

Some details are emerging on Europe’s first exascale system, codenamed “Jupiter” and to be installed at the Jülich Supercomputing Center in Germany in 2024. There has been a lot of speculation about what Jupiter will include for its compute engines and networking and who will build and maintain the system. We now know some of this and can infer some more from the statements that were made by the organizations participating in the Jupiter effort.
In June 2022, the Forschungszentrum Jülich in Germany, which has played host to many supercomputers since it was founded in 1987, was chosen to host the first of three European exascale-class supercomputers to be funded through the EuroHPC Joint Undertaking and through the European national and state governments countries who are essentially paying to make sure these HPC and AI clusters are where they want them. With Germany having the largest economy in Europe and being a heavy user of HPC thanks to its manufacturing focus, Jülich was the obvious place to park the first machine in Europe to break the exaflops barrier.
That barrier is as much an economic one as it is a technical one. The six-year budget for Jupiter weighs in at €500 million, which is around $526.1 million at current exchange rates between the US dollar and the European euro. That is in the same ballpark price as what the “Frontier” exascale machine at Oak Ridge National Laboratory and the “El Capitan” machine that is being installed right now at Lawrence Livermore National Laboratory – both of which are based on a combination of AMD CPUs and GPUs and Hewlett Packard Enterprise’s Slingshot variant of Ethernet with HPE as the prime contractor.
Everybody knows that Jupiter was going to use SiPearl’s first generation Arm processor based on the Neoverse “Zeus” V1 core from Arm Ltd, which is codenamed “Rhea” by SiPearl and which is appropriate since Zeus and Jupiter are the same god of sky, thunder, and lightning – the Greek “Zeus Pater” with a Celtic accent becomes “Jupiter”. Rhea, of course, is the wife of Cronos and the mother of Zeus in the Greek and therefore Roman mythology. It is a pity that the French semiconductor startup could not do a design based on the Neoverse “Demeter” V2 core – the one that Nvidia is using in its “Grace” Arm server CPU. But frankly, the CPU host is not as important as the GPU accelerators when it comes to vector and matrix math oomph. To be sure, the vector performance of the CPU host is important for all-CPU applications that haven’t been ported to accelerators or can’t easily or economically be ported to GPUs or other kinds of accelerators, and there is every indication that the Rhea1 chips will be able to do these jobs better than existing supercomputers at Jülich. We shall see when more feeds and speeds of the system are announced at the upcoming SC23 supercomputing conference in Denver next month.
The word on the street is that the 1 exaflops figure that the EuroHPC project and that Jülich has talked about when referring to the Jupiter system is a metric gauging the High Performance Linpack (HPL) benchmark performance on this system, and that allows us to do some rough math on how many accelerators might be in the Jupiter machine and what the peak theoretical performance of the Jupiter machine might be.
Back in June last year, we did not think that Jülich was going to be using Intel’s “Ponte Vecchio” Max Series GPUs in Jupiter, although there may be a partition for a few dozen of these devices in there just to give Intel something to talk about. And the reason is simple: The Intel GPUs burn a lot more power than AMD and Nvidia alternatives for a given performance. We also did not think Jülich would be able to get its hands on enough of AMD’s “Antares” Instinct MI300X or MI300A GPU accelerators to build an exaflops-class system, but again, we think there will probably be a partition inside Jupiter based on AMD GPUs so researchers can do bakeoffs between architectures.
This week, EuroHPC confirmed that Nvidia was supplying the accelerators for the GPU Booster modules that will account for the bulk of the computational power in the Jupiter system.
As was the case with the LUMI pre-exascale system at CSC Finland, EuroHPC is taking a modular approach to the Jupiter system, as you can see below:

The Universal Cluster at the heart of the system is the one based on the SiPearl Rhea1 CPUs, which is also known as the Cluster Module in the EuroHPC presentations. No details were given about what Nvidia technology would be deployed in the Booster Module. We walked through the possible scenarios to get to 1 exaflops in our June 2022 coverage, and just for the heck of it we are going to guess that EuroHPC will make the right price/performance and the right thermal choice and employ the PCI-Express versions of the “Hopper” H100 GPUs – not the SXM5 versions on the HGX motherboards that have NVSwitch interconnects to provide NUMA memory sharing across the GPUs inside of a server node.
To get 1 exaflops sustained Linpack performance, we think it might take 60,000 H100 PCI-Express H100s, which would have a peak theoretical FP64 performance of around 1.56 exaflops; on FP16 processing for AI on the tensor cores, such a machine would be rated at 45.4 exaflops. All of these numbers seem impossibly large, but that is how the math works out. Moving the SXM versions of the H100 would double the watts but only boost the FP64 vector performance per GPU by 30.8 percent, from 26 teraflops to 34 teraflops in the most recent incarnations of the H100 (which are a bit faster than they were when announced in the summer of 2022). Moving from 350 watts to 750 watts to get tighter memory coupling and a little less than third more performance is a bad trade for an energy-conscious European exascale system.
We strongly suspect that InfiniBand interconnect will be used in the Jupiter system, but nothing has been said about this. In the prior generation Juwels supercomputer, the Booster Module had a pair of AMD “Rome” Epyc 7402 processors that linked through a PCI-Express switch to a quad of Nvidia A100 GPUs with NVLink3 ports cross-coupled to each other without NVSwitch interconnects, like this:
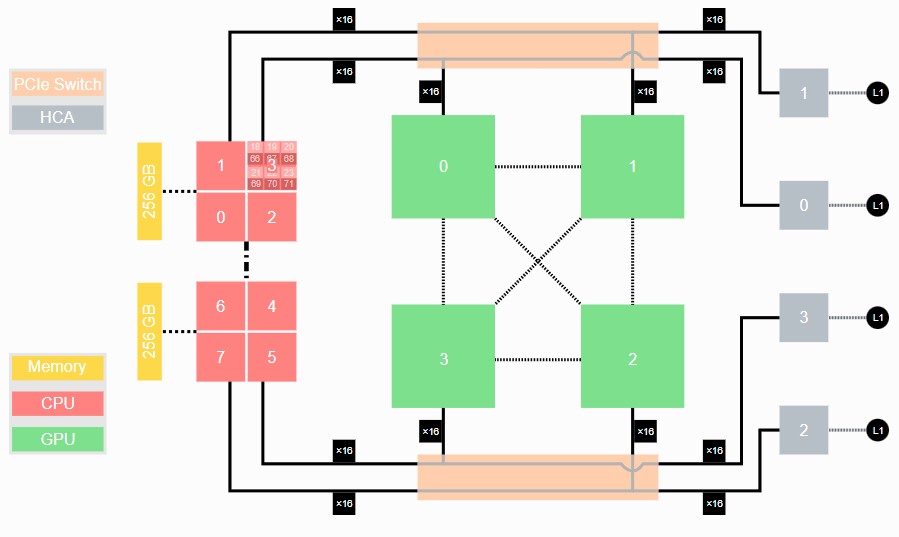
Each Rome Epyc processor had 24 cores and with SMT-2 threading turned on presented a total of 96 threads to the Linux operating system. The Juwels node had 512 GB of memory, which is pretty hefty for an HPC node but not for a GPU accelerator node. The four “Ampere” A100 GPUs had 40 GB of HBM2e memory each, for a total of 160 GB. On the right side of the block diagram, you see a quad of ConnectX-6 network interfaces from Nvidia, which provided four 200 Gb/sec InfiniBand ports into and out of the Booster Module. There are two PCI-Express 4.0 switches to link the GPUs to the InfiniBand NICs and to the CPUs.
It is highly likely that the Jupiter Booster Module will be an upgraded version of this setup. A Rhea1 processor could replace the AMD processor to start, and the Booster Modules could also be equipped with Nvidia Grace CPUs. Given that memory prices have come down, the Jupiter Booster Module will probably have 1 TB of memory, which probably means it is not a Grace GPU. It seems logical that a pair of PCI-Express 5.0 switches from Broadcom or Microchip will be used to link the CPU to the GPUs and both to the network. The PCI-Express version of Hopper H100 GPU has three NVLink 4 ports, so they can be cross coupled in a quad without an NVSwitch in the middle.
The GPU performance in the Jupiter Booster Module would be 3X to 6X that of the existing one in Juwels (depending on sparsity and whether you are doing math on the vector or tensor cores). The GPU HBM3 memory would be 2X higher and the GPU memory bandwidth inside the booster, at 9.4 TB/sec, would be 1.6X that of the A100 quad. It seems obvious that Jupiter would use a hierarchy of 400 Gb/sec Quantum 2 InfiniBand switches to link this all together. At 60,000 GPUs, we are talking about 15,000 nodes just for the Booster Modules in Jupiter. There will probably be a couple of tens of petaflops across the Cluster Modules in the CPU-only partitions.
There is also a chance that Jupiter is based on the next-gen “Blackwell” GPUs, which could be a doubled-up GPU compared to the Hopper H100s with a much lower price and much fewer of them. So maybe it is more like 8,000 nodes with a Blackwell, which works out to 32,000 GPUs. We expect for Blackwell to be Nvidia’s first chiplet architecture, and that would help drive the cost down as well as the number of units required.
These are, of course, just guesses.
Here is how this conjectured Jupiter machine might stack up to other big AI/HPC systems we have seen built in the past couple of months and its exascale peers in the United States:
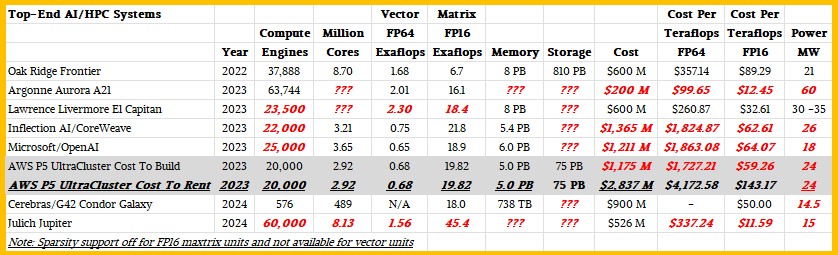
As you can see, Jupiter can compete with Frontier in terms of FP64 price/performance, but will not beat El Capitan and none of them come close to the artificially lowered price of Aurora given the $300 million writeoff Intel took against the deal with Argonne.
Everyone suspected that the Eviden HPC division of Atos would be the prime contractor on the Jupiter deal, and indeed this has come to pass. The compute elements will be installed in the liquid-cooled BullSequana XH3000 system, which we detailed here back in February 2022. German supercomputing and quantum computing vendor ParTec is supplying the ParaStation Modulo operating system, which is a custom Linux platform with an MPI stack and other cluster management and system monitoring tools all integrated together.
EuroHPC says in a statement that the cost of building, delivering, installing, and maintaining the Jupiter machine is €273 million ($287.3 million), and presumably the remaining part of that €500 million is to build or retrofit a datacenter for Jupiter and pay for power and cooling for the machine. Electricity is three times as expensive in Germany as it is in the United States, and over six years, a 15 megawatt machine could easily eat the lion’s share of the rest of that budget. Yeah, it’s crazy.
By the way: We are well aware that at a current street price of around $25,000 to $30,000 a pop for an H100 in the PCI-Express I/O variant that just the cost of 60,000 GPUs would add up to $1.5 billion to $1.8 billion. Something doesn’t add up. Maybe EuropeHPC was able to swing a killer pricing deal before the pricing on H100s popped? We still think it is more likely that Jupiter has 32,000 of the future Blackwell B100 GPU accelerators, which we expect to have close to twice the oomph of Hopper after a 3 nanometer process shrink and perhaps four GPU chiplets on a socket.
Installation of the Jupiter system will start at Jülich in the beginning of 2024. It is unclear when it will be finished, but it will almost certainly make the June or November Top500 supercomputing rankings next year. We look forward to seeing what this machine looks like, inside and out. It is likely that the CPU nodes will go in first, and that the GPU nodes will come later. We think maybe the November list, depending on when Blackwell is available in volume.




Holy Moly of EuroHPC Guacamole! Strategic planning for the TNP full-court press raid on SC23 just turned itself into a genuine quantum AI “traveling salesman” baking challenge (TNP 09/21/23)! Will the mother of Zeus of HPC gastronauts, and its not-to-be-missed tasty hot sauce, be covered here(?):
European HPC Ecosystem – Updates and Gap Analysis ( https://sc23.supercomputing.org/presentation/?id=bof109&sess=sess398 )
and will the merry melodies of future roadrunner acceleration be played through Spanish inquisition minds, way over here(?):
European RISC-V HPC and AI Pre-Exascale Accelerators ( https://sc23.supercomputing.org/presentation/?id=bof213&sess=sess355 )
Associated logistics boggle the mind! Here’s to hoping for a centrally positioned locus for 12-bar slide-guitar and banjo socialization (TNP-style!), some chillaxization, and a way to satisfy those munchies!
EuroHPC (or maybe SiPearl) could be a bit more transparent (in my mind) about when Rhea1 taped-out, and when engineering samples became available, and what sort of qualification it went through, with associated performance. These processes take time and it is not 100% clear whether or when they occured since “Money Change[d] Everything For SiPearl” in April ’23 ( https://www.nextplatform.com/2023/04/05/money-changes-everything-for-sipearl/ ). Was the design so outstandingly outstanding that first bake produced a perfect instantiation?
The chip being central to JUPITER (Joint Undertaking Pioneer for Innovative and Transformative Exascale Research), such info would be quite crucial to give armchair analysts (eg. a random TNP reader) a much better perspective for assessing whether the “beginning of 2024” for “Installation of the Jupiter system” is realistically technically feasible, or mostly optimistically optimisic.
Feeds and speeds are key to effective HPC gastronomy … as Macaron le glouton Cookie Monster (from UMCP alumni Jim Henson) would say: Me want cookie! Om nom nom nom!
Since RIKEN’s Fugaku is about 15 percent faster on HPCG than Frontier, it would seem unwise to make design decisions based only on Linpack.
The question in my mind is how does the cache and memory bandwidth look for those SiPearl Rhea1 ARM processors?
Along similar lines, the statement “Moving from 350 watts to 750 watts to get tighter memory coupling and a little less than third more performance” assumes there actually is some universal measure of performance. Maybe a 30 percent performance boost in HPL translates into a two or three times increase on a more relevant computation for which memory bandwidth is important.
I like HPCG too. I think that it is more relevant to FEM and FDM workloads than HPL. Sparse data access performance is also likely nicely represented by Graph500, which is useful (at least) for high-performance symbolic computations (the non-silly type of AI). It’d be nice if there were a HPCG-MxP benchmark (HPL-MxP is at the bottom of the HPCG page on top500.org), but maybe mixed-precision doesn’t work all that well with preconditioned iterative methods (???).
Keshav Pingali is going to receive the ACM-IEEE CS Ken Kennedy Award at SC23 Denver ( https://awards.acm.org/kennedy ) for his work on parallelism of irregular algorithms involving sparse matrices and graphs (increasingly relevant today). I’m going to try and read his 2011 paper on “The Tao of Parallelism in Algorithms” (a classic) as an axonal decongestant — hopefully it works!
Even with Blackwell GPUs, I can’t make the numbers work. They’d need to get blackwells at under $10,000ea. Maybe Nvidia signed up for a big bulk deal like that, but I doubt it. Are they worried about the optics of AMD winning all the big HPC systems? It’s about the only place AMD GPUs are winning in the datacenter. You’d think nvidia would just walk away with all the AI money laughing.
I know. Right?
Great analysis! I hadn’t picked up on the Blackwell possibility but it seems to make good sense nodewise. This Jupiter being quite disaggregated (split of CPU and GPU modules) should be a challenge for both performance and power consumption (compared to systems with MI300A and GH200). Maybe the BSC’s accelerators will get to be tightly integrated in the upcoming Jules Verne Euro/French Exaflopper (see note: [*] below)?
It was sharp-eyed tech journalism (TNP-style!) to specify that this machine will use Rhea1 (or Rhea 1), as the chip will see future updates. The Roadmap slide in TNP’s “Money Changes Everything” article, and a French website, concur (essentially) that Rhea1 would be those 64 cores etched in TSMC 6nm, while Rhea2 (or Rhea 2, Cronos?, 2024?) would be 96 cores in 5 nm, and Rhea3 at least 128 cores in 2 or 3 nm (2026?) ( https://www.nextinpact.com/article/70372/cpu-et-supercalculateurs-europeens-sipearl-multiplie-partenariats-avec-amd-graphcore-intel-nvidia ). It’ll be great to follow those developments!
Meanwhile, at SC23, Fujitsu will exhibit Monaka, its A64FX kicker, with the goal of 10 times the power performance of that Fugaku chip. Something to see I think, especially as power efficiency was the machine’s Achilles’ heel relative to Frontier ( https://sc23.supercomputing.org/presentation/?id=exforum111&sess=sess252 ).
The international HPC Battle Royale of the Super Exafloppers may not quite be for this year … but it is great to see that things are heating up, for an eventful 2024 (or ’25), in that space!
[*] Note: The Jules Verne supercomputer can not, in any way shape or form, ever be installed in the currently targeted southern suburb of Paris! That city is already overcrowded with administrative, tech, and cultural hotspots, and an impossibility to navigate via any means of contemporary transportation. You can’t cross Paris from North to South or East to West more than twice in one day — it just takes that long. It also gets extremely hot in the summer and is not a proper environment for a supercomputer. Neither Blaise Pascal nor René Descartes, if they knew of the situation, would ever agree to placing a super there. It is a noisy and polluted environment whose location would only further contribute to the unequitable, protest-generating, hyper-centralization of the French State.
The only logical location for the Jules Verne Super (named after the world-famous author born in Amiens in 1905) is the “Hauts-de-France”, and particularly the close vicinity of Ablaincourt-Pressoir and Estrées-Deniécourt, where the “gare TGV Haute-Picardie” (and its high-tech industrial park) is already located. This location is mid-way between Amiens and Saint-Quentin, and mid-way between Paris and Lille, on the line that continues through to Brussels. It is also perfect for access to the Roissy Charles-de-Gaulle international airport (which is in the North of Paris). Unlike the South of Paris (that quickly extends to Bordeaux, Toulouse, and Barcelona), there are no Supercomputers in the Hauts-de-France, and plenty of room, quietness, cooling potential, available green energy, and easy transportation. Placing Jules Verne anywhere else in France would be a crime of insult against the human intellect, not a “lèse-majesté” but a “lèse-peuple”!
Exactly! The Hauts-de-France, and particularly Picardie, is the French equivalent of Asheville NC for the high-tech datacenter and HPC future of the Paris-Amsterdam corridor, not to mention Hamburg and Copenhagen!
We are the land of Clovis, of the “vase de Soissons”, of Anne Morgan ( https://museefrancoamericain.fr/en/anne-morgan-and-world-war-i-1917-1924 ), of the Maroilles cheese, and of the Buironfosse “Musée du Sabot” (wooden shoe; think Flanders, and also “sabotage”; http://www.musee-du-sabot.com/ ). We are where François Ier made the French language official, and we are not only the original “sans dents” (eg. Deliverance), but also the place where the world-famous Charlemagne, Condorcet, Dumas, LaFontaine, Matisse, Racine, and Verne were born (among others). Unsurprisingly, a good chunk of Hugo’s Les Misérables took place right here (eg. Arras).
There is plenty of space in the Hauts-de-France, great transportation (TGV, Canal Seine-Nord Europe, CDG airport), much more water than in the drying-out South, and wind power is everywhere! And it’s a straight shot to Amsterdam’s SURF, the Dutch partner on the Jules Verne Exaflopping Supercomputer; much, much, much more accessible than Bruyères-le-Châtel!
BTW, that’s that very same TGV train line (LGV Nord, Eurostar) that goes to London’s St-Pancreas through the Chunnel, as featured in the highly-technical 1996 Tom Cruise documentary “Mission: Impossible”! 8^P
German can be so scary! Forschungszentrum Jülich — shakin’ in me boots! But, Forschung = research, zentrum = center, and so Jupiter will be kindly installed at the Jülich research center … much more reasonable!
When, in 1855, Adolf Fick adapted Joseph Fourier’s 1822 theory of heat diffusion, to describe the diffusion of dissolved substances, He referred to Fourier’s work as dealing with “warmstrom” … arrrgh, warmstorm, scary! But, warm = warm, heat, and strom = current, flux, so he was making an analogy to Fourier’s approach to the heat flux … very thoughtful (easiest language to learn, ahem!)!
Speaking of the German language; want to know the unrevealed hidden mysterious secret truths about Sam Altman, Andy Feldman, Mark Zuckerberg, Albert Einstein, and Benoit Mandelbort? Read on!
German is basically a glued-up version of English, where pairs of words (or more) are frequently concatenated. Some words are exactly the same (barbarian languages of the vandals, as opposed to civilized Latin):
ein = one, zwei = two, drei = three, alt = old, jahr = year
gut = good, besser = better, warm = warm
wasser = water, eis = ice, strom = stream, fluss = flow
feld = field, stein = stone, haus = house, zentrum = center
stern = star, volks = folks, wagen = wagon, auto = auto
brot = bread, zucker = sugar, creme = cream, sauerkraut = sauerkraut
montag = monday, freitag = friday
Others are slightly different:
berg = mountain, eisen = iron, klein = small, schön = beautiful
bahn = way, mandel = almond, tag = day
And there you have it, their deepest secrets finally revealed: 8^p
Sam Altman = Sam Old Man (doesn’t look his age!)
Andy Feldman = Andy Field Man (very hard working!)
Mark Zuckerberg = Mark Sugar Mountain (very sweet!)
Albert Einstein = Albert One Stone (keystone of modern physics!)
Benoit Mandelbrot = Benoit Almond Bread (deliciously fractal!)
Speaking of ARM chippery, here is my (partial) Saturday evening list of ARM-based Supers:
Existing: Fugaku…….. A64FX
Existing: Tianhe-3…… Phytium 2000 + Matrix 2000
Existing: Wuhan Super… Kunpeng 920 + A100
Existing: Cloudbrain-II. Kunpeng 920 + Ascend 910,
Imminent: Venado…….. GH200
Imminent: Piz Daint-Nxt. GH200
Upcoming: Jupiter……. Rhea 1 + Nvidia GPU
Upcoming: Fugaku-Nxt…. Monaka
The Wuhan Super is quite close to #1 Fugaku on graph500, and both realize 4x as many Traversed Edges Per Second (TEPS, GTEPS) as #3 Frontier ( https://graph500.org/ ).
For cloudy HPC (if that floats your ALUs), my partial Sunday evening list for ARM is:
AWS. . . . . . Graviton3E (V1)
Alibaba ECS. . Yitian 710 (N2)
Google . . . . Ampere Altra (N1)
Microsoft. . . Ampere Altra (N1)
Oracle . . . . Ampere Altra (N1)
Some cloudy Huawei Kunpengs should probably be in there too.
A couple more ARM HPC Supers (from Europe), from my Monday evening list:
Existing: Deucalion________Portugal_______A64FX______10 PF/s
Upcoming: Isambard 3_______Bristol, UK____2xGrace_____3 PF/s
Upcoming: MareNostrum 5____BSC, Spain_____GH200_____163 PF/s
Unfortunate Thursday evening correction: MN5’s ARM partiion (partition 3) is not 163 PF/s (that’s partitions 1 & 2 that have SR and SR+H100; also, partition 4 may be a RISC-V roadrunner MEEP+ACME accelerator), so, from TNP and BSC sources below:
Upcoming: MareNostrum 5____BSC, Spain_____2xGrace_____2 PF/s
BSC source: https://www.bsc.es/marenostrum/marenostrum-5
TNP source: https://www.nextplatform.com/2022/06/16/atos-wins-marenostrum-5-deal-at-barcelona-supercomputing-center/