
With large language models, bigger is better (and faster) but better is also better. And one of the key insights that the Meta AI research team had with the Llama family of models is that you want to optimize for the lowest cost, highest performance AI inference with any model and then deal with the inefficiencies that might result from AI training.
And now, with Llama 3, Meta Platforms has made both AI training and inference get better, giving the latest Google Gemini Pro 1.5, Microsoft/OpenAI GPT-4, and Anthropic Claude 3 models a run for the – well, we suppose it is money but that remains to be seen.
The original Llama 1 model, as we are now calling it, was unveiled in that long ago and far away time of February 2023, and we went into detail about how Llama was different from all of the big LLMs back then and we are not going to go over all of that again. You can read the paper that described the four different Llama models and the open source dataset used to train them at this link. The Llama 1 models were not open sourced, but Meta Platforms did provide the source code to researchers who applied for it, and the expectation was that Llama would eventually be opened up and set free.
With Llama 1, Meta Platforms delivered models with a fairly small number of parameters – 7 billion, 13 billion, 33 billion, and 65 billion – and said it could meet or beat the much bigger GPT-3 175B and PaLM 540B models from OpenAI and Google. The initial results showed something that should have been obvious to anyone: More data beats more parameters.
You will note that this is just a corollary of what we have paraphrased as more data beats a better algorithm every time, which is a riff on an idea presented by Peter Norvig, an education fellow at Stanford University and a researcher and engineering director at Google for more than two decades, who co-authored the seminal paper The Unreasonable Effectiveness of Data back in 2009.
The important thing with the Llamas is that Meta Platforms was focusing on lowering inference costs and increasing inference performance, the Llama models also bucked the conventional wisdom from the creators of the Chinchilla LLM that there is an ideal model size, compute budget, number of tokens, time to train, inference latency, and performance. Meta Platforms took its smallest model with 7 billion parameters and put more than 1 trillion tokens through it, and Llama 1 7B continued to improve compared to chewing on cud with fewer tokens. The Llama 1 models were trained on 2,048 “Ampere” A100 GPUs, with the 7B and 13B models using 1 trillion tokens and the 33B and 65B models using 1.4 trillion tokens. The context length – the amount of data you could input into a prompt to Llama 1 was a mere 2,048 tokens.
With Llama 2, which launched in July 2023, gone was the ransom note spelling – it is not LLaMA, short for Large Language Model Meta AI, which technically would be LLMMAI but who is keeping track – and now we just call it Llama. The Llama 2 models were trained with 2 trillion tokens, came in 7B, 13B, and 70B parameter variations, and had a context window doubled to 4,096 tokens. It had over 1 million human annotations for reducing errors and hallucinations, and provided a few points more accuracy on tests. (You can read the Llama 2 paper here.) Importantly, the Llama 2 models were open sourced properly and wholly and were free for both research and commercial use. Which is why we think, in the long run, the PyTorch framework and the Llama models will be widely used by enterprises who want to roll their own AI.
Last week, Meta Platforms rolled out Llama 3 and its improved Meta AI chat interface, which is embedded in its Facebook, Instagram, WhatsApp, and Messenger applications and which is now based on Llama 3.
With Llama 3, the model comes with 8B and 80B parameter variations – thus far Meta Platforms has resisted the temptation to create an 800B parameter model, no doubt to try to keep inference compute and therefore costs low – and was trained against a staggering 15 trillion tokens. Over 5 percent of that training data – so somewhere around 800 million tokens – was to represent data in 30 different languages. And while Meta Platforms did not give a token count for this area, it did say that 4X the amount of code – meaning programming language code – was used with Llama 3 training compared to Llama 2. (We wonder where Meta Platforms is curating this code, and whether it puts its own code into the training set?) Interestingly, Llama 2 models were used to sift through those trillions of tokens to identify appropriate data sets to add to the training for Llama 3. The source code and training data for Lama 3 is available here on GitHub and here on Hugging Face; the model weights and tokenizer are available directly from Meta Platforms there.
Meta Platforms hinted in its announcement that other parameter counts would be available for Llama 3 models in the future, so don’t count out larger and smaller models for the future. Meta Platforms has not released the Llama 3 technical paper as yet but the announcement has some interesting tidbits.
“In line with our design philosophy, we opted for a relatively standard decoder-only transformer architecture in Llama 3,” the dozens of researchers who worked on the LLM wrote in the announcement blog that announced Llama 3. “Compared to Llama 2, we made several key improvements. Llama 3 uses a tokenizer with a vocabulary of 128K tokens that encodes language much more efficiently, which leads to substantially improved model performance. To improve the inference efficiency of Llama 3 models, we’ve adopted grouped query attention (GQA) across both the 8B and 70B sizes. We trained the models on sequences of 8,192 tokens, using a mask to ensure self-attention does not cross document boundaries.”
Meta Platforms has larger variations of Llama 3, with the biggest one having over 400 billion parameters. We suspect that these will be announced concurrent with other capabilities that are still not ready for prime time but which are part of the Llama 3 stack, including the ability to do multimodal processing, conversing in multiple languages, and having a larger context window. (Presumably, this is still at 4,096 tokens like Llama 2, but Meta Platforms did not say in the announcement. When we asked the Meta AI chatbot, it said it was indeed 4,096 tokens.)
The Llama 3 models were trained on a pair of clusters based on Nvidia “Hopper” H100 GPUs, one using Ethernet and the other using InfiniBand, which we detailed here last month and which have 24,576 GPUs each. Meta Platforms says that its most efficient implementation of Llama 3 ran across 16,000 GPUs and with all kinds of system tweaks, the training was 3X more efficient than Llama 3. That said, the compute utilization reached only 400 teraflops per GPU across those 16,000 GPUs. With sparsity off and running in FP16 half precision, the H100 is rated at 989 teraflops, so that is only 40.4 percent computational efficiency. If sparsity support was activated in the H100s running Llama 3 or the data formats were in FP8 quarter precision, then that would only be 20.2 percent computational efficiency. And with FP8 with sparsity on, that would be only 10.1 percent computational efficiency.
Here is how Llama 3 7B and 70B stack up against other models working in “instruct” mode, where they have to do something like take tests or do math versus Google Gemma and Gemini Pro 1.5, Mistral, and Claude 3:
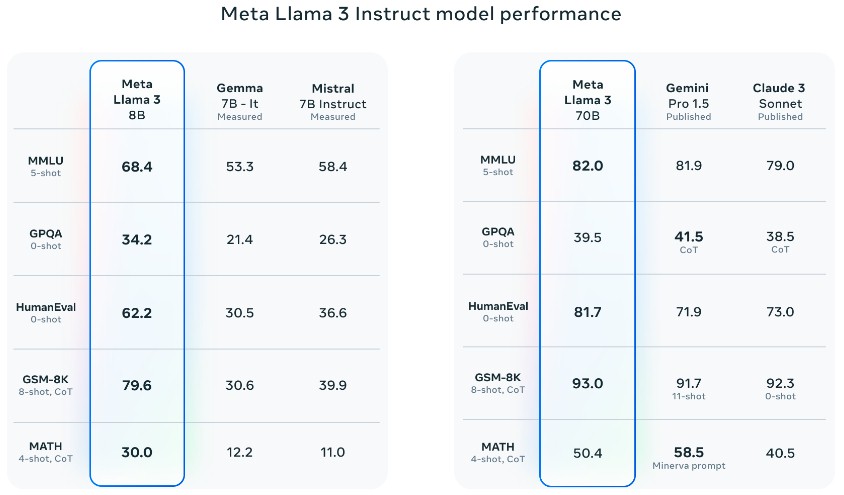
The benchmarks above are Massive Multitask Language Understanding benchmark, which tests context processing; the Graduate-Level Google-Proof Q&A multiple choice tests for biology, physics, and chemistry; the HumanEval code generation test; the GSM-8K grade school math test; and the MATH word problem test.
Here is how the pre-trained Llama 3 LLM stacked up against other pre-trained models for five different benchmarks:

AGIEval English is an amalgam of college entrance exams; BIG-Bench Hard, which is a bunch of logic puzzles to test common-sense reasoning; ARC-Challenge is an abstract reasoning corpus based on complex symmetrical patterns; DROP is short for – well, sort of – Discrete Reasoning Over the content of Paragraphs and it is a reading comprehension test.
Once again, Meta Platforms stressed that it was keen on keeping models small and running lots of data through them. This takes more time and computation, but it ends up with good results even if training might be more costly. It means inference is less costly, which is more important for the Meta Platforms application stack.
“We made several new observations on scaling behavior during the development of Llama 3,” the techies at Meta Platforms write. “For example, while the Chinchilla-optimal amount of training compute for an 8B parameter model corresponds to ~200B tokens, we found that model performance continues to improve even after the model is trained on two orders of magnitude more data. Both our 8B and 70B parameter models continued to improve log-linearly after we trained them on up to 15T tokens. Larger models can match the performance of these smaller models with less training compute, but smaller models are generally preferred because they are much more efficient during inference.”
And just for fun Meta Platforms showed off the performance of its Llama 3 benchmark on the pre-trained benchmarks when it had in excess of 400 billion parameters:

Here’s the rub. The Llama 3 8B pre-trained model had a grade point average of 62.1 percent, which is an F where we come from. Llama 3 70B did better with an average grade of 79.3 percent, but that is still only a C+ average. Not going to get into a good university with that GPA. The Llama 3 400B+ pre-trained model – and remember this model is still being trained so its grades will no doubt improve and also that we don’t know how many parameters above 400 billion this variant of Llama 3 is using, so don’t assume it is 400B and it is very likely 800B – the LLM gets a GPA of 83.9 over those five tests and that is a solid B. Yes, the small models run fast on inference, but clearly the larger models get better grades.
Which one do you want embedded in your applications or those of the people and companies you do business with? (The answer could be no LLMs, we realize.)
And here is a good question: Where is the Red Hat for PyTorch and Llama? Llama had over 30 million downloads from February through September 2023, and 10 million of those came in September alone. At this rate, Llama will have broken about 100 million downloads by now if downloads are linear from September last year to now.
Is it actually going to be IBM watsonx plus Red Hat Enterprise Linux plus OpenShift for Kubernetes containers plus OpenStack for the underlying cluster virtualization management? Will a new player emerge? Anyone want to start a new business?
Wouldn’t it be funny if IBM sells a ton of software and support because of generative AI? It might be helpful to remember that WebSphere, which is a gussied up Apache Web server with a Tomcat Java application server embedded in it, has brought IBM untold tens of billions of dollars in revenues over the past two and a half decades and probably half of that dropped to the bottom line.

Cool article! Google (Norvig et al.) with its SparseCores ( https://www.nextplatform.com/2023/08/29/the-next-100x-for-ai-hardware-performance-will-be-harder/ ) seems to seek to train very large models that will “self-delineate” (prune) into domain-specialized activation sub-networks, from which inference efficiency would result. Their 2009 paper seems to suggest as much: “Choose a representation that can use unsupervised learning on unlabeled data”.
Meta on the other hand seems to focus more on a LeCun perspective that smaller models may work better: “a trillion words, it would take […] 22,000 years for a human reading eight hours a day to go through […]”. This, though, may require further exploration of model architectures, and here, Llama 3 remains “a relatively standard decoder-only transformer” (“Meta Platforms rolled out Llama 3” link). Hopefully, some more architectural explorations, and/or a mixture of simpler models, or even a combination of logic-based and biomimetic AI, can help get a “GPA of 83.9” with less than 800B parameters (to promote inference efficiency).
Funnily enough, the “Unreasonable Effectiveness of Data” paper states: “we can expect Semantic Web technology to work best where an honest, self-correcting group of cooperative users exists and not as well where competition and deception exist”. ANN-based AI would then come to the rescue of “logic-based” AI in such “human” situations, as in Noam Brown’s (OpenAI) approach to Texas hold’em poker, and Diplomacy (maybe).
It looks like Microsoft agrees with Meta on this, as they’ve (84 co-authors; 7 per page) just developed their “Phi-3 Mini” model, with ½ as many parameters as Llama 3 8B, yet similar MMLU performance (perf varies on other tests), and aimed at phones ( https://www.theregister.com/2024/04/23/microsoft_phi_3_mini/ ). It’s great to see this competition towards smaller yet as “accurate” models that can help reduce inference infrastructure costs.
So how it Meta making money off this? How is anyone outside of the hardware vendors making money off AI right now? Just looking at the numbers of GPUs to run the initial training, and the salaries of the engineers and scientists… it really makes me wonder if we’re going to hit the AIpocolypse in the next five years when people realize they’re not making money, but that NVidia has basically sucked all the money into their own coffers…
They are adding AI so they can continue to make money in ads and social networking and messaging and trying to figure out how to make money in an AI-infused metaverse that people will live, work, and play in. Not a world I want to participate in. I will take the real one, thank you very much. But I have no doubt that lots of people will spend a lot of time there, just as they do with Facebook and TikTok today.