

It is always good to have options when it comes to optimizing systems because not all software behaves the same way and not all institutions have the same budgets to try to run their simulations and models on HPC clusters. For this reason, we have seen a variety of interconnects and protocols used in HPC systems over time, and we do not think the diversity will diminish. If anything, it will perhaps increase as we come to the end of Moore’s Law.
It is always interesting to take a deeper look at the interconnect trends in the Top500 rankings of supercomputers that comes out twice a year. The Top500 list was announced at the recent ISC 2021 supercomputing conference, and we analyzed the new systems on the list and all the compute metrics embodied in the rankings, and now it is time to look at interconnects. And Gilad Shainer, who is senior vice president of marketing at Nvidia (formerly of Mellanox Technology) and who manages the Quantum line of InfiniBand switch products, always puts together an analysis of the Top500 interconnects and always shares it with us. And now, we can share it with you – with our analysis layered on top, as is our unbreakable habit. Let’s dive in.
For those of you who need bright colors to see them – like I do, for instance – lean into your screens a bit and follow the historical trends for interconnects in the Top500 list between November 2007 and June 2021:
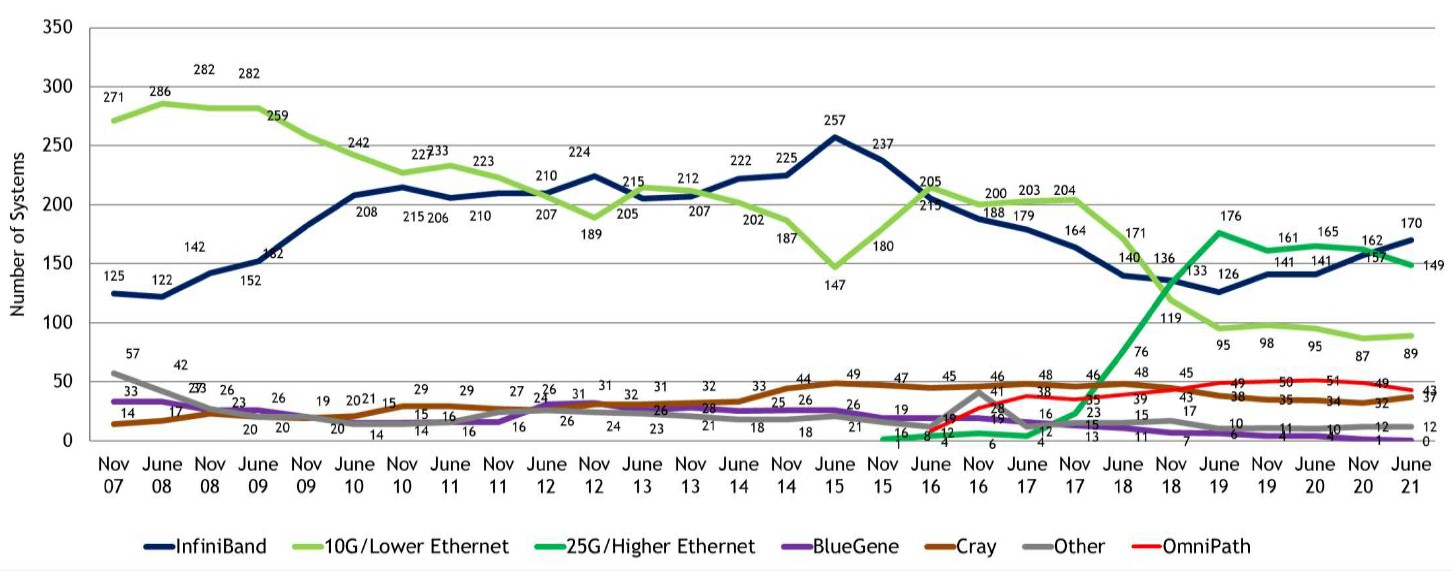
If you click on that image, you can make a a larger version of it pop up in an adjacent browser pane, which might be helpful.
We realize full well, as does Shainer, that the Top500 list includes academic, government, and industry HPC systems as well as those built by service providers, cloud builders, and hyperscalers, so this is by no means a pure list of “supercomputers” as people often generally call machines that run traditional simulation and modeling workloads.
What is clear is that InfiniBand waxes and wanes over time, and to a lesser extent 10 Gb/sec and slower Ethernet has been waning over the thirteen and a half years shown in this chart. InfiniBand is on the rise and its Omni-Path variant (which was controlled by Intel and is now owned by Cornelis Networks) has been holding more or less steady until the June 2021 list, where is slipped a bit. Ethernet running at 25 Gb/sec or higher speeds has been on the rise, however, spiking up faster between 2017 and 2019, which is when 100 Gb/sec switching (often the Mellanox Spectrum-2 switches) became cheaper than prior generations of 100 Gb/sec technologies, which relied on a more expensive transport and therefore were not something most HPC shops would consider. Just like a lot of hyperscalers and cloud builders have skipped the 200 Gb/sec Ethernet generation except for backbones and datacenter interconnects and waited until the cost of 400 Gb/sec switching came down so they could use 400 Gb/sec devices either as high radix 100 Gb/sec switches using splitter cables or as 400 Gb/sec high bandwidth pipes.
In any event, if you add Nvidia InfiniBand and Intel Omni-Path together to get a fair reckoning of InfiniBand’s representation on the June 2021 rankings, then there are 207 machines, or 41.4 percent of the list. And we strongly suspect a few other so-called “proprietary” interconnects on the list – mainly machines in China – are also InfiniBand variants. On the Ethernet side, add them all up across any speed and over the past four years Ethernet’s share of the interconnects on the Top500 has range from a low of 248 on the June 2021 list to a high of 271 on the June 2019 list. InfiniBand has been cutting into Ethernet in recent years, which is no surprise to us given the latency sensitivity of HPC (and now AI) workloads and the lowering cost of InfiniBand over time as its volumes ramp. (Having hyperscalers and cloud builders adopt InfiniBand has helped drive down the price some.)
Most of the Top100 systems and all of the Top10 systems on the list are what we would call true supercomputers – meaning they do traditional HPC as their day jobs, although more and more machines are moonlighting doing some AI. Her eis what the distribution of interconnects looks like for these upper echelon machines:
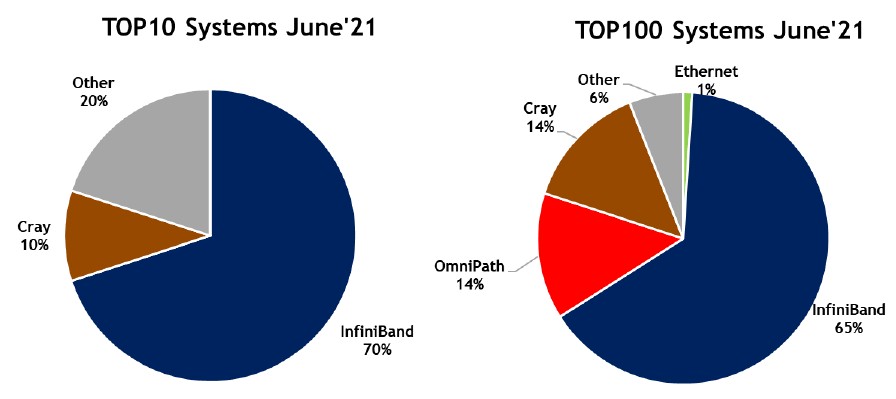
As you can see, Ethernet does not have much play here, but it will once Hewlett Packard Enterprise starts shipping 200 Gb/sec Slingshot, which is an HPC-tweaked variant of Ethernet developed by Cray, available in systems starting later this year with the “Frontier” exascale class machine going into Oak Ridge National Laboratory. Neither Shainer nor the Top500 sublist generator are calling Slingshot a variant of Ethernet, which it is, and in fact the “Perlmutter” system at Lawrence Berkeley National Laboratory, which is number five in the performance rankings, uses the Slingshot-10 variant, which has two 100 Gb/sec ports on each node. We strongly suspect that the number four machine on the list, the Sunway TaihuLight machine at the National Supercomputing Center in Wuxi, China, uses a variant of InfiniBand (although Mellanox never confirmed this and neither did the lab). So depending on what you believe, InfiniBand may have a larger presence. The top machine on the list, the “Fugaku” system at RIKEN Lab in Japan, uses the third generation Tofu D interconnect developed by Fujitsu, which implements a homegrown 6D torus fusion topology and a proprietary protocol. The number seven machine on the list, the “Tianhe-2A” machine at the National Supercomputing Center in Guangzhou, China, has a proprietary TH Express-2 interconnect that borrows some ideas from InfiniBand but is distinct.
In the Top100 pie, the Cray interconnects include not just that first Slingshot machine, but a bunch of machines using the prior generation of “Aries” interconnects. There are five Slingshot machines and nine Aries machines in the Top100 in the June 2021 list. If you call Slingshot Ethernet, then Ethernet has 6 percent share and proprietary Cray drops to 9 percent share; slice and dice it as you will. And if you really want to be honest, InfiniBand has 79 machines in the Top100 if you add Mellanox/Nvidia InfiniBand to Intel Omni-Path.
Here is what the distribution of interconnects looks like as you widen the aperture from the Top100 to the Top500 in 100 machine increments:
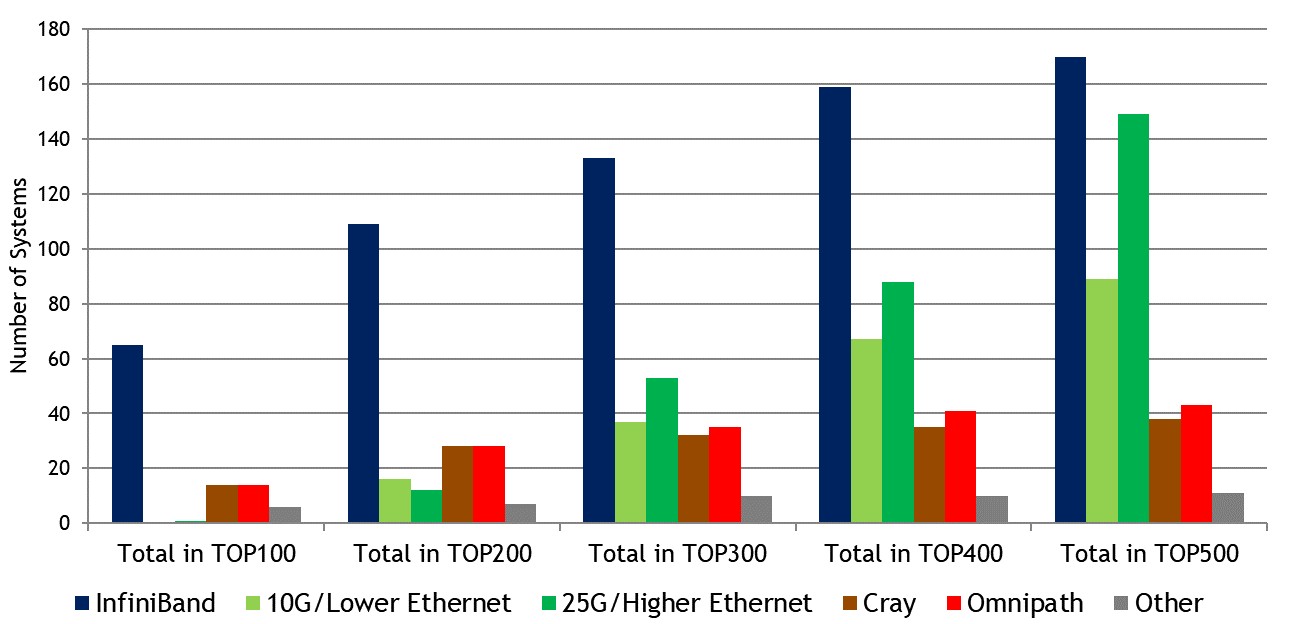
The penetration of Ethernet rises as the list fans out, as you might expect, with many academic and industry HPC systems not being able to afford InfiniBand or not willing to switch away from Ethernet. And as those service providers, cloud builders, and hyperscalers run Linpack on small portions of their clusters for whatever political or business reasons they have. Relatively slow Ethernet is popular in the lower half of the Top500 list, and while InfiniBand gets down there, its penetration drops from 70 percent in the Top10 to 34 percent in the complete Top500.
Here is one other interesting chart, which brings together most of the InfiniBand and a lot of the Ethernet on the Top500 list, and it explains in part why Nvidia paid $6.9 billion to acquire Mellanox:
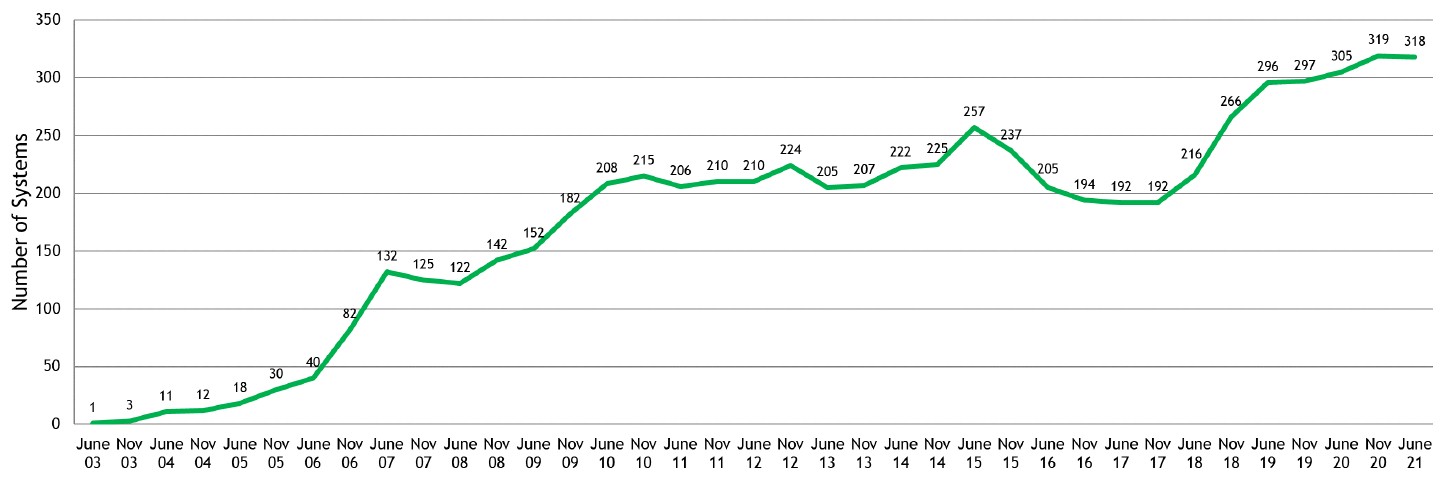
Nvidia’s InfiniBand has 34 percent share of Top500 interconnects, with 170 systems, but what has not been obvious is the rise of Mellanox Spectrum and Spectrum-2 Ethernet switches on the Top500, which accounted for 148 additional systems. That gives Nvidia a 63.6 percent share of all interconnects on the Top500 rankings. That is the kind of market share that Cisco Systems used to enjoy for two decades in the enterprise datacenter, and that is quite an accomplishment.
Nvidia doesn’t have to care which networking you buy – what it cares about intensely is what vendor you buy from. That’s a real competitive advantage, and it comes at the cost of having two distinct switching lines. That battle is done for Nvidia.

Hyperscalers And Clouds Switch Up To High Bandwidth Ethernet
The hunger for more compute and storage capacity and for more bandwidth to shuffle and shuttle ever-increasing amounts of data is not insatiable among the hyperscalers and large cloud builders of the world. But their appetite for is certainly always rising and occasionally voracious – even when facing a global …
No “Doom And Gloom” In The First Half For Arista
There has been no shortage of turmoil in the global economy thanks to war – trade and otherwise – and skirmish and terror of various kinds and severity. Despite all the uncertainty, business is business, and the hyperscalers and cloud builders need to upgrade their networks and the neoclouds need …
Weathering Heights: Of Resolutions And Ensembles
In the past year or so, watching supercomputer maker Cray, which is now part of Hewlett Packard Enterprise, has been a bit like playing a country and western song backwards on the record player. Supercomputing is booming a little (we don’t want to jinx it), Cray has its own interconnect …
Thanks Timothy – enjoyable read and confirms some of my previous work (see https://www.stackhpc.com/ethernet-hpc-2.html). My next plan was to repeat this exercise atop of hypervisors – once I can find the time :(.