
Let’s just say it right here at the beginning. The first wave of attempts at creating Arm server chips –Calxeda, Applied Micro, AMD, Marvell, Nvidia, and Samsung, among others – was disappointing. And so was the second wave – with Broadcom, Cavium, Qualcomm, and Nuvia – now that we think on it.
But with the third wave of Arm server chips, being led by the hyperscalers and cloud builders (Amazon Web Services, Microsoft, Google, Alibaba, and Tencent – and a few independent chip designers (mainly Ampere Computing, HiSilicon, Nvidia, and SiPearl) working in concert with Arm Ltd, the creator and maintainer of the Arm architecture that is looking to go public (again), it looks like Arm server chips are here for the long haul.
Without question, one of the reasons for that third-time charm of the Arm server collective was the strategy of Arm Ltd back in October 2018 to separate its client chip designs from its server chip designs. With its Neoverse effort, Arm cores were designed from the ground up to have features that were necessary for server workloads (as well as the heftier transistors they require) and things like L2 caches and mesh interconnects to lash them together into core complexes. The Neoverse reference architectures allowed chip designers to plug in their choice of DDR memory, PCI-Express peripheral, and network interface controllers, largely de-risking the creation of a server chip design while at the same time allowing flexibility and, for those with an Arm architecture license, the ability to make custom Arm cores that were derivatives of the Neoverse cores, or not.
The commitment back then with the Neoverse reference platforms was to do a new Arm server platform every year and deliver 30 percent or more performance with each successive generation.
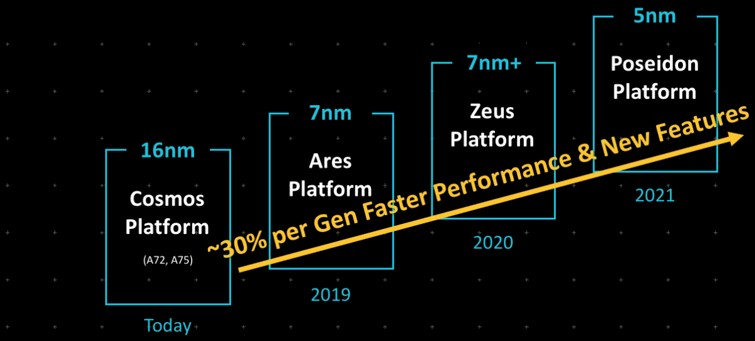
It was an aggressive and somewhat simplified roadmap, aimed at creating CPUs based on the Arm architecture that would span from 4 to 128 cores and from gigabytes to terabytes per second of memory bandwidth to address the compute needs from the edge all the way up to cloud datacenters.
The Neoverse roadmap was expanded and fleshed out more fully in September 2020 with the creation of the V-series (with an emphasis on fat vectors for floating point computation), the N-series (with high throughput integer performance) and the E-series (aimed at delivering energy efficiency for modest compute needs):
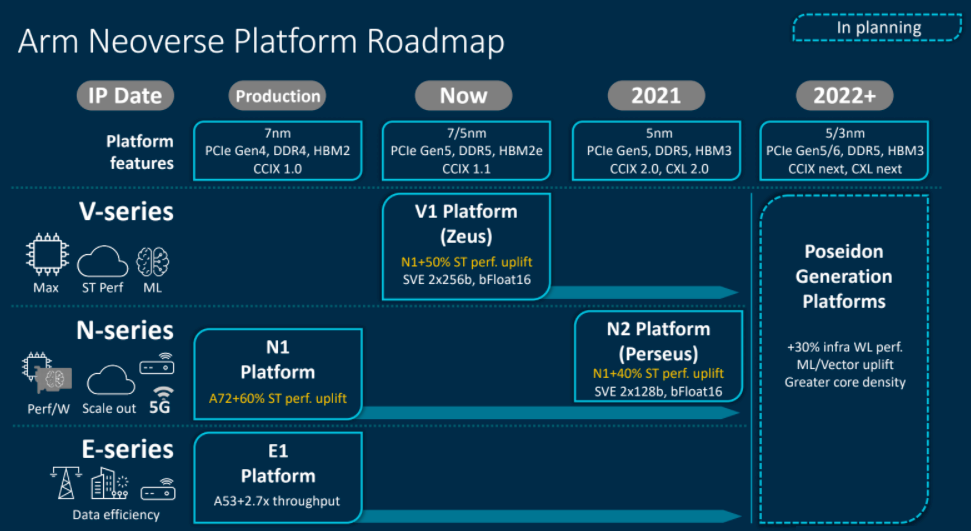
In April 2021, Arm Ltd revealed some of the details for the three distinct families of its server CPU designs, thus:
That story above got into the architectural distinctions of the “Zeus” Neoverse V1 and “Perseus” N2 cores, which we are not going to delve back into here.
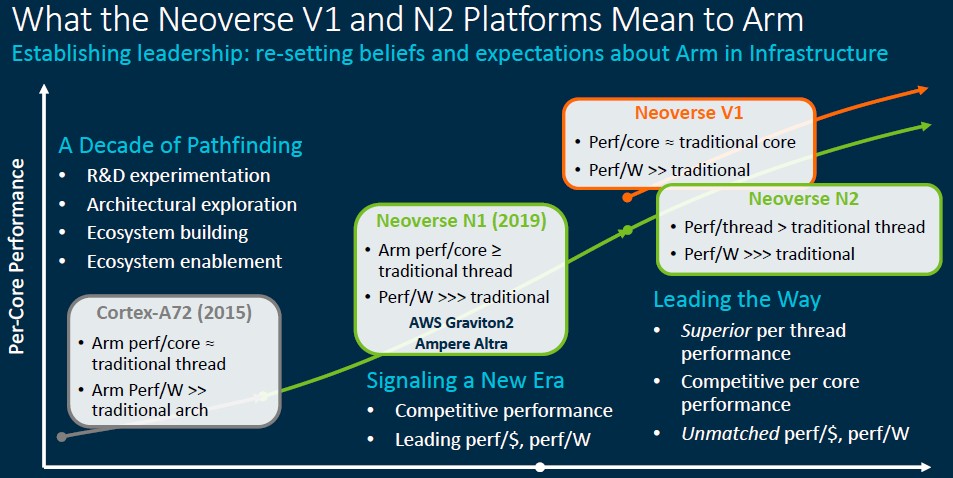
We think that the V-series cores were an afterthought sometime around late 2019 or early 2020, and one compelled by the hyperscalers and cloud builders – and probably more than a few HPC centers – to have more performance, both integer and floating point, in an Arm Ltd licensable core.
With the addition of the V-series at the high end and the E-series at the low end, Arm was not able to match its annual cadence goal for Neoverse designs, and the “Poseidon” family of chips expected in 2021 slipped out to 2023 and beyond. Which is fine. The market wasn’t ready for that cadence yet anyway. The Neoverse N1 cores had to be established by a few chip designers and used in production at reasonable volume before anyone could fully trust that the Neoverse effort could yield commercial chips.
No one is doubting that now, which is why Arm Ltd can flesh out the Neoverse roadmap with a few more core variants as well as to let everyone know it has subsequent generations in the works.
Here is the high level updated Neoverse roadmap:
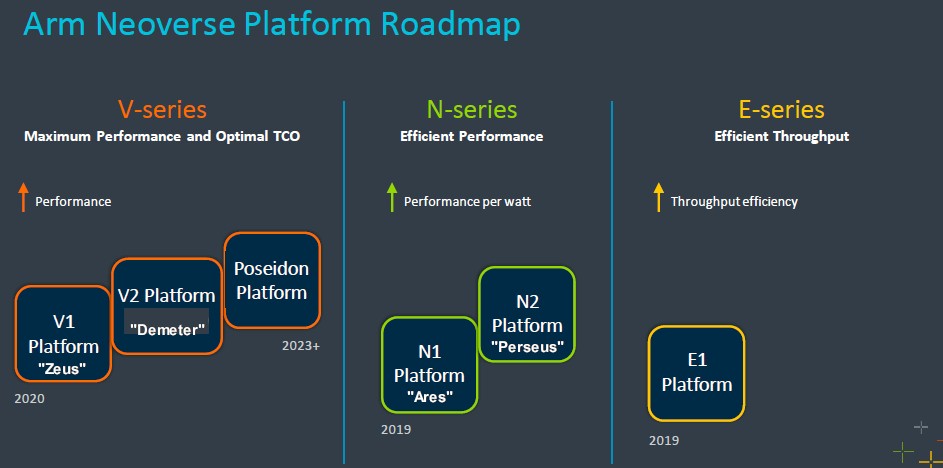
We have added codenames for the cores where we know them so you can keep track.
The new core added is the “Demeter” V2 core, and while we don’t know a lot about it, what we do know now is that it is the one that Nvidia has opted to use inside of its “Grace” Arm server CPU, which is expected to start shipping next year and which we talked about most recently after presentations that Nvidia made at the Hot Chips 34 conference last month. Nvidia was cagey about what core it was using in Grace, leading many to suspect that it had created its own core this time around as it had done with the “Denver” Arm server CPU chips that Nvidia unveiled as a future product line back in January 2011 but did not deliver for a whole bunch of complicated reasons.
This is not to say that Nvidia won’t use its Arm architectural license to create custom cores in its future Arm CPUs. Ampere Computing started out with N1 cores and is doing its own cores for future chips, while AWS started out with semicustom “Maya” Cortex-A72 cores with the Gravton1, shifted to N1 cores with Graviton2, and is using V1 cores in its new Graviton3.
Given all of the work that Arm Ltd is doing on Neoverse core designs – the different cores for three different courses – you might naturally wonder why any chip designer would create its own cores at this point.
“The beauty of the Arm ecosystem is the flexibility we offer,” Dermot O’Driscoll, vice president of product solutions for infrastructure at Arm Ltd, tells The Next Platform. “There are partners who believe that they want to take that flexibility to a level where they design their own cores. And that gives a set of heterogeneous offerings from those partners and from us. We clearly have a strong, passionate belief that Neoverse is the best in the market. But we also believe that our partners are going to bring really compelling and interesting solutions to the market, too. And the beauty of the Arm ecosystem is you have that option. As you know, there are other ecosystems where that option is not there.”
Yeah, no kidding.
Anyway, instead of “Poseidon” being a family of products, it is beginning to look like this will just be the name of what we will call the future V3 core and the platform wrapping around it.
Here is a more complete roadmap, showing three generations of V, N, and E core designs:
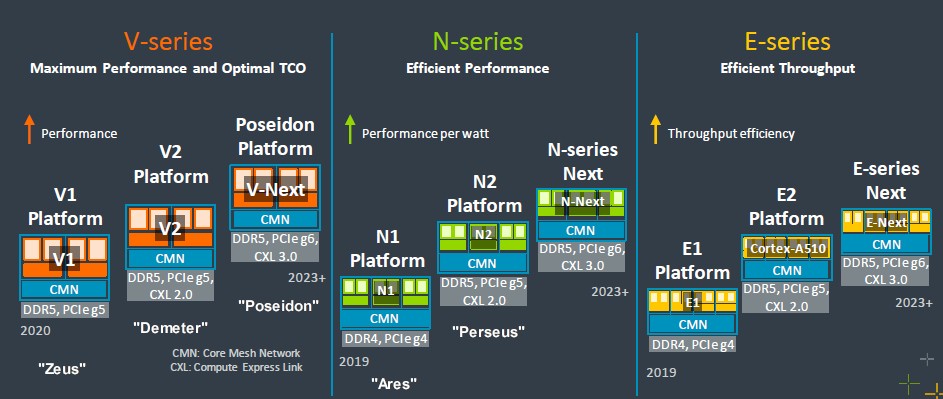
Again, we have added codenames where we know them to help you keep track and to allow us to use synonyms, which we love.
First off, why be cagey about calling the future cores V3, N3, and E3? Why not give us all of the code names? Why not make it simple for us all? These are small things, and so is the print on that chart. The important thing is that there is a plan, and that many Arm partners will be able to create server CPUs using licensable IP. We expect for a lot more players in China to do just that, in fact, and because Nvidia could not acquire Arm Ltd, the United States government can’t really do anything about that. And the British government, which wants to sell whatever it can to help with trade balances with China, won’t either.
For each Arm core series, you see the core level, a Coherent Mesh Network (CMN) that links the cores to each other and to L2 caches and other controllers and interfaces on the CPU.
The Demeter V2 core is paired with DDR5 memory and PCI-Express 5.0 peripheral controllers and will support the CXL 2.0 coherent memory protocol for accelerators, which allows for memory pooling across servers as well. The V2 core definitely supports the Armv9-A architecture previewed in March 2021, which among other things supports the second generation Scalable Vector Extension (SVE2) vector math design, which has a quad of 128-bit vectors lashed together that supports INT8 and BF16 formations as well as the usual single precision FP32 and double precision FP64 floating point math.
So that mystery about Grace, and who would be the first to bring an SVE2 engine to market, is solved. It looks like it will be Nvidia, and that is probably no accident. Then again, we could see a preview of a Graviton4 chip from AWS at re:Invent 2022 based on the V2 core. . . . In fact, we expect just this. AWS could get into the field before Nvidia.
The hyperscalers and clouds are driving the Ampere Computing A1 cores, which is what we call that company’s custom cores and which it calls AmpereOne, and these same mega-buyers also appear to be driving the V2 core design at Arm Ltd:

The V2 core has 64-bit virtual memory addressing but 48-bit physical addressing, which means a complex of these cores in single socket can have up to 256 TB of physical memory attached to it. That seems like enough for now for traditional CPU use cases. But for very large shared memory pools like IBM is supporting with the Power10 chip, IBM has added enough bits to support 2 PB of physical memory per server. Crazy, right? Big Blue has its reasons, which we have contemplated as a shared memory area network that could be created using high speed NUMA interconnects as Power10 has.
The V2 core will have 64 KB of instruction L1 cache, 64 KB of L1 data cache with error correction (that last bit is new), and the option to boost the L2 cache from the 1 MB of the V1 core design to 2 MB. Arm Ltd is promising “market leading integer performance” without being specific, but we have seen the SPEC integer rate performance metrics for Grace and they are pretty good across 72 active cores at an estimated 370 on the SPECint_rate_2017 throughput test.

The CMN mesh that will be used with the V2 cores can span up to 256 cores and therefore up to 512 MB of L2 cache. That is 2X the cores and 4X the L2 memory of the V1 core, which is reasonable given that the CMN mesh has 4 TB/sec of aggregate bandwidth. The V2 platform supports DDR5 and low power DDR5 (LPDDR5) main memory, the latter of which is employed by Nvidia as main memory in the Grace CPU. The V2 platform supports PCI-Express 5.0 peripherals and can run the CXL 2.0 memory pooling protocol, but we will have to wait until PCI-Express 6.0 and the CXL 3.0 protocol to have memory sharing across CPUs linked by PCI-Express switching.
That can happen with the Poseidon V-Next core design – we are tempted to call it the “Poseidon” V3 core just to keep all of this consistent – that is expected to be released next year by Arm Ltd. Not much was said about it other than it was in the works and it supports DDR5 memory, PCI-Express 6.0 peripherals, and the CXL 3.0 protocol.
No one has said much about the Perseus N2 core, which also hews to the ARMv9-A specification like the V2 core does and which we detailed back in April 2021. Like many, and very likely Arm Ltd itself, we expected that the N-series designs, which are optimized for performance per watt, would have been sufficient and make the hyperscalers and cloud builds happy. CPUs using the N2 cores are aimed at machines with 12 cores to 36 cores and between 30 watts and 80 watts. And given the talk two and a half years ago, we did not believe the V1 core had much of a chance at the hyperscalers and cloud builders, but would see uptake for HPC systems. And then AI inference on the CPU became the driving factor in CPU design, and it sure looks like everyone doesn’t care much about the N2 core for datacenter compute and is going to the V1 and V2. The N2 core could see uptake for 5G and other networking roles as well as in DPUs. But some of that is going to be cannibalized by the E-series, which was more modest back in early 2021.
Beyond that, we know that there is a follow-on N-Next chip – call it “Triton” or “Orion” for one of the sons of Poseidon and why not just call it the N3 core on the roadmap to begin with? – in development with the same basic DDR5, PCI-Express 6.0, and CXL 3.0 feature set.
In the E-series, which is taking some of that 5G and networking jobs away from the N-series, Arm Ltd has taken the Cortex-A510 core, the kicker to the Cortex A55 and used in all kinds of client devices from watches to smartphones, and moved it into the Neoverse E-series server design to create the E2 platform, supporting the same memory and I/O features as the V2 and N2 cores and platforms and no doubt supports the Armv9-A architecture. And to be super specific, the E2 platform has the Cortex-A510 cores and the same backplane used in the N2 and V2 platforms: the CMN-700 mesh interconnect, the GIC-700 interrupt controller that does hardware virtualization, and the MMU-700 system memory management unit.
And we also know that there is an E-Next core and platform – call it E3 – slated for 2023 and beyond that is the companion to the Neoverse V3 and N3 designs.
Up next, we will talk about the prosects for the Arm’d insurrection in the datacenter, which was the other topic of conversation with Arm Ltd at its briefings today.

To my understanding, the US government couldn’t have stopped Arm from selling IP to China even if Nvidia had acquired Arm. IP has an origin. Part of the Arm deal was the willingness of Nvidia to maintain Arm’s work in the UK. For example, the US does have control over the export of ASML’s EUV machines because they use Cymer light sources which were developed in the US. It doesn’t matter that ASML, a Dutch company, bought Cymer. Cymer still does its work in the US and the Cymer IP has a US origin. I’m sure these things can get caught up in legal tanglings where some government sues to establish that a property actually has significant input from some country, and it is probably a bigger risk for some part of ARM to eventually have US origin if Nvidia owned Arm. But Arm, to my understanding, would not have suddenly come under control of US export restrictions if Nvidia had bought it.
Nice! It’ll be interesting to see how Grace (Neoverse V2, 72 cores, ARMv9, SVE2, LPDDR5) compares to A64FX (ARMv8.2, 48 cores, SVE, HBM2) in performance and efficiency, and in particular how Grace-Grace (Fugaku-style with no accelerator) and Grace-Hopper systems compare to each other (keeping in mind that A64FX has 2x512b SVEs, rather than 4x128b).
I agree. We look forward to such comparisons.