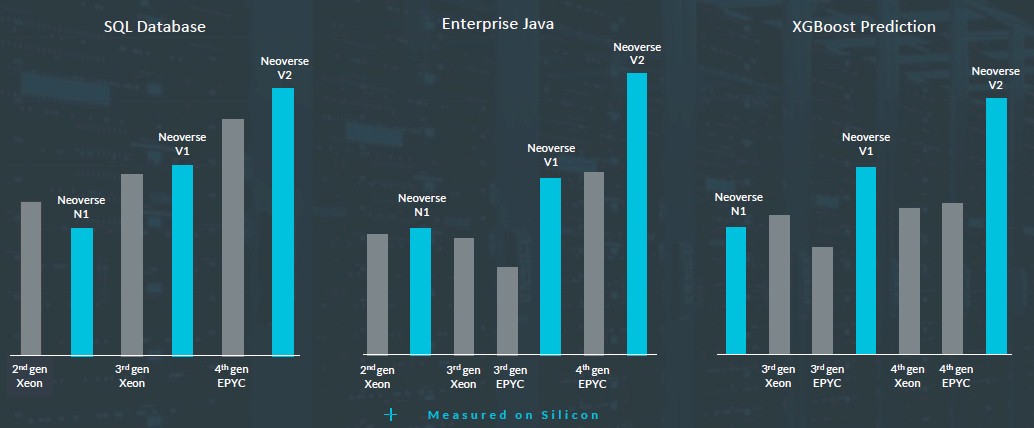
Just to whet the appetite, Arm gave out some early performance specs for the V2 cores against prior N1 and V1 cores as well as for the past two generations of X86 processors from Intel and AMD. Take a gander at these:
And here is another one that shows how V3 stacks up against V2 and how N3 stacks up against N2 for a wide variety of workloads:
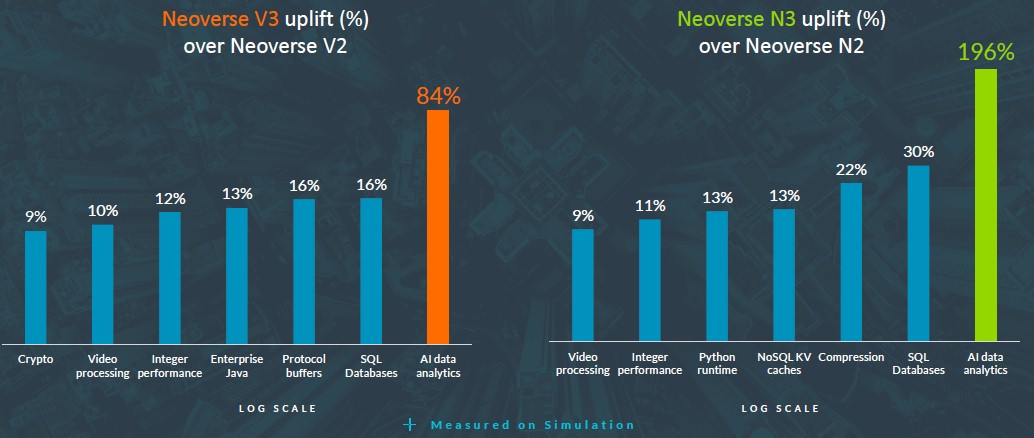
Arm worked particularly hard on boosting the performance of XGBoost, which is a classical machine learning algorithm for doing regression, classification, and prediction.
And just for fun, Arm gave out some AI inference benchmarks on a relatively small LLaMA 2 large language model with only 7 billion parameters:
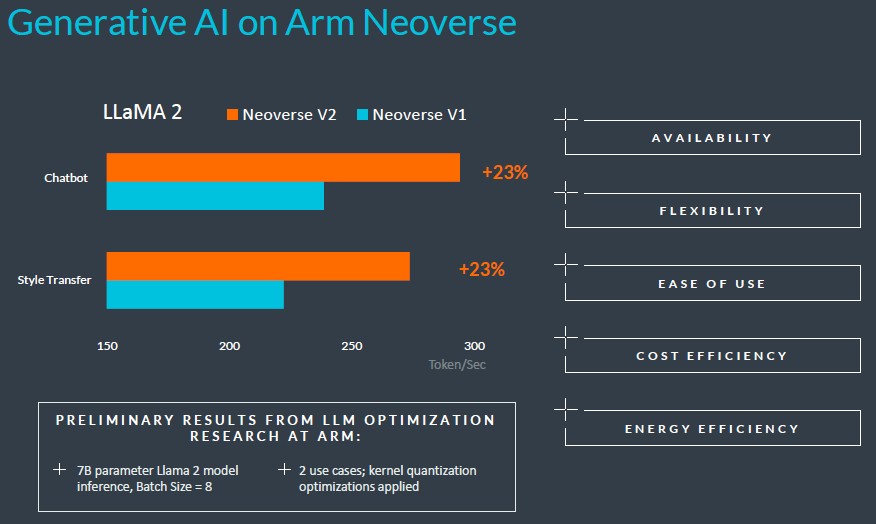
Data was not available for the V3 design, which is what everyone will care about.




Great presentation and analysis! I’m sure glad the Neoverse Poseidon V3 is coming under the CSS Voyager umbrella for straightforward cut-and-paste SoC design. Like you, I wonder about the combination “PCIe Gen5 & CXL 3.0” on that slide as CXL 3 is commonly viewed as coming with PCIe6 (maybe an ARM-fingertip typo?).
There seems to be a nice progression of performance core counts between A64FX at 48 cores, Rhea1 at 64 cores, Grace at 72 cores, Graviton4 at 96 cores, and now this V3 at 128 cores (2×64, out-of-the-box). As you suggest, a 4-die 256 core package might be possible if some DDR5 or I/O modules are replaced with Die-to-Die blocks, but then perf may suffer through memory bottleneck.
The big mystery though is where the AI uplift comes from (both V3’s near 100%, and N3’s near 200%). Are the vector units updated in a way that makes software better-able to use them, or did they just double-up on them, to “eight 128-bit vectors” for example? Maybe HBM3 (but only in the V3 then)?
In any instance, with so many countries wanting to have chip-making sovereignty after the recent supply-chain disruptions, seeing ARM make the performance V-series of the twelve cheeky Olympians more easy to integrate into one’s chip design is definitely a great thing in my view!
GPUs and AI are not equivalent classes. Tenstorrent, Cerebras, etc are not. Arm needs a discrete GPU like they need another hole in the head. AI/ML Inference doesn’t necessarily need exactly what AI/ML Traininig needs either. Long term the substantive part of delivered AI services is going to be for “inference” , not “training”. Nvidia has a temporary scarcity lock on “training”. They don’t have inference locked up in anywhere as close as much.
The new CSS blocks appear to have UCIe chiplet interconnect also. An integrated Inference die via UCIe has lots of potential upside without Arm spreading their pragmatically limited budget even thinner. (UCIe is a bit of a dual edge sword because it could do big harm to Arms iGPU business also over the long term.) Arm has a substantively high number architecture license holders which are also a long term viability threat to CSS like products. Again a very high load on their limited R&D resource budget.
N3 cranks up AI/ML performance in some areas by 100%. Extremely likely they are targeting inference loads with very low latency tolerances rather then the training ‘bubble’ we are in right now. Long term, Inference is going to grow bigger than Training. It simply has more usable and privacy utility (value).
Have you thought about the idea that Graphcore will get folded into Arm, so data center GPU/AI accelerator story gets more complete? Read the Telegraph story: https://www.telegraph.co.uk/business/2024/02/17/british-ai-champion-graphcore-explores-foreign-sale/
I have not. But wouldn’t that be neat! Arm thinks I am being nuts or mean or both by suggesting it should have a beefy GPU/XPU.
You’ll have seen that the two CEOs interact on LinkedIn with ‘likes’ since around the Telegraph story broke, just stating the facts.