

Variety is not only the spice of life, it is also the way to drive innovation and to mitigate risk. Which is why we are seeing switch architectures evolving to drive specific kinds of AI workloads, just as we saw happen with HPC simulation and modeling workloads over the past two and a half decades.
In the early years of scale-out AI training – meaning from 2010 to right about now – InfiniBand, one of the preferred, low latency networks for HPC simulation and modeling, rose to become the dominant network interconnect to glue nodes crammed with GPUs together. But many of the AI startups such as Cerebras Systems, SambaNova Systems, GraphCore, and Intel’s Gaudi have their own interconnects, as does Google with its optical switching that is at the heart of its TPUv4 matrix math behemoths. If you want to be generous, you could say that the Slingshot variant of Ethernet created by Cray (now part of Hewlett Packard Enterprise) is also a custom interconnect that can (and will) run AI workloads at exascale.
Broadcom, which has dominant market share in switching and routing semiconductors among the hyperscaler and cloud builder giants that are driving the AI revolution, wants to get its piece of the AI networking action. And so the company has taken the “Jericho” family of switch and routing ASICs with their deep packet buffers and redesigned them specifically to take on AI workloads, with the initial Jericho3-AI switch chips being the first instantiation of the design. And with this design, Broadcom has put InfiniBand firmly within its sights and is most definitely gunning for it.
That means, among other things, that Broadcom will pit Arista Networks and the collective of whitebox switch makers used by the cloud builders and hyperscalers against Nvidia on its home AI turf, which includes a formidable AI software stack, GPUs and soon CPUs, and GPU memory interconnects as well as the InfiniBand networking hardware and software that Nvidia got from its $6.9 billion acquisition that completed three years ago this week.
With the Jericho3-AI chips, Broadcom is reworking the line of deep buffer Jericho chips, which often are used by hyperscalers and cloud builders to do routing as well as switching functions, and giving them the kind of performance on the collective operations commonly used in AI and HPC that makes them absolutely competitive with InfiniBand for AI workloads and that gives them capabilities not available in standard Ethernet ASICs, including those in its own “Trident” and “Tomahawk” families commonly used in the datacenters of all scales.
The Jericho3-AI chips make use of the same “Peregrine” family of SerDes signaling circuits that debuted in the “Tomahawk5” leaf/spine Ethernet switch ASICs that were announced back in August 2022. Peter Del Vecchio, product line manager of the Trident and Tomahawk switch lines at Broadcom, who have us the Jericho3-AI briefing, says the Tomahawk5 ASICs started shipping in volume in March of this year and that means we should see it appearing in switches soon.
The Tomahawk5 is a much beefier device in some ways than the Jericho3-AI, but it has much more modest buffers and is design for the top of rack and leaf switching done in the Clos networks at these hyperscalers and cloud builders. The Tomahawk5 is implemented in 5 nanometer processes from Taiwan Semiconductor Manufacturing Co and has 512 of these Peregrine SerDes running at 100 Gb/sec (enabled by PAM-4 modulation of the signals) wrapped around the packet processing engines and modest buffers to create a device that has 51.2 Tb/sec of aggregate bandwidth. The Jericho3-AI chip, also etched with 5 nanometer processes from TSMC, has 304 of these same SerDes, with 144 of them allocated to downlinks and 160 of them reaching out the Ramon 3 fabric elements higher up in the network that act as leaf and spine switches. Like this:
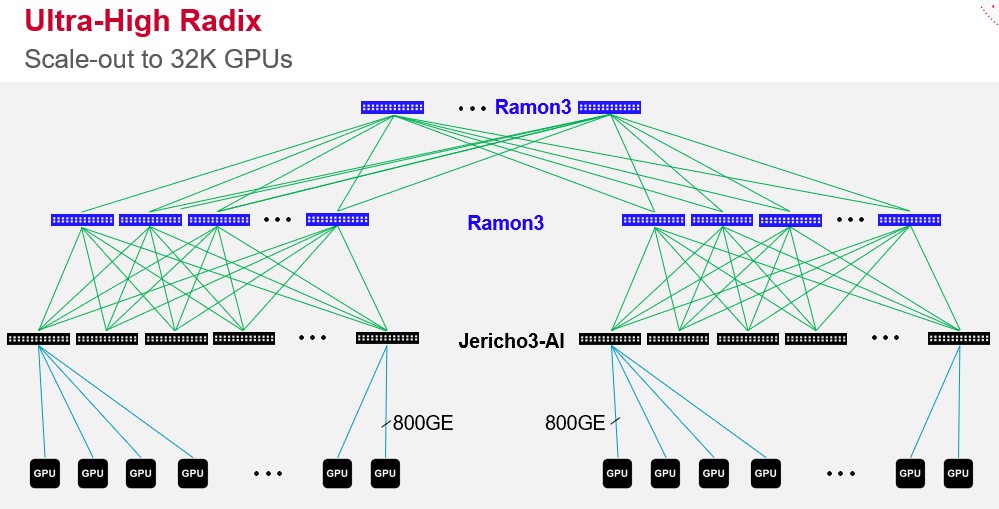
You will note that the switch ports in the diagram are linking directly to the GPUs, and that is not an error. Increasingly, architectures are going to be doing this. Why go through the server bus to link the GPUs? The important thing is that the scale of the Ramon 3 fabric elements (essentially spine interconnects) and the Jericho3-AI leaf or top of rack switches allows for more than 32,000 GPUs to be linked in a Clos topology into a massive AI training system, with the ports running at 800 Gb/sec. Admittedly, no servers today will have ports running faster than 200 Gb/sec or 400 Gb/sec because the adapter cards are not out there yet running on those native speeds. That will probably not happen until PCI-Express 6.0 slots are available in servers in the 2025 timeframe.
Right now, when Microsoft is running GPT training runs for itself and its partner in AI framework, OpenAI, it is using standard HGX GPU system boards lashed to server host nodes and linked to each other with one 400 Gb/sec ConnectX CX7 network interface for each GPU in the eight-GPU system. Microsoft Azure uses a fat tree topology on the InfiniBand network, like many HPC shops do, and also uses the Message Passing Interface (MPI) protocol to schedule data and computation across 4,000 GPUs linked into a cluster for running GPT and other frameworks. As a single instance. And Microsoft will grow that as needed, and if Jericho3-AI chips deliver better performance and economics for AI workloads, there is nothing in the Microsoft architecture that prohibits it from moving to a fabric based on the Broadcom Dune StrataDNX family, of which Jericho3-AI and Ramon 3 chips are a part.
Ditto for every other cloud and hyperscaler.
Here is the neat thing about Tomahawk5 and Jericho3-A1 due to their use of the Peregrine SerDes. The way these SerDes are designed, they can drive optics directly using what is called linear drive optics, which means that the SerDes can talk directly to the transimpedance amplifier in the optics without the need for a digital signal processor in front of it. Moreover, the Peregrine SerDes can push a signals down a 4 meter direct-attached copper (DAC) cable – twice the length of an IEEE spec cable – with no retimers or repeaters needed. And although this option is not commercialized yet, Broadcom can use Peregrine SerDes to drive co-packaged optics if it has customers who want to drive down thermals, cost per bit, and latencies even further.

Technically, the Jericho3-AI chip is rated at 14.4 Tb/sec because only 144 SerDes driving the downlinks, and the remaining 160 Serdes, or 16 Tb/sec, going out to the fabric are not counted in the official throughput of the device. There are probably more physical SerDes on the chip, which is a monolithic device and which is not composed of chiplets, for the purposes of increasing the effective number of Serdes after the anti-yield on the 5 nanometer device is blocked out. (As is common in all complex semiconductor device design and manufacturing these days.) If we had a die shot of Jericho3-AI, we would know for sure. . . .
The Jericho3-AI chip was designed specifically to help deal with the complex flows on the network when collective operations – particularly all-to-all or all reduce operations – are performed at the end of each step of calculations in the distributed model. These functions are critical in large language models and recommender systems, which are very different characteristics and which need somewhat different hardware (and which is why the “Hopper” GPU needs a tightly coupled “Grace” CPU for future Nvidia systems focusing on recommender systems).
Alexis Bjorlin, vice president of infrastructure at Meta Platforms, talked about the design of its “Grand Teton” AI systems and companion “Grand Canyon” storage arrays in her keynote at the Open Compute Project summit last October, and unbeknown to us she shared the following chart concerning four different machine learning models that are part of the Deep Learning Recommendation Model (DLRM) recommender system used by Meta Platforms, which was open sourced in July 2019:

What this chart shows is the percent of CPU time that is wasted waiting for the collective operations to run on the network before the next computing step can begin. It is wall time minus compute time divided by wall time, which gives you network time.
Now, with a single node in these massive AI clusters costing maybe $400,000 to $500,000, having that iron just sitting there 18 percent, 35 percent, 38 percent, or 57 percent of the time, depending on the model, is a very expensive proposition indeed. With a network better optimized for AI workloads, any change in network efficiency for collective operations means that CPU-GPU hardware investment is not being wasted proportionately.
To find out how Jericho3-AI competed against InfiniBand, Broadcom worked with one of the hyperscalers and swapped out a 200 Gb/sec InfiniBand switch linking GPU-accelerated compute nodes and replaced that InfiniBand switch with an Ethernet switch. Both switches were running the Nvidia Collective Communication Library (NCCL), a collective operations networking software driver created by Nvidia to offer better performance of collective operations for dense groupings of GPUs than does running just normal MPI as one might on CPU cores or sockets. NCCL is topology aware, which means it knows the difference between fast and fat NVLink pipes within the compute node and InfiniBand or Ethernet pipes across nodes. These are not either/or propositions, and NCCL and MPI are often used together.
Here is how the performance differed between a server with a whopping sixteen 200 Gb/sec ports on a ConnectX-6 SmartNICs, which support either InfiniBand or Ethernet protocols, with switches based on either Quantum 2 ASICs from Nvidia or Jericho3-AI ASICs from Broadcom:
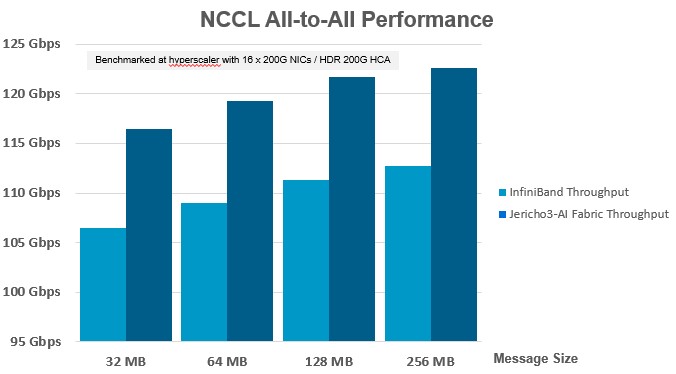
You have to watch that Y axis carefully because the all-to-all collective operation performance of the two switches does not run from 0 Gb/sec to 125 Gb/sec but rather from 95 Gb/sec to 125 Gb/sec, which means the performance delta is visually larger in this chart than it actually is. The upshot is that almost regardless of message size, the Jericho3-AI chip delivers somewhere around 10 percent more throughput than the InfiniBand switch does running the same AI training workload.
Now, 10 percent is a big deal if you look at the chart supplied by Meta Platforms. Anything that boosts the effective speedup of the network shortens the wall clock time of collective operations. Del Vecchio tells The Next Platform that the performance speedup of the Jericho3-AI switch is also about 10 percent for all reduce collective operations (but we don’t have a chart on that). That implies that time to completion for an AI training run will also be improved, and if time is money – and it usually is when it comes to AI and HPC workloads – then more models can be trained in the same time. Add to this the power savings and longer DACs, and Broadcom will have a compelling value proposition in AI training to compete against InfiniBand.
How is Broadcom bringing the heat to InfiniBand? The Jericho3-AI chips have some feature names that seem pretty fantastical, but what it comes down to is better load balancing and congestion control that reduce contention on the network and improve latency across the network where, frankly, it matters more than lowering the latency on a port to port hop inside the switch, where InfiniBand has a huge advantage – on the order of 3X to 4X or more – compared to traditional, datacenter-class Ethernet switches based on ASICs like the Tridents and Tomahawks and their competition from Cisco Systems, Mellanox, Marvell, and others. (That’s us saying that, not Broadcom. But it’s true.)
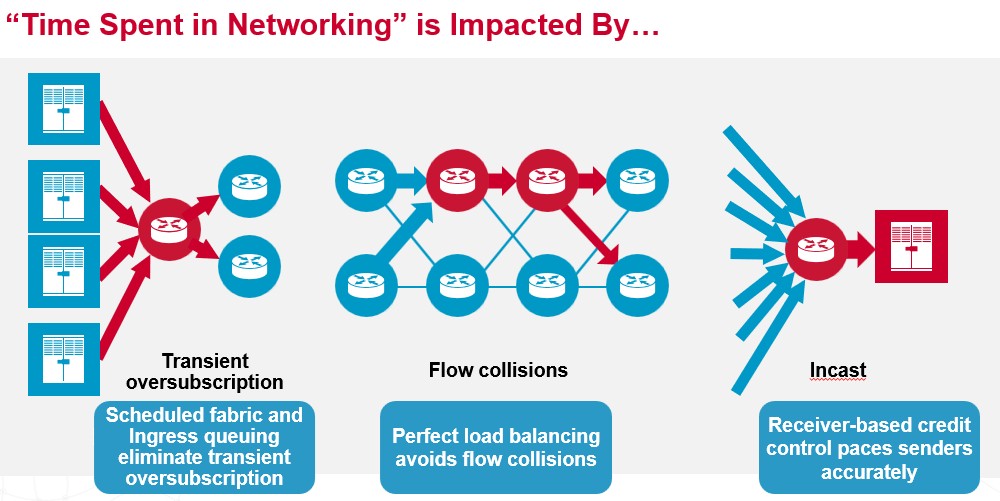
The two important features in the Jericho3-AI chips are what Broadcom hyperbolically calls perfect load balancing and congestion-free operations. Here is a picture that shows conceptually how they work together:
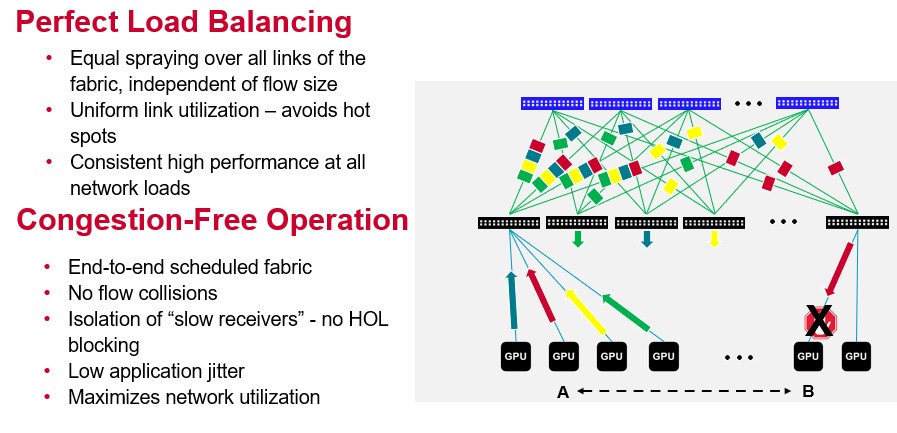
We highly doubt that any load balancing is “perfect” or network operation can be “congestion free,” but clearly, based on the results that Broadcom is showing, Jericho3-AI is going to do a better job on the AI training workloads than Tomahawk or Trident ASICs could and, based on this limited set of performance data, should give InfiniBand a run for the AI training money.
The question we have is this: Will the Jericho3-AI chip help with traditional HPC simulation and modeling workloads, as InfiniBand does?
“It depends on the type of HPC,” Del Vecchio says. “But certainly if the throughput is important for the application, absolutely. And HPC applications would also get those benefits where you wind up with a congestion free operation, very good load balancing, and utilizing the links far more efficiently. AI tends to be a bit more focused on the raw throughput of the whole network as compared to HPC, where it’s the end to end latency that matters. HPC has a lot of very short messages, and so the message rate is very key. So there are some differences. But the key thing about making sure that you have things load balanced, if you don’t have congestion – those are going to be equally applicable to both AI and to HPC.”
The Jericho3-AI switch chip is sampling now and is expected to have a relatively fast ramp like the Tomahawk5 did.




I though large buffers were the enemy of low latency. Maybe I don’t understand AI training. Are there aspects such a feed forward for which larger buffers are better?
It must be the case or this would be a Tomahawk variant.
I think that it is because during training, one deals mostly with dense (full) weight matrices for the NN layers. As with HPC’s HPL dense-matrix benchmark; latency is less critical for this than bandwidth as you can pretty much batch-burst the needed data into caches or buffers, for the computational units, karate-style. Once the ANN is trained on its humongous dataset, one may want to prune it (esp. for weight storage efficiency) resulting in sparse weight matrices, to be used for inference. The inference situation may then be similar to that of the sparse-matrix HPCG benchmark of HPC, where latency is more critical, and some form of memory-access kung-fu becomes valuable. NVIDIA has developed some special sparsity-support-hardware for this purpose if I’m not mis-mixmetaphoring (along with adaptive 4-bit quantization, and more, as discussed in recent TNP pieces).
Patience young gracehopper, post-exascale kung-fu gastronomy cannot be rushed; to wit, AI-formulated plant-based cheeses will not hit shelves until 2024 (Bel Group and Climax Foods). According to nVidia dev blog meditations (Yamaguchi & Busato, 2021):
“sparse linear algebra […] does not provide competitive performance [yet …] when sparsity is below 95% […] due to […] scattered memory accesses”
300 PhDs a Shaolin Temple did not hence make(?) … and is a bird in the hand really worth two stoned (or vice-versa — as in the next TNP article)?
Juniper Express5 is more promising, doubling Jerico3 capacity.
We all heard before the theoretical scale of Jerico2 – in reality it wasn’t even close!
Looks like another chip with great marketing but not really optimised.
“there is nothing in the Microsoft architecture that _does not prohibit_ it from moving to a fabric based on the Broadcom Dune StrataDNX family of which Jericho3-AI and Ramon 3 are a part”
“does not prohibit” -> prohibits
Correct.
So many questions but I’ll start with this one:
If a fully scheduled fabric offers (near) perfect LB and congestion-free operation then why exactly do I need deep buffers?
Note: Those deep buffers come with an additional cost due to the off-chip memory requirement.
It seems to me they’re just trying to repurpose an existing chip with a 15+ year old architecture (i.e., you’re paying for the additional packet memory whether you need it or not), throw “AI” on the end of the name (because we all know the mere mention of “AI” and your stock increase 20% overnight), and inevitably force you into a vendor lock-in strategy.
The architecture, and how it got there, only matters inasmuch as it beats InfiniBand on real-world AI applications and if it is also cheaper, then there ya go. Sauce for the goose, Mr Savik.
Your options for building out the most cost-effective AI fabric are not limited to IB vs DDC. In fact, you can successfully leverage the huge investment in the massive, multi-vendor front-end DC fabric that already exists today by focusing the solution to emulating a lossless, low latency network on the endpoints. Of course, it requires the architects of said DC fabric to have the ingenuity and foresight to do so. More importantly, it’s already being done at one very notable hyperscaler.