
Arm is hosting its annual Tech Day shindig, virtually (again) thanks to the coronavirus pandemic, and is providing a lot more insight into the future Neoverse core and processor designs that will be adopted and modified by those who have a hankering to take on the hegemony of the X86 processor – which now includes pretty solid CPUs from Intel and AMD – in the datacenter and at the edge.
The revelation of the details of the future Neoverse server architectures, meshed with the future Armv9-A architecture that was unveiled a month ago and that will make its debut in the Neoverse “Perseus” N2 cores, comes at a pivotal time. Despite many Arm server chip suppliers leaving the field, Arm Holdings has hung in there and there appears to be momentum building for an Arm alternative from multiple chip designers and suppliers who will individually play to particular subsets of the datacenter and edge, but collectively give Intel – and therefore AMD, too – plenty of grief.
Like the Neoverse N2 core, the design of which is done and licensable from Arm Holdings, the “Zeus” V1 core is also done and provides significant differentiation within the Neoverse family of designs and with all manner of CPUs in the datacenter and at the edge. In fact, while we don’t know it yet, at some point late this year and early next year, we should see more than a few processors that are based on the Zeus and Perseus platforms that Arm Holdings has created to demonstrate the totality of its technology and to give actual chip makers a head start on designing their own chippery. At Tech Day, the hardware engineers in charge of these Neoverse designs were able to talk more deeply about the architecture of V1 and N2 and also provide some insight into expected performance of chips based on the Zeus and Perseus cores and the technology that Arm wraps around them to create an SoC.
We will get into the performance and the prospects for Arm in the server space, separately. For now, we are just going to dive into the V1 and N2 architectures. Here is a recap of the original Neoverse platform roadmap to start:
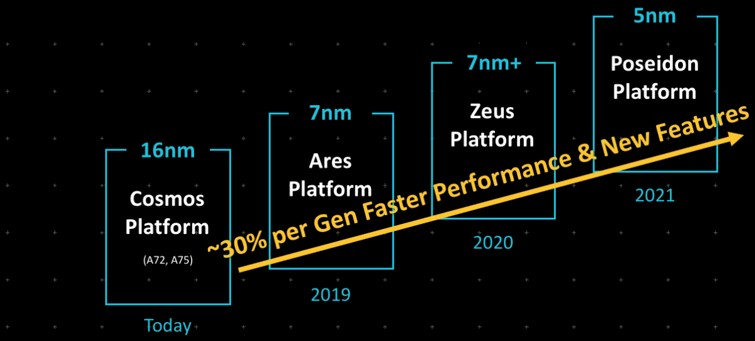
Way back when the Neoverse idea started in October 2018, Arm wanted to have a dedicated set of intellectual property aimed at servers specifically and there was only the “Cosmos” N0 (really Cortex-A72 and Cortex-A75) designs in 16 nanometers, “Ares” N1 in 7 nanometers in 2019, the “Zeus” N2 in enhanced 7 nanometers in 2020, and the “Poseidon” N3 in 5 nanometers in 2021.
Every year, Arm said, it could deliver designs with around 30 percent better performance, which partners could in turn tap to create an annual cadence in their own server roadmaps.
That annual cadence has proved tricky, and the market has trifurcated into core datacenter (N-Series), edge compute, (E-Series), and very high performance (V-Series) cores. It looks like what was going to be Zeus N2 was rebranded Perseus N2 and then the V1 high performance chip was added with a lot more muscle and given the old Zeus code-name. The good news is that the performance jumps are getting bigger – which they have to if the time is stretching out. Otherwise, value for dollar increases as we move into the future – stop. Which is bad.
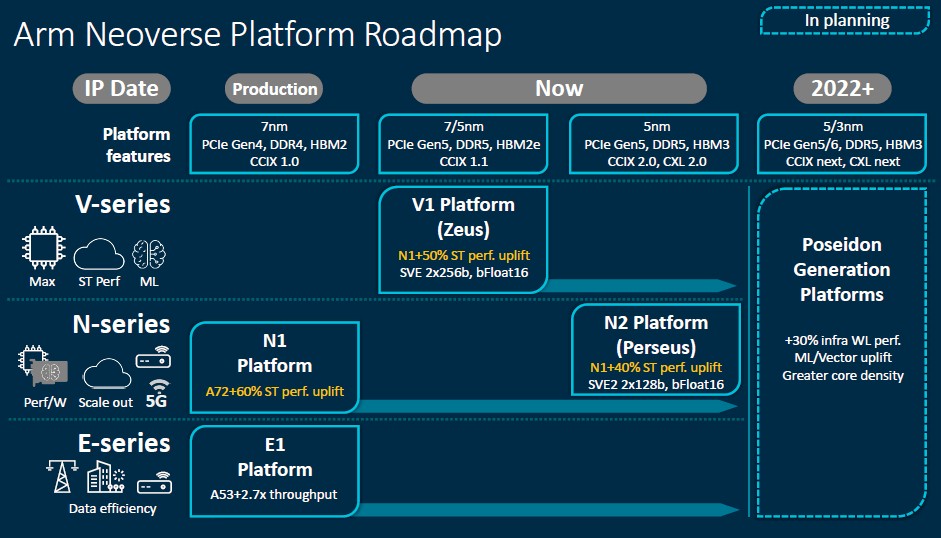
Last September, when Arm trotted out the Neoverse V1 design and made it available, the N2 design was not yet available. But as of this announcement, today, it is. Both the Ampere Computing Altra and the Amazon Web Services Graviton2 processors, which are the two production-grade Arm server chips in the market today, are based on N1 cores and platform designs, with various customizations. So when this chart says production, that’s what it means – some licensee is using it in production and it is being manufactured and either sold or used, depending. The N1 designs supported regular DDR4 memory or HBM2 stacked memory as well as PCI-Express 4.0 peripheral controllers and CCIX 1.0 interconnects for accelerators and to provide NUMA shared memory across processors. CCIX is one of many interconnects, in this case launched by Xilinx in May 2016 to provide cache coherent memory sharing between CPUs and accelerators. Arm was there with CCIX from the beginning and has been using it as a CPU interconnect, much as AMD has Infinity Fabric (either a superset of PCI-Express or a subset of HyperTransport, depending on how you want to look at it). The asymmetric memory model of Intel’s CXL has taken hold for accelerators, and runs atop the PCI-Express 5.0 transport and is being adopted almost universally by CPU makers going forward. But this will not be for NUMA links, just for various kinds of storage and compute accelerators.
With the V1 platform, Arm is designing cores and the uncore regions of a hypothetical processor using either 7 nanometer or 5 nanometer processes, presumably either at Taiwan Semiconductor Manufacturing Corp or Samsung Electronics, which have fabs that can handle either. Intel, which has merchant foundry aspirations, could eventually get there. As could SMIC, the Chinese foundry, which launched its 7 nanometer efforts last fall. No other foundries in the world are doing 7 nanometer research or manufacturing. And 5 nanometer is going to be for the elite only. We shall see just how real 3 nanometer processes are, and after that, well. . . .
Which just does to show you that chip architecture is going to matter more than ever, we suppose.
Before we dive into the nitty gritty, Arm put together some good charts that show the differentiation between the different cores in the Neoverse platform. This one is interesting:
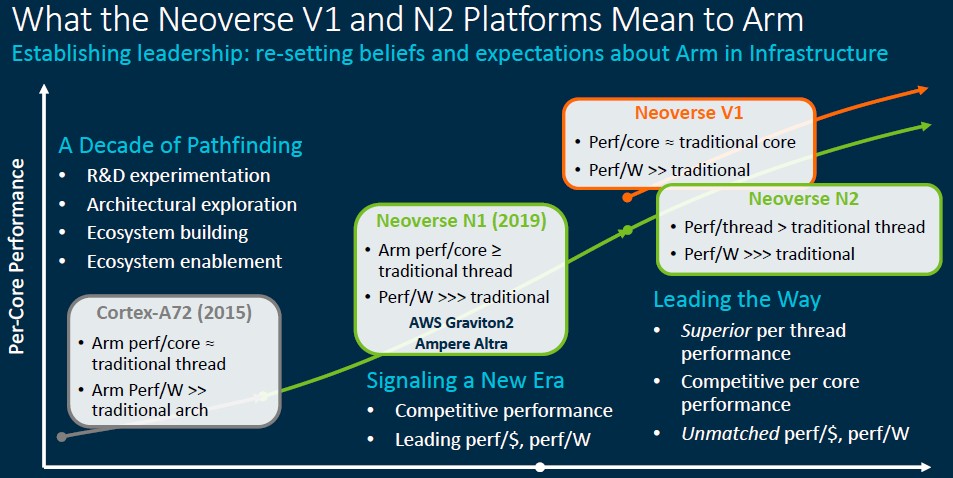
And here is another that shows the position of the E-Series, N-Series, and V-Series across different thermal ranges, core counts, and use cases:
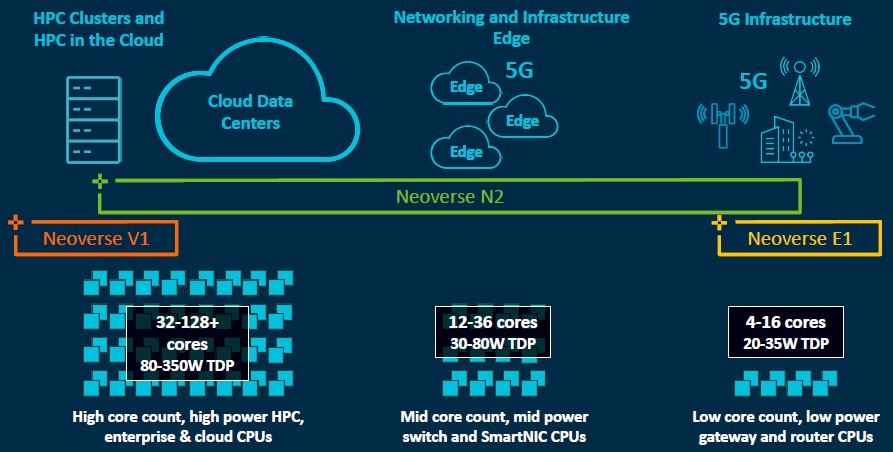
This differentiation is not new, really. Arm was talking about different kinds of design SKUs with the Neoverse N1 designs three years ago aimed at edge and various datacenter compute workloads. It is just being done explicitly with three different chip families so some of the core and uncore work that Arm licensees making server chips for specific markets no longer have to do.
Drilling Into The V1
The V1 core is going to push the limits of core counts, clock speeds, and operations per second as the throughput engine. Everything is turned up to 11, and not because Arm wants to show off, but because some customers running search engines, machine learning training and inference, HPC simulation and modeling, and data analytics workloads need a monster to chew on their data. Also, the big public clouds want to have a big instance that they can carve into little instances but, importantly, also sell as one big, wonking, expensive instance to those who need it to run, say, the SAP HANA in-memory database in the cloud.
The Zeus V1 core is providing 50 percent better single-threaded performance on integer workloads compared to the Ares N1 core, which is better than the 30 percent average per generation that Arm was promising. The V1 design has the Armv8-A implementation of the SVE vector engine, and in this case will support a pair of 256-bit wide vectors that can do Bfloat16 as well as a mix of floating point and integer operations in parallel. This will essentially match the AVX-512 vector unit in each Intel Xeon SP core for years and the pair of 256-bit FMA units in the AMD “Milan” Epyc 7003 core.
Here is a tidy little chart that explains the differences in the vector units used in the N1, V1, and N2 cores:
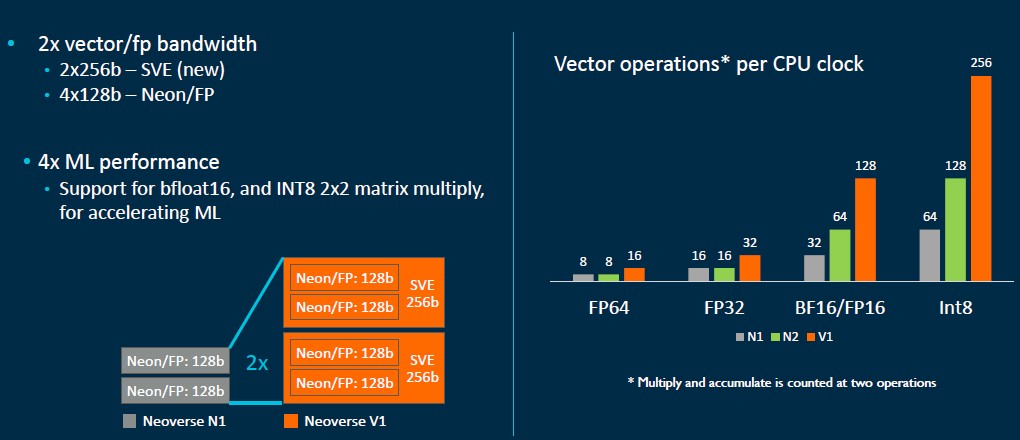
Those wide vectors in the V1 cores are not quite as parallel as a GPU accelerator, but they run considerably faster and the performance delta is not as small as you might think. Slap some HBM2 memory on a V1 chip and it should run like a bat out of hell – the A64FX Arm chip from Fujitsu used in the “Fugaku” supercomputer proves the point. If you can get the bandwidth of GPU, something like half the compute density of a GPU, and none of the hybrid programming hassle, maybe this is a smarter – or at least easier – way to go. What seems clear is that vectorizing code is the future of performance, no matter how it gets done and on which device.
The Zeus V1 platform will support DDR5 main memory orHBM2E stacked memory for those who need high bandwidth, and supports PCI-Express 5.0 peripherals and the CCIX 1.1 protocol for accelerator and NUMA interconnects. That will put it on par, more or less depending on the ratios of these technologies, with the future “Sapphire Rapids” Xeon SPs from Intel and the “Genoa” Epyc 7004s from AMD. Chip sellers – we really can’t call them chip makers, since they use foundries and outside packagers – will have to choose very carefully between 7 nanometer and 5 nanometer processes, and we would not be surprised to see some chiplet implementations that use CCIX for chiplet interconnect and allows for either 7 nanometer or 5 nanometer cores and maybe 14 nanometer or 7 nanometer etching for the uncore regions where dropping the transistor size hurts as much as it helps because of leakage issues. It will be tough to make these calls, given the huge demand for chips and the limited capacity for either 7 nanometer or 5 nanometer manufacturing.
The Zeus V1 is technically hewing to the Armv8.4 ISA and AMBA CHI.D on-chip interconnect specs, which means it supports the SVE vectors. In fact, this is Arm’s first homegrown SVE implementation, and it supports running the pair of 256-bit SVE units as a quad of 128-bit NEON accelerators, which is good for those who tuned applications to run on Arm GPU accelerators. The V1 core has enhanced nested virtualization, memory partitioning, and cryptography as well as numerous reliability and scalability improvements. It is also pulling in deep persistence and speculation barriers from the Armv8.5 spec and Bfloat16 and Int8 processing in the SVE engines from the Armv8.6 spec. There is a lot more stuff in the V1 core than in the N1 core, for sure.
One thing that there is not is simultaneous multithreading, or SMT. Arm has taken the opinion of many of its server chip licensees that good fences make less noisy neighbors and is not threading its cores so the smallest unit of compute – the core – can be isolated for performance as well as security reasons.
A lot of what went into this design is aimed at exascale-class HPC, and it is not a coincidence that SiPearl is designing its accelerator for Europe’s first exascale machine using V1 cores.
“When we think about an exascale system, there are some design objectives that we have kept in mind in both the CMN-700 interconnect and in the core,” Brian Jeff, senior director of product management for infrastructure at Arm, tells The Next Platform. “Top of mind is performance, and this matters a lot because in these systems, often you are connected to a GPU or another accelerator that has really high capability but can often wait on single thread workloads due to Amdahl’s law. But performance is also important for the workloads that run on these machines.”
Memory and I/O bandwidth is obviously also going to be important, and so is keeping all of this in balance so no single component is waiting around a lot.
Given all of this, the V1 core is the highest performing core that Arm has ever put into the field, and the platform is going to push bandwidth limits to the hilt, too.
Here is a look at the Zeus V1 core pipeline:
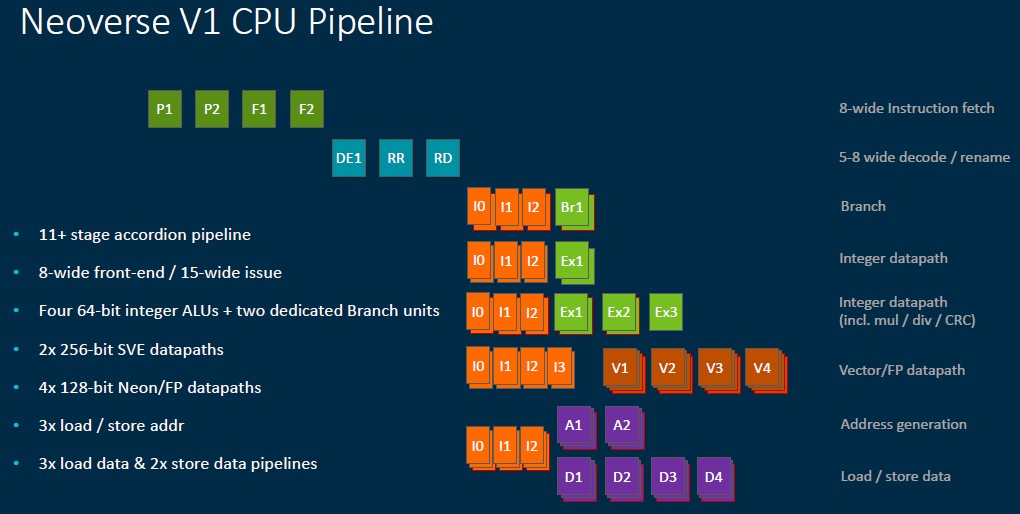
And here is the V1 core and wrap around CPU elements:

And here is a drill down into the core as well as a theoretical use of the V1 design elements in a massive chip:
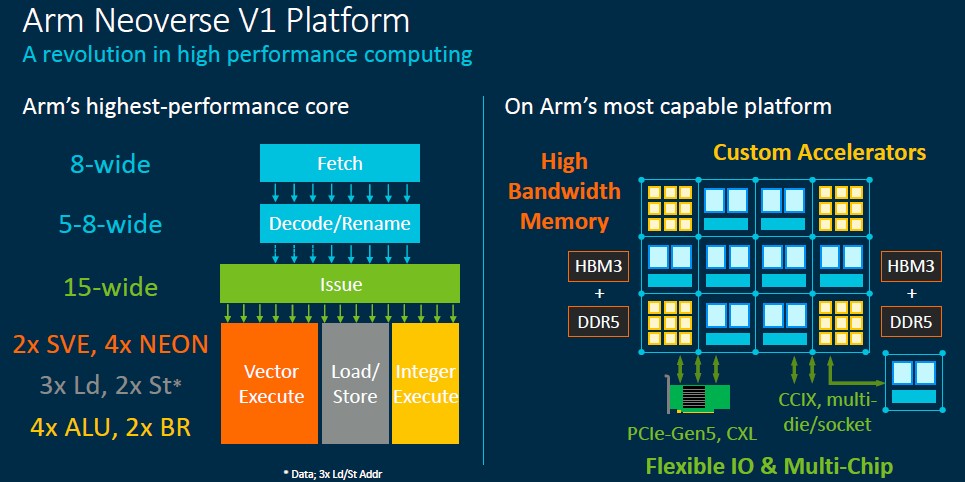
“It all starts with a really good front end,” explains Chris Abernathy, a distinguished engineer who works on cores at Arm’s Central Engineering division. “The V1 branch predictor, like that in the N1 core, are decoupled from instruction fetch, which allows for branch prediction to run ahead and prefetch instructions into the L1 instruction cache. This is a very important feature of our microarchitecture. And with an eye towards improving performance on benchmarks as well as real workloads, we have widened branch prediction bandwidth.”
The branch predictor has two 32 byte flights per cycle and its branch target buffers (BTBs) are 33 percent larger at 8 KB. The idea, says Abernathy, is to capture more branches with larger instruction footprints while also lowering branch latency for tighter, smaller kernels. Other tweaks to improve branch accuracy as well as doubling the number of code regions that can be tracked, really help out with Java workloads and other applications that have large and sparse regions of code. The net result of the new V1 front end is that it has a 90 percent reduction in branch mispredicts and a 50 percent reduction in front-end stalls.
The V1 design is also pushing the limits of width and depth, according to Abernathy. The core can dispatch 8 instructions per cycle, twice that of the N1 core, and the instruction cache decode bandwidth is up by 4X to 5X per cycle. Instruction decode latency in the core was dropped by 1 cycle as well. The out of order execution window size in the V1 core is twice as large, too, which exposes more instruction parallelism for the core to juggle to stuff itself with tasks. The integer branch execution units were doubled (to two) and the arithmetic logic unit (ALU) count was boosted by 25 percent to four per core. The load/store units and buffers all got a boost, with a lot of features doubling in wide or bandwidth (or both), and the net result is that the V1 core delivers a 45 percent increase in streaming bandwidth performance over the N1 core. The L2 and L3 caches fill 15 percent faster and traffic on the cache lines is cut in half, which helps boost that memory performance.
The net result is that the V1 core has 50 percent higher instruction per core (IPC) over the N1 core at the same frequency in a 70 percent larger chip area, and if customers want to sacrifice a little performance on the clock speed they can radically reduce the thermals. We don’t expect customers buying server CPUs based on the V1 cores to do that. This is a muscle car, and it will run fast and furious. As intended.
Tearing The Hood Off The N2
That brings us to the Perseus N2 core and CPU design, which optimizes for performance per dollar and performance per watt rather than just pushing the performance limits at any cost as the V1 core and CPU does. If the V1 is a muscle car, the N2 is a crossover sport utility vehicle.
Abernathy says that the front end on the N2 core is similar to that on the V1 core, but the core will implement the Armv9-A architecture, which has all kinds of interesting security features that are, frankly, of less use for exascale computing facilities. While the V1 design is aimed at CPUs with 32 to 128 cores with a thermal envelope of between 80 watts and 350 watts, the N2 cores are aimed at mainstream infrastructure servers that might have 12 to 36 cores and run at between 30 watts and 80 watts. That is not to say that there will not be N2 chips that don’t push the core limits up and down – there will be some, at we think Ampere Computing, AWS, and possibly Nvidia will use N2 cores in some devices. (It is very unlikely that Ampere and AWS will use a V1 core in their respective Altra or Graviton chips.)
The N2 is really an upgrade to the N1, with 40 percent higher IPC at constant frequency, with around the same power draw and about the same area as the N1 but allowing a 10 percent increase in clock speed and presumably more cores and caches thanks to the shrink to 5 nanometers.
Here’s the block diagram of the N2 core:

The N2 design has a 5-wide dispatch unit and relies less on the depth and width attack to drive maximum performance that the V1 core has. The performance features in the N2 design have to “pay for themselves” in power efficiency and area efficiency, as Abernathy put it, compared to the N1, and this is really more of an optimization of the N1 with the new Armv9-A architecture and the V1 front-end grafted onto it. Think of that branch prediction like fuel injection and the V1 having a lot more cylinders than the N2 and also having more fuel injectors. One is made to run drag races where the fuel bill is not important but time to the finish line is, and the other to make long trips on vacation without spending more money on gas than you do on cheap hotels. If your dad even stops. Which he doesn’t. Because he is pretending that he is driving a drag racer.
The N2 core will take up 30 percent more area and burn 45 percent more power to deliver that 40 percent higher throughput, and importantly, the N2 core will be 25 percent smaller than the V1 core so you can cram more of them into a given die size. Those fat vectors and fat caches don’t come free. Nothing in CPU architecture does. And that – in addition to all of the security features in the Armv9-A architecture – is why we expect cloud builders to want N2 designs more than V1 designs. And we would not be surprised if they (or their chip partner if they are not designing their own chips as AWS and maybe Microsoft is doing) push the core limits above 128 cores using a chiplet design, again using CCIX as a chiplet interconnect and possibly breaking out an I/O and memory hub like AMD does with its Epyc X86 server CPUs.
That’s what we would do, and perhaps in a single socket design to really drive down the system cost and drive up the size of the cloud instance and the number of slices you can carve it into.
Here is the N2 reference design that Abernathy showed off:
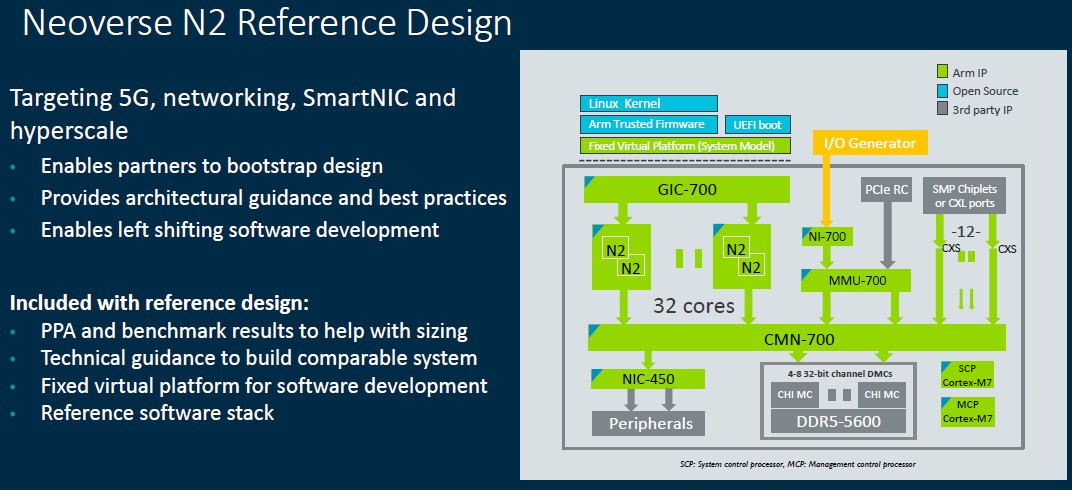
That is for a 32-core monolithic chip, with four to eight DDR5 memory channels running at 5.6 GHz (yeah!) and twelve ports for NUMA expansion or to use as CXL ports. This reference is not pushing any limits, but its simulators will help companies write software for the N2 and for hardware engineers to contemplate the changes they might make to create N2 designs of their own.


AWS Goes Wide And Deep With Graviton3 Server Chip
It is always an exciting time when there is a new compute engine coming into the market, and interest is particularly keen with any new Arm server chip entry. At this point, Amazon Web Services is by far the biggest consumer of Arm-based server processors in the world, with its …
Ampere Gets Out In Front Of X86 With 192-Core “Siryn” AmpereOne
The largest clouds will always have to buy X86 processors from Intel or AMD so long as the enterprises of the world – and the governments and educational institutions who also consume a fair number of servers – have X86 applications that are not easily ported to Arm or RISC-V …
India Declares CPU Independence With Aum HPC Processor
At the moment, the most powerful Arm processor on the planet is the 48-core A64FX processor from Fujitsu, which was created as the heavily vectored compute engine for the “Fugaku” supercomputer at RIKEN Lab in Japan. Nvidia is getting ready to ship its 72-core “Grace” Arm CPU, which has yet …
“and this is really more of an optimization of the N1 with the new Armv9-A architecture and the V1 front-end grafted onto it.”
Not… particularly? They don’t run the same ARM ISA version, and N2 is based not on the N1 but on the “Matterhorn” ARMv9 core arriving next month, itself an evolution of the Cortex-A78. N2 is not a variant of the N1, but rather a very distant cousin (A76 evolved into N1, on one side, and into A77 on the other; A77 was replaced by A78, which is being replaced by Matterhorn.)
Fair enough. In some ways it doesn’t go as far as V1 was the point I was making.
I have to assume ARM expects to take control of the datacenters when the design for Hades is frozen?
“vectorizing code is the future of performance”
I wonder if Seymour Cray i smiling down upon us or just wondering why we got off that path…
🙂
“why we got off that path”
As usual, the answer to that question is often
“Intel’s internal culture wars”…