

It was a fortuitous coincidence that Nvidia was already working on massively parallel GPU compute engines for doing calculations in HPC simulations and models when the machine learning tipping point happened, and similarly, it was fortunate for InfiniBand that it had the advantage of high bandwidth, low latency, and remote direct memory access across GPUs at that same moment.
And so, InfiniBand networking has ridden the coattails of GPU compute for AI training and sometimes AI inference, and not just because Nvidia closed the deal to buy Mellanox Technologies, the standard bearer for InfiniBand switching in the datacenter, for $6.9 billion in April 2020. InfiniBand, with its low latency thanks to RDMA and high messaging rates, plus built in congestion control and adaptive routing, was already breaking into some of the hyperscalers and cloud builders who also wanted to run traditional HPC applications. And many think it is a foregone conclusion that InfiniBand will remain at the heart of massive AI training clusters because of the many advantages InfiniBand has over the many flavors of Ethernet.
But make no mistake. In fact, make no two mistakes.
First, the hyperscalers and cloud builders, unlike the HPC centers of the world, have always employed InfiniBand begrudgingly even if inevitably. They want one Ethernet and many different suppliers, not two kinds of networks and one of them from a single source. And second, each and every remaining serious supplier of Ethernet switch ASICs – Broadcom, Cisco Systems, and Marvell – is gunning for InfiniBand. And even Nvidia, with its Spectrum-X effort, which we revealed a month ago ahead of its launch, is trying to tip-toe around the InfiniBand issue by creating a “lossless Ethernet” tuned for AI workloads out of its Spectrum-4 Ethernet and BlueField-3 DPUs for those who will not deploy InfiniBand or those who, we presume, no longer want to.
The latter is evidenced by the launch of the “Jericho3-AI” chip from Broadcom, which was revealed at the end of April and which is making some tweaks to the “Dune” family of deep buffer switch ASICs so they are better at running AI training workloads than the latest “Trident” and “Tomahawk” families of Ethernet ASICs from Broadcom. And now, this week, we have Cisco jumping into the right with its Silicon One G200 ASICs, which were designed from the ground up with AI training workloads in mind.
We are working on a piece that drills down into the Spectrum-X architecture that is also aimed at AI and which looks to have a similar approach, but implemented in a completely different way. Hang tight. But if we had to summarize it, it is to take the 51.2 Tb/sec Spectrum-4 ASIC, driving 400 Gb/sec and 800 Gb/sec ports and with pretty substantial buffers and RoCE RDMA support, and front end it with a BlueField-3 DPUs at the server endpoints to provide better adaptive routing and congestion control.
There is also the “Slingshot” variant of Ethernet tuned up for HPC workloads by Cray, which has been a part of Hewlett Packard Enterprise for several years now. Slingshot is being deployed on three exascale class systems in the United States and a number of other large systems in Europe and it remains to be seen how it will do on AI workloads. Presumably, given that AI was not a new workload when the “Rosetta” switch ASIC was created by Cray, Slingshot can tweak its personality to manage HPC or AI workloads as needed.
One Silicon To Rule Switches And Routers
Cisco ignored the threat of Broadcom and the handful of other merchant switch ASIC makers for years, but eight years ago it started down the path of becoming one, resulting in the launch of the Q100 routing chip in December 2019 and the expansion of the routing chip lineup and the addition of switch ASICs to the Silicon One family in October 2020. We started taking the Silicon One effort seriously in March 2021, and over the course of those eight years, Cisco has invested over $1 billion in its merchant chips, which it is happy to sell to any switch or router maker as well as use within its own switches or routers.
With its latest Silicon One ASICs, Cisco is doing something similar, but rather than having a DPU offload model from the GPU nodes and the Spectrum-4 switches, the world’s largest switch maker is taking a the scheduled fabrics embedded in its modular switches – those big, wonking things that service providers and some hyperscalers and cloud builders buy – as its inspiration and virtualizing it across a spine/leaf network with various degrees of performance and packet behavior.
Like the Jericho3-AI approach, the new 51.2 Tb/sec G200 and 25.6 Tb/sec G202 in the Silicon One family of ASICs can implement what is called packet spraying to provide a fully scheduled Ethernet fabric, which offers significant performance benefits over using the Equal Cost Multi-Path (ECMP) load balancing technique commonly used in standard Ethernet to find the best way to deliver packets between clusters of endpoints so they can do their calculations.

Not that this has anything to do with the extensions and architecture for supporting AI workloads on Ethernet, but there is one important thing about the Silicon One G200 and G202 that bears pointing out and that demonstrates how increasingly serious Cisco is about being in the merchant silicon business as well as being a provider of switches and routers in its own right based on Silicon One. For the first time, Cisco has a team of engineers that are designing its own SerDes communication circuits, and it has been able to get its 100 Gb/sec PAM4 SerDes (which like everyone else’s run at 112 Gb/sec before encoding overhead is taken off) to have a 43 decibel signal to noise ratio, which means it is capable of drive more than two times the IEEE standard for passive digital to analog converters, or DACs, Rakesh Chopra, a Cisco Fellow and architect on the Silicon One line of ASICs, tells The Next Platform. That means it can drive a signal down a 4 meter cable.
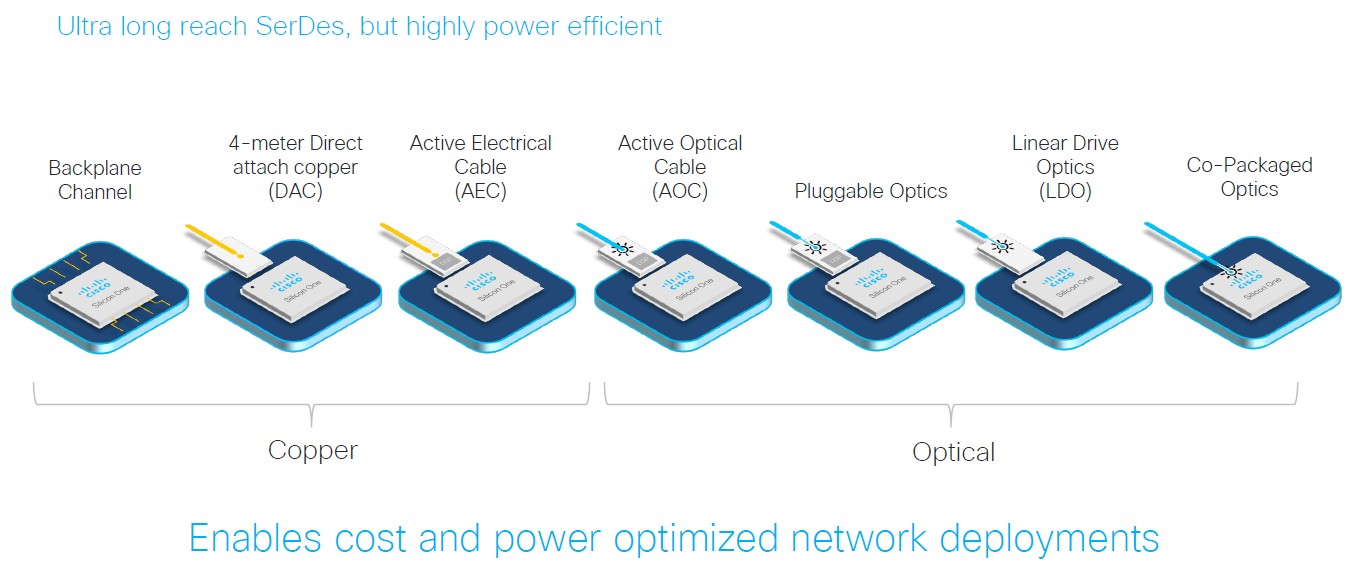
Just like the “Peregrine” SerDes that are used in the Tomahawk5 and Jericho3-AI switch chips from Broadcom. And just like those two Broadcom chips, the G200 and G202 chips can drive all kinds of copper and optical connections between a switch and its endpoints or peers on the network, including co-packaged optics, or CPO, which Broadcom says will drive the best price and thermal efficiency across its switches. There are skeptics about CPO for switching, but less so for more generic I/O coming out of systems, but we think CPO for networking is inevitable as the technology evolves and wires keep getting cut in half inside the switch as bandwidths double with each generation.
It is hard to believe that Cisco did not do its own SerDes before, but clearly to keep up with, much less beat, Broadcom, it means having complete control of the IP stack, just like Broadcom does.
Taking A Look Under The G200 Hood
Like Broadcom’s Tomahawk5 and Nvidia’s Spectrum-4, the G200 ASIC has an aggregate throughput of 51.2 Tb/sec. The G200 and its companion G202, which is rated at 25.6 Tb/sec, are etched using 5 nanometer processes from Taiwan Semiconductor Manufacturing Co, a node shrink from the 7 nanometer processes used with the prior Silicon One switch and router ASICs. There is no equivalent P200 routing chip, which could be rated at 19.2 Tb/sec or 25.6 Tb/sec as yet, but it is reasonable to expect one sometime soon. Right now, everyone is hot to demonstrate how their Ethernet or InfiniBand is aimed at AI workloads, and there is not really a routing use case for AI training or inference, so that can wait.
The G200 has 512 of the 100 Gb/sec SerDes, which have PAM4 signaling to double up a native 50 Gb/sec I/O lane. Unlike some 51.2 Tb/sec architectures, which top out at 256 MAC addresses per ASIC, Chopra says that Cisco is able to put 512 MACs on the G200 and thereby maintain a 1:1 ratio to keep it all in balance and to allow for the maximum scale of radix on the chip – 512 ports at 100 Gb/sec and any lower speeds that are geared down, such as 50 Gb/sec, 40 Gb/sec, 25 Gb/sec, and 10 Gb/sec legacy modes.
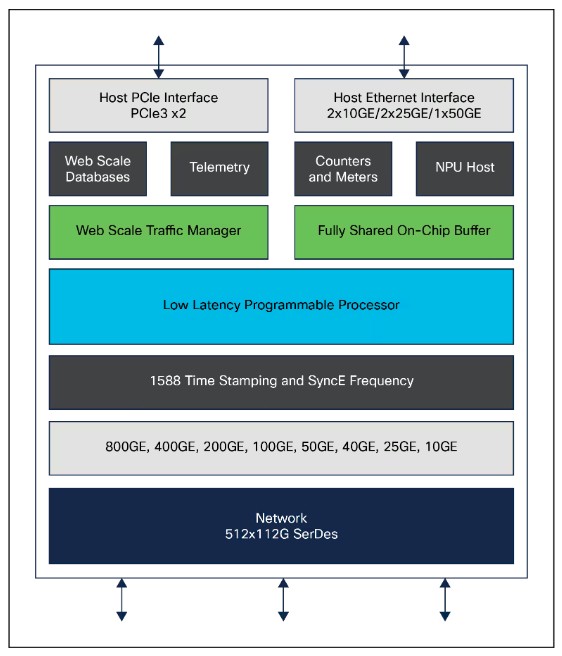
And while many switch ASIC designs have packet buffers that are front-ended by output queues and back-ended by input queues, thereby making the buffer size is based on the port capacity, the G200 has a fully shared packet buffer across all of its SerDes lanes and ports, which helps increase flow control through the device and boost AI application performance. The G200 has a programmable packet processor that can be programmed in the P4 language championed by Google and adopted by many others (AMD’s Pensando and Intel’s former Barefoot Networks, to name two).
“We have a P4 programmable NPU in all of our Silicon One devices, and that stays true here,” explains Chopra. “But to chase latency, we have come up with an evolution of that packet processor that is fully deterministic in nature, with very, very low latency, but it still issues a huge number of lookups per second – 435 billion lookups per second, to be precise, is what this device is doing to do its forwarding. And that allows us to do advanced features like SRv6 Micro SID. So it’s not just a stripped down, can’t do anything style packet processor. We can do features, and we can be very low latency and very deterministic, too.”
AI Performance And Cluster Scale
That brings us to performance and scale, which are obviously interconnected in distributed computing and which is what AI training is all about these days – and we would add, so is HPC, and many things that are good for AI will be good for HPC. Speaking very generally, HPC tends to need very high message rates for its switch ASICs and is moving around a lot of small chunks of data, while AI has a lot of fat data flows. And neither has a network pattern like a traditional microservices Web application, as Chopra illustrates here with an all-to-all collective traffic pattern for AI training:
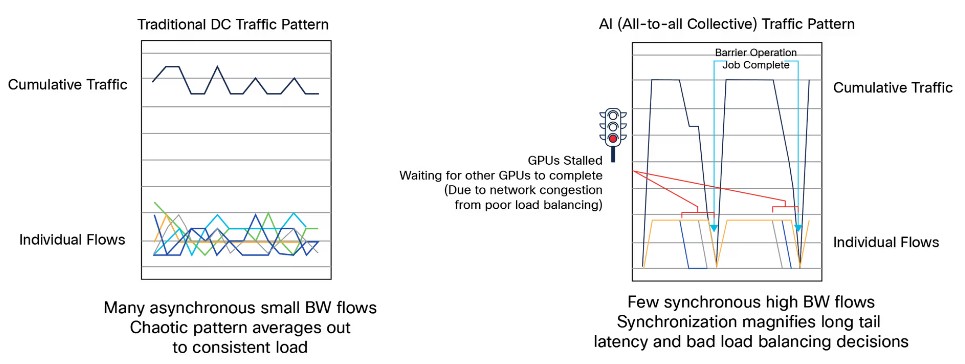
The random patterns of the east-west traffic of Web applications tends to average out to a steady state load almost all of the time. But with AI training, there are far fewer flows, and ones that need much higher bandwidth, and synchronization across the hundreds, thousands, to tends of thousands of compute devices in an AI cluster means that latencies whip around like crazy because all of the GPUs have to wait for all of the other GPUs to finish at each step in the training. The chart above shows how one suboptimal path through the network stalls the AI workload across multiple GPUs.
Tail latencies matter in large HPC workloads, where one job runs on a distributed system, but they matter even more in AI workloads, where many distinct concurrent workloads are running at the same time and causing contention and the job completion time (JCT) is determined by the tail latency of the network. We would add that a shared HPC capacity cluster will behave more like an AI cluster than a single-job HPC capability cluster. . . . So it all depends.
With Cisco and a few other Ethernet ASIC suppliers, there are three levels of performance, which can be gauged against InfiniBand and each other. Cisco stacks them up like this:
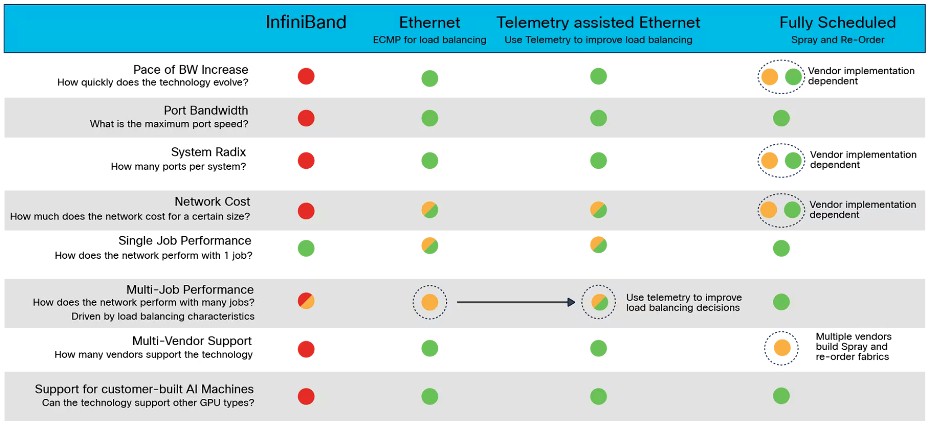
Cisco does not have much nice to say about InfiniBand, except that it has excellent single job performance on a cluster. And while Ethernet with ECMP load balancing helps, it has some issues when multiple jobs are sharing the network. With Enhanced Ethernet, telemetry gathered from the network is used to improve load balancing, but single job performance of Ethernet doesn’t really improve and the cost of the Ethernet network doesn’t really improve.
Then there is Fully Scheduled Ethernet, which involves chopping up flows and spraying them as uniformly as possible across the entire fabric, using all of the paths and bandwidth available to try to even out all of the traffic out and provide more uniform performance on multiple jobs running at the same time. This benchmark below shows the performance of plain vanilla Ethernet with ECMP against Fully Scheduled Ethernet:
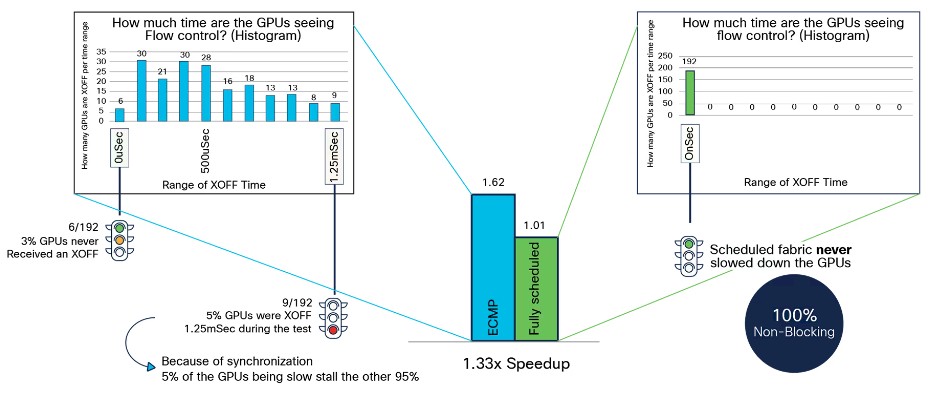
This particular test was for systems with a total of 192 GPUs, and the histograms show the rate that the GPUs were stalled waiting for data because of synchronization issues due to congestion on the network and the two bars in the center of the chart show the aggregate impact on job completion time for a mix of AI workloads. Those numbers – 1.62 and 1.01 – are relative to the peak, idealized performance of the interconnect if there was no contention.
With fully scheduled Ethernet, which probably deserves its own abbreviation at some point, the AI workloads completed 1.33X faster. Now, if InfiniBand offers 20 percent more performance than regular Ethernet on AI jobs, as Nvidia itself has said, then Cisco’s implementation of fully scheduled Ethernet is presumably in the same ballpark when it comes to AI workloads.
We would love for some real benchmark tests to hold compute constant and change out the network – InfiniBand, Jericho3-AI, Cisco G200 with FSE – and show AI performance at different scales of GPU, perhaps ranging from 8 to 4,000 units on a cluster. That is the range people need to understand. We want a little red wagon, a sailboat, and a white pony, too. . . .
This chart, which shows the impact of job completion as the number of concurrent AI jobs, all trying to hog network capacity, is increased:
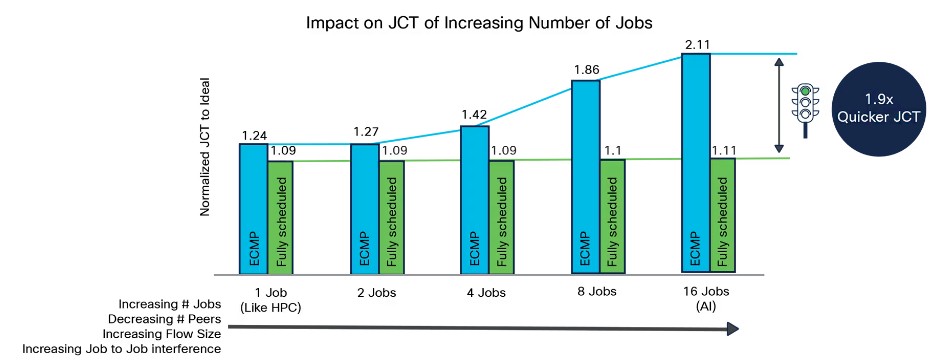
Clearly, as the concurrent AI job count increases, the fully scheduled Ethernet is not impacted very much, but Ethernet with ECMP can’t keep up and it takes 1.9X as long to complete all 16 jobs on the densest test Cisco showed results for.
Now, let’s talk about scale for a second. The hyperscalers and cloud builders are trying to connect tens of thousands of GPUs together to run large language models and recommendation engines. Here is a scenario that Cisco cooked up that uses its advantage on radix for its 51.2 Tb/sec switch, which as we said above, can drive 512 ports running at 100 Gb/sec while competitors can only drive 256 ports running at 200 Gb/sec because they have half as many MACs on their ASICs:
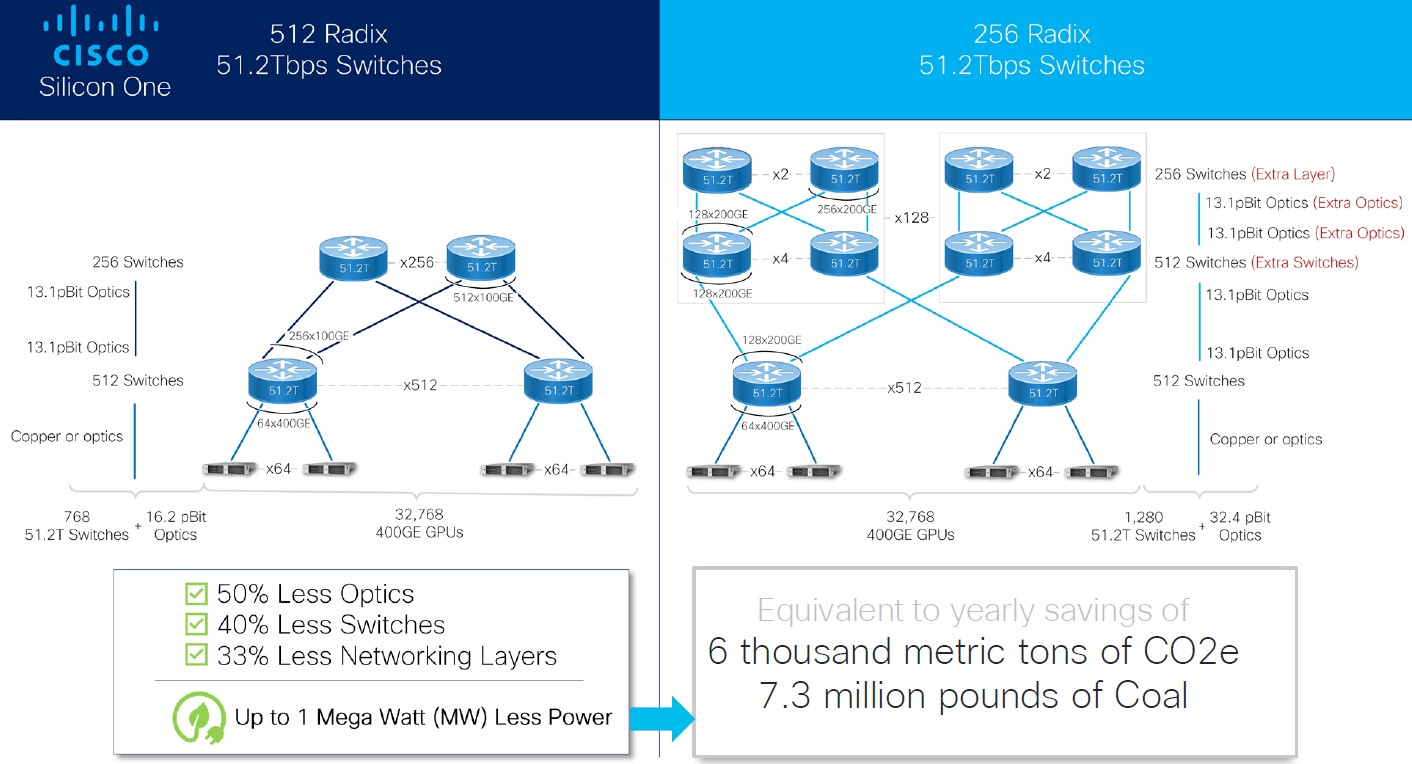
In G200 switch scenario, there are 512 leaf switches, which have 64 ports running at 400 Gb/sec down to servers, with one port for each GPU, which links out to a total of 32,768 GPUs. There are 256 uplinks running at 100 Gb/sec coming out of each switch as well. The spine tier of the two-layer network of G200 devices is comprised of 256 more switches, while provide multiple paths linking the leaf switches to each other.
On the right hand side is presumably an Ethernet network using a Tomahawk5 or Spectrum-4 ASIC, which requires a three-tier network because the radix on these switches is half. You need 512 switches in the first layer of the network, and another 512 switches in the second layer, plus another 256 in the third layer that cross couples the second layer. The Cisco approach with the G200 requires 40 percent fewer switches and 50 percent fewer optical cables in the fabric and also has one fewer layer and therefore fewer hops to cross link the same 32,768 GPUs. By the way, InfiniBand tops out at just north of 48,000 endpoints in a two-level network and requires three layers to scale beyond that.
We wonder about the effect on AI workload performance of downshifting from 400 Gb/sec ports come put of the servers for each GPU and then tapering down to 100 Gb/sec ports on the uplinks in the leaf switches and in the second level spine switches. There are fewer hops in this network, but less bandwidth on the links.
In any event, this is the argument that Cisco is making for its G200 ASIC for AI workloads.
One last thing: The G200 ASIC has twice the stuff as the G100 that precedes it, and because of this balance in the design, it has twice the performance and twice the power efficiency in the same thermal envelope, which is what that shrink from 7 nanometers to 5 nanometers provides. The G202 ASIC has the same number of SerDes as the G200 but runs them at a half speed of 50 Gb/sec and is therefore rated at 25.6 Tb/sec of aggregate bandwidth. It is designed to deliver 64 ports running at 400 Gb/sec ports with 8 x 50 GB/sec optics.
Like many of you, we are of an age when 32 ports running at 800 Gb/sec seems damned near magical. And so does 128 cores on a single CPU or 20 TB on a single drive, now that we think on it. We live in the future.




This article doesn’t speak about CRAY advance link-connection tech, “Slingshot.” Perhaps HPE doesnlt give tech information to Timothy team?
That is a valid point, just an accidental omission. We are, of course, quite familiar with Slingshot, and it is, of course, an HPC variant of Ethernet. It remains to be seen how well it does on AI training at scale, but presumably well with Frontier, El Capitan, and Aurora all using it at exascale. Slingshot could do very well on HPC and average or very well on AI. We shall see.
There used to be several sources of Infiniband cards and switches. At least three IIRC. It is not owned lock, stock and intellectual property by nVidia. So what happened, Intel gobbled up one maker and canned it, standard Intel behaviour. nVidia gobbled up another, and where is the third?
If the market needs more IB makers, surely the market can come up with the money to stand one or three up. The market has enough money to allow f*ckwits like Musk to borrow enough to buy Twitter, eh?
Well, Cisco ate one of the InfiniBand vendors, and Mellanox itself ate Voltaire way back when. Technically, Cornelis Networks is a vendor of InfiniBand, having bought the Intel Omni-Path business and trying to get it back on a reasonable roadmap. So there are two, sort of. But it will take Cornelis time to get more traction.
“The market has enough money to allow f*ckwits like Musk to borrow enough to buy Twitter, eh?”
When someone lives in your head rent free.
ASIC Ethernet providers in the last 20 years : “Infiniband is going die”
But Infiniband is live and it the ChatGPT interconnect infrastructure
‘… the P4 language championed by Google and adopted by many others (AMD’s Pensando and Intel’s former Barefoot Networks, to name two).” Actually, Barefoot (now Intel) championed P4, and others like Google and Pensando adopted it. I’m surprised you got this backwards.
I think the correct sequence was Nick McKeown and team at Stanford invented it, Google loved it and used it, and then Nick co-founded Barefoot Networks.
There is a big gap in that roadmap. When is/was P200 supposed to arrive? I wonder if Cisco have struggled to get time at the foundry over the past 18 months. It’s not like they have the buying power of someone like Broadcom.