
If the semiconductor business teaches us anything, it is that volumes matter more than architecture. A great design doesn’t mean all that much if the intellectual property in that design can’t be spread across a wide number of customers addressing an even wider array of workloads.
How many interesting and elegant compute engines have died on the vine because they could not get volume economics and therefore volume distribution behind them, driving down costs and driving the creation of software ecosystems? Well, the truth is, damned near all of them.
While Intel is no stranger at all to the GPU business. In fact, it would be hard to find a stranger GPU business than the one that Intel put together several times over the decades – yes, decades – as GPU guru Jon Peddie, writing for the IEEE Computer Society, has documented.
The latest decade alone saw the rise of the “Larrabee” X86-based GPU, which did not have competitive performance against Nvidia and AMD (ATI) alternatives and which was recycled as the “Knights” family of many core processors for HPC compute that Intel killed off as a compute engine after only two generations. The Iris series of integrated graphics circuits for the Core i5, i7, or i9 PC processors –the latter repackaged as the Xeon E3 server CPU family with integrated GPUs aimed at video streaming and VDI workloads. Intel did everything in its power to ignore the reasonably powerful GPU compute inherent in these Iris-enhanced server CPUs, but we pointed it out all the time.
But it sure looks like Intel is sorting it out with the family of discrete GPUs based on the Xe architecture, and the company has finally committed to having a broad and deep GPU compute bench – we think mostly because those who own the keys to the Xeon server CPU kingdom realized that if Intel doesn’t eat its own CPU compute lunch in the datacenter, the other two main GPU accelerator makers – and now both AMD and Nvidia have a CPU story to tell, too – were going to do it for them.
A Long Time Coming
This Xe GPU strategy is an evolution of its Gen11 Iris PC graphics cards and was first detailed back at Intel Innovation Day in December 2018, when Intel said that it would create a new architecture that would have discrete CPUs and integrated GPUs all based on the same Xe architecture that would span “from teraflops to petaflops” and range from low-end GPUs optimized for PC clients all the way out to hefty compute engines optimized for datacenter systems running AI and HPC workloads.
Nearly two years later, at Hot Chips, Intel elaborated a bit on the design of this new line of GPUs and talked about having tuned Xe GPU microarchitectures for specific workloads and using different combinations of processes, packaging, and sometimes chiplets. The Xe LP was a low powered GPU sold initially in the “Tiger Lake” CPU and then broken free in the discrete SG1 and DG1 GPUs for server workloads; the Intel Server XG310 GPU accelerator announced in November 2020 and co-designed with Chinese system maker H3C used the Xe LP SG1 variant.
The Xe HPG family was aimed at high performance gaming and datacenter streaming and graphics compute workloads. The Xe HP added HBM2e memory to the GPU complex and scaled up to four chiplets (what Intel calls tiles) on a single package, and was aimed at beefier media processing and AI workloads. And finally, the Xe HPC family was aimed at floating point and mixed precision compute for AI training and HPC simulation and modeling workloads where the Knights family left a hole.
The Xe HPC family consists of the “Ponte Vecchio” discrete GPU that Intel said last week it had started shipping to Argonne National Laboratory as the main computational engines in the second design of the “Aurora” exascale-class supercomputer.
The Flex Series 140 and 170 GPU accelerators that were just detailed by Intel are in the Xe HPG family, also known as the Artic Sound-M family because, well, it really makes no sense to have so many names, does it? Anyway, these datacenter GPUs have been rumored for months. These Flex Series cards were launched back in August, but many of the architectural details of these devices were not revealed.
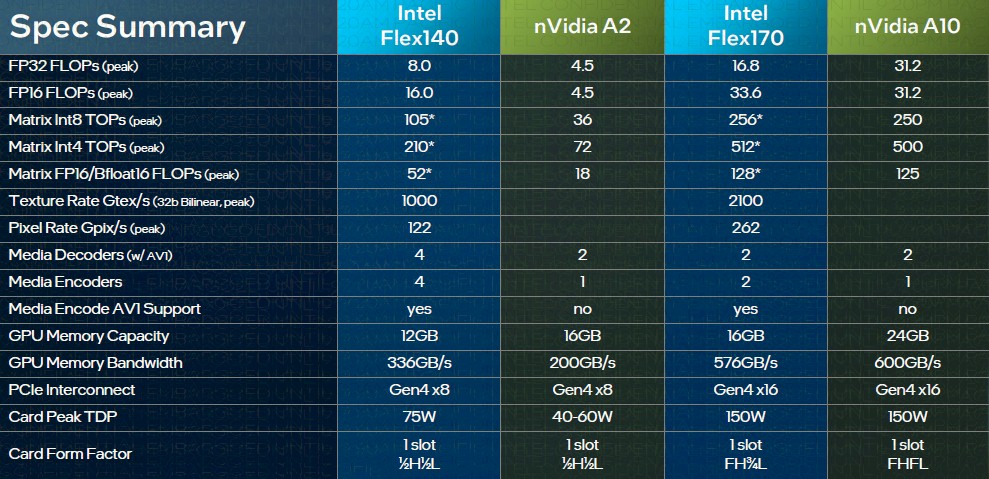
Here are the basic feeds and speeds as a refresher:

Don’t let the relative size of these discrete GPU cards fool you. The Flex Series 140 is based on a pair of DG2-128 GPUs with eight of the Xe graphics cores running at 1.95 GHz, two media engines, and eight ray tracing units sharing 12 GB of GDDR6 memory. The Flex Series 170 has a single DG2-512 GPU with 32 Xe cores running at 2.05 GHz, two media engines, and 32 ray tracing units sharing 16 GB of GDDR6 memory.
The Xe HPG core has 16 256-bit vector engines and 16 1,024-bit XMX matrix math engines, both of which are useful for AI inference, with 192 KB of share L1 cache. These two engines are why we care about the Flex Series at all. We only care about media transcoding and cloud gaming inasmuch as supporting this workload well in the datacenter means Intel can chase three birds with one stone and compete against Nvidia – and perhaps someday an AMD that also has a broader GPU portfolio – for GPU jobs in the datacenter. If Intel competes here, then it can afford to build better Xe HPC GPU accelerators like the “Rialto Bridge” discrete GPU kicker to Ponte Vecchio and the “Falcon Shores” hybrid CPU-GPU device, too.
The vector engine on the Xe HPC core can process 16 FP32, 32 FP16, and 64 INT8 operations per clock, and has a dedicated floating point execution port and another port for integer and extended math function processing. The XMX matrix engine is a four-deep systolic array, spiritually akin to the TPU from Google and the Inferentia chip from Amazon Web Services. The matrix engine on the Xe HPC core can process 128 FP16 or BF16 floating point, 256 INT8, or 512 INT4 operations per clock. The GPU can dispatch work to both the vector and matrix engines at the same time, which is useful.
For those of us who need help visualizing how multiply-accumulate units (MACs) differ from vector and matrix engines, here is a pretty chart Intel put together showing the differences in how the math stacks up and the calculation throughput grows:

The Flex Series 140 with two DG2-128 GPUs will beat the Flex Series 170 with one DG2-512 GPU on media processing by nearly 2X but does only 41 percent of the math crunching that the Flex Series 170 can do. We have not been able to find pricing on these devices as yet to do a proper price/performance analysis, but we expect for the Flex Series 140 to be considerably less expensive than the Flex Series 170, and so the price/performance gap on AI inference between the two devices may not be as large as it is on media processing. This, we believe, would be absolutely intentional on Intel’s part if it turns out to be the case. The idea is to have datacenter GPUs that are aimed at either media processing or cloud gaming but do reasonably well as AI inference, too, which is increasingly becoming not only a workload in the datacenter, but a workload embedded into every application.
Comparisons Are Only Odious With People, Not GPUs
Nvidia has just launched its “Lovelace” AD102 datacenter GPU with ray tracing, video encoding, and AI inference processing capabilities, and Intel could not have known enough about the new Nvidia L40 GPU accelerators to make comparisons with the Flex Series 140 and 150 cards. But Intel did line up its datacenter GPUs against the Nvidia A2 and A10 devices, thus:
A good example of how AI is being embedded in applications is object classification and object detection using AI inference within streaming video. Intel has a new tool called DLStreamer that optimizes the use of both Xeon SP CPUs and Flex Series GPUs to do object recognition within video stream inputs, like this:

As you can see at the bottom of this block diagram, the number of streams decoding video and running the Yolov5 object detection model on the streams is 67 percent higher with the DLStreamer running portions of the code on both the CPU and GPU, with the pair of Flex Series GPUs in the box driving 90 streams by their lonesome by the CPU-GPU combo driving 150 streams.
What we really want to be able to do is direct comparisons between Nvidia accelerators and the Flex Series for these workloads, and Intel obliged using Resnet50 for object classification and SSD-MobileNet for object detection:
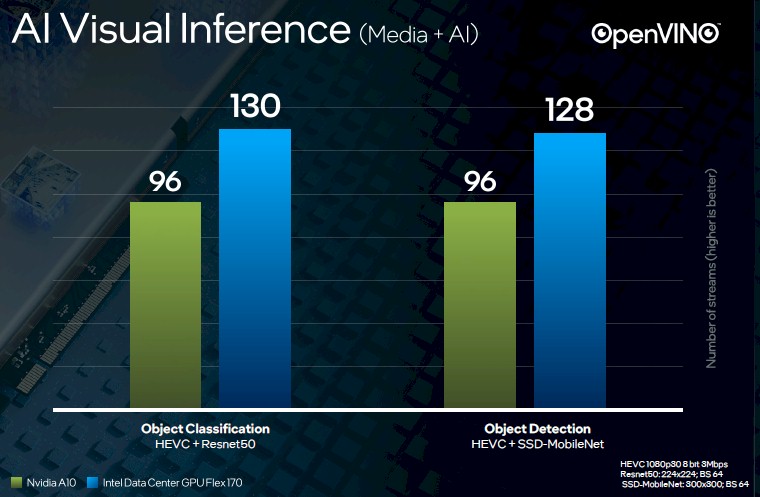
The Flex Series 170 is offering 35.4 percent more performance than the Nvidia A10 on object classification within video streams and 33.3 percent more performance on object detection within video streams.
If we had pricing on the Intel devices we could do a proper price/performance analysis. So we will work it backwards and figure out what Intel should charge instead.
The Nvidia A10 sells for about $8,400 at Hewlett Packard Enterprise and CDW and as low as $5,700 a pop at Dell. To offer the same bang for the buck on video inference, Intel could charge $11,200 for the Flex Series 170 – and we highly doubt Intel is going to try to go that high. At the same $8,400 price tag for the Flex Series 170, Intel would deliver 25 percent better bang for the buck, and $6,400 it would offer 43 percent better price/performance.
We suspect that Intel, being new to the GPU compute market, needs to charge less while at the same time delivering more performance.

Intel’s First Discrete Xe Server GPU Aimed At Hyperscalers
We have been waiting for years to see the first discrete Xe GPU from Intel that is aimed at the datacenter, and as it turns out, the first one is not the heavy compute engine we have been anticipating, but rather a souped up version of the Iris Xe LP …
Intel Pushes Out Hybrid CPU-GPU Compute Beyond 2025
One of the reasons why Intel can even think about entering the GPU compute space is that the IT market, and indeed just about any market we can think of, likes to have at least three competitors. With capital intensive businesses, there is an inevitable consolidation, and sometimes only two …
The Local Maxima Ascension Of Datacenter At Nvidia
When we said thirteen weeks ago that we thought that Nvidia’s datacenter business would be its largest operating division before too long, we didn’t think it would only take a quarter to do that. But, as the gamers are awaiting the next-generation GPUs to power their ever-more-lifelike experiences and as …
Well, I hope this doesn’t mean that the hopes for an Aurora that runs at better than 20MJ/Exaflop are dashed (30% better than the Ampere architecture won’t match the EPYC+MI250 I think). Here in France, they’re asking us to save 10% on electricity consumption (lowering thermostats), and there seems to be a gas shortage as well; the most efficient HPC and datacenters should really be favored.
Hi Tim, any word on power consumption? Intel may be driven by TCO concerns in the datacenter and enterprise to lower their price more….
Yeah, I will be looking at that once I know more. My understanding is that these are all creeping up pretty much as physics dictates. I heard a rumor that the top bin Ponte Vecchio is going to weigh in at 650 watts. Which sounds like a lot until Hopper came in at 700 watts.
One area frequently omitted in NP’s GPU coverage is software. Speeds and feeds are great and all, but until one factors in the per workload software component you really don’t have a product. The charts show esoteric performance areas for a reason: it presents the product in a fine light and cannot be easily replicated.
GPUs by their nature must include a software component to gain full perspective of their performance. Widely adopted benchmarks are intended for just this purpose. What’s presented here is just a piece of a story.
OpenVINO is around since quiet a while and integrated well in the ONNX ecosystem. So not sure what your point is