

Exascale supercomputing is just as important to Europe as it is to the United States and China, but each of these geopolitical regions on Earth has its own way of developing architectures, funding their development and production, and figuring out where the best HPC centers are to host such machines to maximize their effectiveness. It takes good people, with lots of system and facilities skills, to make an exascale system hum. So only the elite centers get to go first.
For Europe, which is minus the United Kingdom after its Brexit separation, the Forschungszentrum Jülich in Germany is that elite exascale pioneer, having been named to host the first of three exascale-class supercomputers being funded partially by the EuroHPC Joint Undertaking and partially by the countries who can afford to kick in money for the honor of having such an HPC and AI engine within their borders.
That one of these EuroHPC exascale machines will be located in Germany comes as absolutely no surprise, given that Germany is an industrial and research giant and, at $4.23 trillion in gross domestic product in 2021, has the largest economy in the European Union.
The decision to site the first EuroHPC machine in Germany was made by the EuroHPC directors at the unveiling of the 550 petaflops “Lumi” pre-exascale supercomputer at CSC in Finland this week. The core Lumi machine is based on the same design as the 2 exaflops “Frontier” supercomputer at Oak Ridge National Laboratory in the United States. It seems highly unlikely that Jülich will get a carbon copy of Frontier, specifically since the European Union wants to foster indigenous semiconductors and system vendors to make its machinery. (Just like the United States, China, and Japan do.) Hewlett Packard Enterprise would love such a deal, but Atos, which is in the process of splitting its business in two, needs to deal more. With IBM out of the HPC game, Fujitsu not coming into Europe without partnerships with HPE and Atos, Nvidia busy with the supercomputer deals it has, and Dell not really chasing exascale deals, Atos will almost certainly be the prime contractor on the exascale machine going into FZJ. And if that is the case, Jupiter will probably be a variant of the BullSequana XH3000 that was previewed back in February.
That exascale machine will be known as JUPITER, short for Joint Undertaking Pioneer for Innovative and Transformative Exascale Research. It will be installed in the Jülich Supercomputing Centre, where the current JUWELS and JURECA supercomputers crank their flops to do simulations and train AI models.
There is another reason why Jülich was the obvious place to put the first exascale system in Europe: The Jülich Supercomputing Centre at Forschungszentrum Jülich was the first supercomputing center in Germany when it opened its doors in 1987. And Jülich was right on the cutting edge with its machinery from the beginning, as the chart below culled from the Top 500 supercomputer rankings over time makes obvious:
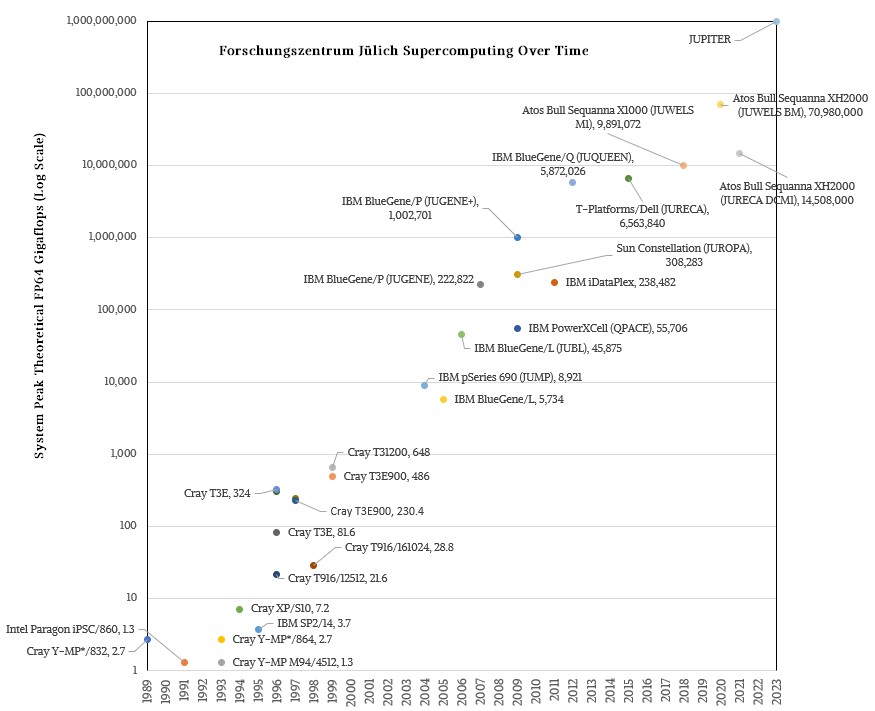
We only have data back to 1989, but as you can see, there is a mix of cutting-edge vector and RISC supercomputing in those early Jülich machines, made by Cray, Intel, and IBM, at Jülich.
From 1993 through 2003, the vast majority of the supercomputing power at Jülich was in Cray vector and MPP machines, and then in the wake of Big Blue’s $100 million BlueGene bet in 1999 and the delivery of systems several years later, Jülich became an IBM shop, with a smattering of machines made by T-Platforms (indigenous to Europe), Dell, and Sun Microsystems. More recently, as the BlueGene machines were wound down and as Jülich did not fall into the same trap as Argonne National Laboratory did with its massively late “Aurora” supercomputer – the natural successor to BlueGene was supposed to be Knights many core processors coupled to Omni-Path interconnect – and it has tapped Atos for its BullSequana systems in the 10 petaflops to 200 petaflops era that started around 2017 or so.
In recent years, the design of the supercomputers at Jülich – and the Lumi system at CSC in Finland – have been modular, with a mix of systems for CPU-only compute, hybrid CPU-GPU compute, GPUs for visualization, massive all flash storage, and even more massive parallel file systems on either flash or disk or a mix being stitched together to create a workflow of simulation, modeling, and machine learning that makes use of the portions of the overall machine to do their work. Many are plugging in quantum computers or machines that simulate them as well, and others are looking at more exotic neuromorphic circuits. We expect to see a lot more of this modular approach once HPC centers reach exascale on their primary compute clusters, with all kinds of matrix engines from Cerebras, Graphcore, SambaNova Systems, and Intel being woven into the mix to test out new silicon and new ideas.
Frankly, after paying for exascale systems, no major region is going to have the stomach to pay between $1 billion to $2 billion to build a 10 exaflops machine. But spending $5 million or $10 million to add some of these strange new computing devices is budgetarily feasible.
Here is how Jülich sees the overall architecture of the JUPITER system, and we are going to stop shouting its name now and just call it Jupiter, short for “Zeus Pater” in case you are unacquainted with the other name of the Greek god of sky, thunder, and lightning.

Given the name of this supercomputer, it would not be surprising to see the “Rhea” and “Cronos” Arm processors from SiPearl as the CPUs in at least part of Jupiter – they are the parents of Zeus, after all. And we think there is a chance that the hybrid Arm-RISC-V accelerators that SiPearl has been working on as well could be the accelerator. But it is not clear that these parallel math engines will be ready in time. It is probably not a coincidence that last October, Intel and SiPearl formed a partnership to allow the Rhea and Cronos processors to integrate with Intel’s forthcoming “Ponte Vecchio” Xe HPC GPU accelerators, but with Argonne’s Aurora machine based on Ponte Vecchio expected to burn almost twice as much juice as the Frontier system at the same 2 exaflops of peak performance, that lack of power efficiency would be a tough sell for an energy-conscious Europe.
That said, you go to the Exascale War with the GPU Army that you have.
And with the datacenters only having a 20 megawatt to 25 megawatt range, according to reports about the bidding process for the EuroHPC that we reported on in February, an exascale machine mixing Rhea CPUs and Ponte Vecchio GPUs might burn twice that to reach over 1 exaflops sustained. (It is hard to say without more data on the CPUs and GPUs in question.) And in a statement this week, Jülich said that the average power of the system is expected to be in the range of 15 megawatts.
That sure sounds like Jülich is going to use an SXM version of the “Hopper” H100 GPU accelerator to us, which burns 750 watts and which delivers 30 teraflops of FP64 performance on its vector cores and 60 teraflops of FP64 with its matrix Tensor Cores. That would yield about 11.7 megawatts for matrix FP64 math across around 16,700 Hopper GPUs to reach 1 exaflops peak. If you want to have 1 exaflops sustained on Linpack, you probably need around 25,650 Hopper GPUs and they would burn around 17.9 megawatts. Increase the computational efficiency of the system with software tuning and you could get it down below 15 megawatts for all of the components.
Jülich could surprise everyone and go with the 350 watt PCI-Express 5.0 versions of the Hopper GPUs, and save a lot of money and a lot of watts. Such a system would not have NVLink connections between the GPUs, but rated at 48 teraflops FP64 peak on the Tensor Cores, you could take 20,800 of them to reach 1 exaflops peak and maybe 32,000 of them to reach 1 exaflops sustained on Linpack – the latter at around 11.2 megawatts for the GPUs alone.
There is, of course, another GPU option: The AMD MI300 GPUs, which will have 8X the AI performance and probably somewhere around 2X the FP64 performance of the MI250X used in Frontier. Atos is selling the future AMD GPUs in the BullSequana XH3000 systems next year, as we previously reported, but it is not selling the current “Aldebaran” Instinct MI200 series. We strongly suspect that there will be a non-APU variant of the MI300 in addition to the hybrid CPU-GPU version that AMD talked about last week, and we have heard rumors of an MI300 that has four GPU chiplets on a single package. That is the one that might connect into the Rhea or Cronos processors in the Jupiter system.
CSCS in Switzerland is getting a Grace-Hopper system built by Hewlett Packard Enterprise with Nvidia components, and Finland just got Lumi from HPE, which is a chip off of Frontier. And the obvious question is, given the difficulties of providing indigenous chips for compute in Europe, why not just build up these two centers? The answer is money.
The budget for the Jupiter machine is €500 million, which is around $522.6 million at current exchange rates between the US dollar and the European euro. The EuroHPC Joint Undertaking is supplying half of that money, and then the German Federal Ministry of Education and Research and the Ministry of Culture and Science of the State of North Rhine-Westphalia are splitting the other half of the costs down the middle. Finland had a GDP of $296 billion in 2021 and Switzerland weighed in with a GDP of $811 billion. Germany’s economy is 14.3X times that of Finland, and 5.2X that of Switzerland. And Germany’s need for big HPC is greater than its economic proportion because of its economy’s heavy focus on science, engineering, and manufacturing.




I hope they make it! Current tech (Frontier) tells us that 20MJ/Exaflop is possible, but the Juwels XH2000/3000 (brand new just 4 months ago) runs at 40MJ/Exaflop … so, as you say, their engineers will need to blend in some Hopper, or MI300, or other innovative secret sauce to meet target specs.
It’s interesting how for many years now Linux is hardly ever mentioned anymore because it has simply become the default with all top500 supercomputers running Linux since many years.