

Whenever one company buys another, every product line, every research project, and every employee is ultimately in play. But when Hewlett Packard Enterprise bought supercomputer maker Cray in May 2019 for $1.3 billion, it really did want all of Cray. And HPE absolutely intends to make investments in the key technologies underpinning the Cray product lines for many generations – including the Slingshot interconnect that got Cray back into high-end networking after a hiatus of several years as sold off its prior interconnects to Intel.
While there have been some key employee departures – notably, former Cray chief executive officer Pete Ungaro retired last year, and both former Cray chief technology officer Steve Scott and advanced technology architect Dan Ernst have taken bigtime architecture jobs at Microsoft Azure – Scott is technical fellow and corporate vice president of hardware architecture and Ernst is principal architect working on future Azure cloud systems – the team that designed the current “Shasta” Cray EX systems that are ruling the early years of the exascale era and the Slingshot interconnect has been deployed on every single pre-exascale and exascale machine that Cray and HPE have sold thus far.
Back in the day, HPE used to make a lot of its own CPUs, switch ASICs, and a slew of other chippery, and over the years, it has backed away from these efforts to use commodity components from Intel, AMD, Mellanox, and a slew of others. And so it was natural for us to poke at HPE last October and suggest – half in jest, half in fear, and half in seriousness for a total of three halves – that maybe HPE would sell the Slingshot line off to Intel, which was in need of an HPC interconnect of its own.
Intel has sold off its Omni-Path HPC-focused and InfiniBand variant interconnect line to Cornelis Networks. Omni-Path was, of course, based on the combination of the TrueScale InfiniBand that Intel got through its $125 million acquisition of that product line from QLogic in January 2012 and the “Aries” interconnect at the heart of the Cray XC supercomputer line that Intel acquired in April 2012 for $140 million. While Intel acquired programmable Ethernet switch ASIC maker Barefoot Networks in June 2019, in the wake of Nvidia buying Ethernet and InfiniBand supplier Mellanox Technologies, and subsequently mothballed Omni-Path only a few months later, it has not been particularly interested in tuning up one of Barefoot’s “Tofino” family of ASICs specifically for HPC collective operations, although there has been some tuning for AI workloads. After its bad experience with the “Knights Landing” many-core CPUs and the Omni-Path interconnect that was tied to it, Intel is not all that interested in being an HPC prime contractor any more. So maybe Intel doesn’t need to control an interconnect the way it used to need to.
HPE and Nvidia do want to be prime contractors, as does Atos, which controls the BXI interconnect that has its origins at Sandia National Laboratories. Fujitsu is also a prime contractor with its A64FX Arm processors and the very much co-designed Tofu D interconnect. None of this is a coincidence, and that, ultimately, is why HPE is not only keeping control of the Slingshot interconnect, but is investing in several more generations right now and has a robust roadmap that it can hold up against to any of its competitors in HPC.
Not that it is going to show this roadmap to the public, mind you. (Even though we think it should.) But Marten Terpstra, senior director of product management for the High Performance Networks, HPC, and AI business group at HPE, wants to make it clear that the system OEM is in it for the long haul with the Slingshot interconnect.
“We very clearly see Slingshot as one of the foundational, differentiated capabilities of our HPC and AI environments,” Terpstra tells The Next Platform. “The Rosetta switch ASIC has been out a good year and half and the Cassini network interface card is now going through its first large scale deployments. Those ultimately go hand in hand, and there are future generations that we can’t talk about yet, but we have invested in and are in active development of the next generations of both.”
Specifically, Terpstra says that HPE is working on the next two generations of Slingshot, and Gerald Kleyn, president of systems and platforms at the HPC and AI business group, adds that roughly half of the engineering team are working on the next-generation Slingshot ASICs for switches and network adapters as well on fleshing out the low-level software development kit that will make Slingshot more malleable and useful across more scenarios. Including, we think eventually, possible deployment at hyperscalers and cloud builders. Microsoft Azure would seem to be a shoe-in for Slingshot, with Scott and Ernst designing next-generation systems there. (As Kleyn puts it, “An SDK implies, in some sense, openness,” but also cautions that selling to hyperscalers and cloud builders is not an immediate priority, but rather a longer-term one.)
There is still some tuning to be done with the initial Slingshot stack, and that is why we think we did not see the 1.5 exaflops “Frontier” supercomputer, comprised of custom AMD “Trento” Epyc CPUs and AMD Instinct “Aldebaran” MI200 GPUs, at Oak Ridge National Laboratories appearing on the November 2021 Top500 supercomputer rankings.
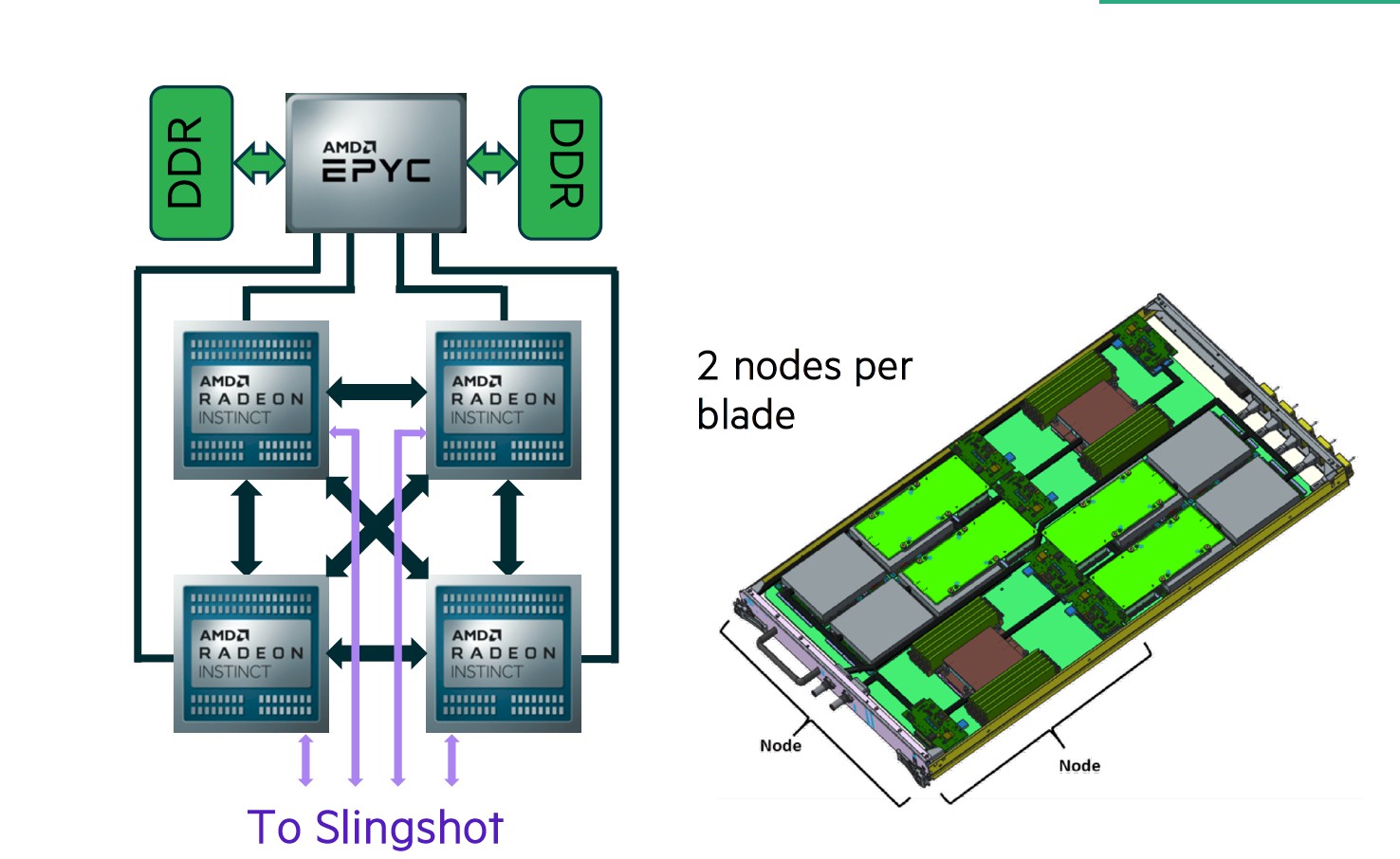
Our guess is that scaling across more than 9,000 nodes and more than 36,000 GPUs, which are directly connected to the Slingshot network rather than putting the network interfaces on the server host, is a bit trickier with congestion control and adaptive routing also running. The prior “Summit” supercomputer at Oak Ridge, based on 100 Gb/sec InfiniBand from Mellanox, only had 4,608 nodes. With each GPU in Frontier effectively being its own node, and the Epyc CPUs being more of a memory and serial processing accelerator for those GPUs, the scale is considerably larger on Frontier than it was on Summit. We do supercomputing to find limits and break through them, and it is reasonable to expect that the Cray team at HPE will sort it out. (They have fixed tough networking issues with the prior “SeaStar” XT3, “Gemini” XT4, and “Aries” XC interconnects, after all.)
Some review of the current Slingshot hardware is in order before we get into the possible future that HPE has in mind for this interconnect.
Cray unveiled the work it was doing on the Slingshot interconnect back in October 2018, but had started that work many years before and, interestingly, was at work on it back in early 2016 when we talked to Scott about the evolution of HPC interconnects at Cray. We spoke to Scott in an interview at SC18 later that year about bridging the HPC and hyperscale divide with interconnects, and when Scott have a keynote presentation at the Hot Interconnects conference in August 2019, we drilled down into the “Rosetta” ASIC architecture, talking about how Cray had taken its adaptive routing in the SeaStar, Gemini, and Aries interconnects, merged it with the congestion control it got from the Gnodal acquisition in 2013, and created an Ethernet switch chip that brought HPC features to standard Ethernet.
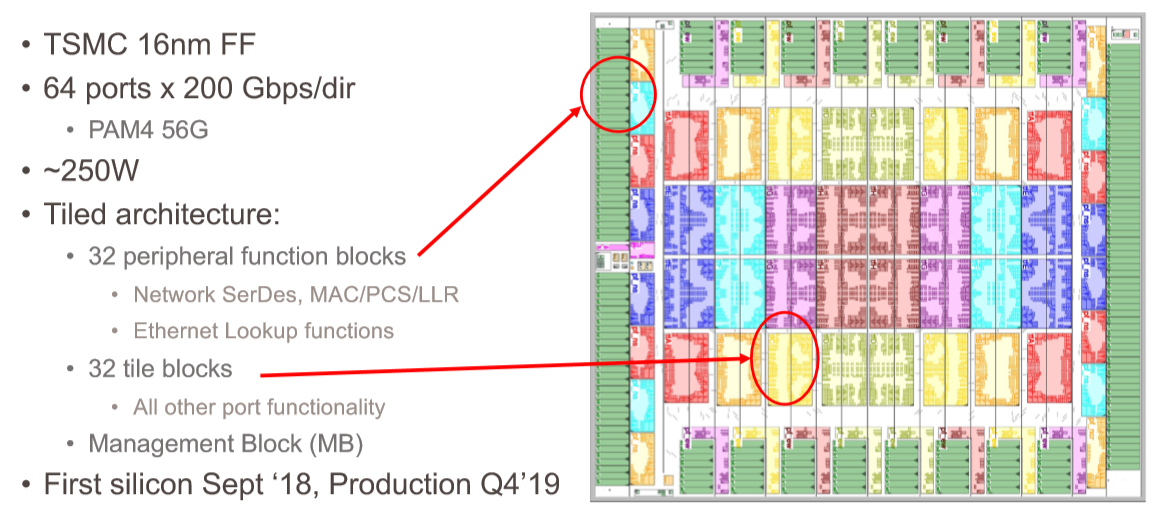
The Rosetta chip has 64 ports running at 200 Gb/sec, and is etched using 16 nanometer processes from Taiwan Semiconductor Manufacturing Co. The SerDes on the ASIC have 25 Gb/sec signaling and with PAM4 encoding provide an effective 50 Gb/sec per lane. Four lanes per SerDes makes a 200 Gb/sec port. (We have ignored the incremental bandwidth that is in the signals to cover encoding. The signals really run at 28 Gb/sec, with 56 Gb/sec effective, per lane.)
The Rosetta ASIC can support up to 279,000 endpoints in total with a three-layer network, and while Cray uses a dragonfly topology in the Shasta systems, it can be set up to support fat tree, torus, flattened butterfly, and other topologies. Early performance results back in 2019 showed Slingshot holding toe-to-toe with 200 Gb/sec HDR InfiniBand on networks with very little congestion. Since the summer of 2020, Cray and HPE have been trying to get the HPC industry to rally around its GPCNet network benchmark to stress test all of the HPC interconnects to show how they compare, but thus far Nvidia has not been particularly interested.
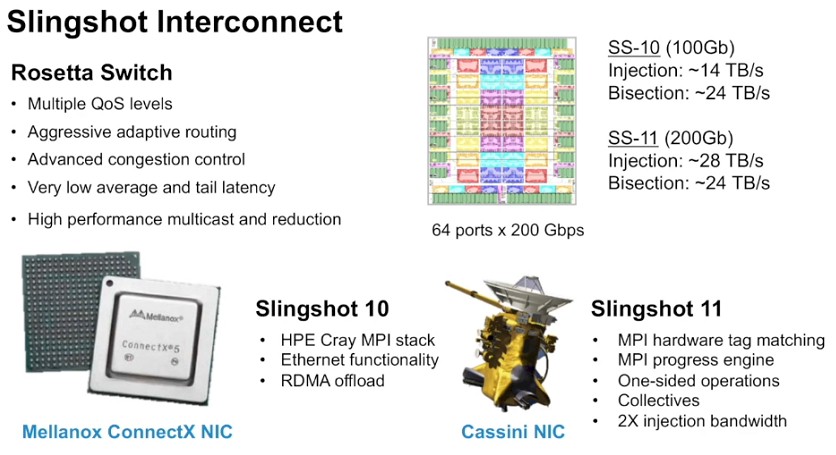
The Cassini network interface cards were not done in 2020, and so early Slingshot customers paired up the Slingshot switches with 100 Gb/sec NICs that were actually Mellanox ConnectX-5 NICs in either the PCI-Express card version or the embedded version out down on system boards. This was called Slingshot 10. With Slingshot 11, the Rosetta switch ASIC stayed the same, but the port speed was bumped up to 200 Gb/sec and that doubled up the injection speed of the network to around 28 TB/sec. The Slingshot 11 setup also had a bunch of specific MPI accelerations, as shown in the chart above.
This big news recently is that HPE is has combined its high-density Apollo 2000 and Apollo 6500 systems with the Slingshot interconnect, the ClusterStor E1000 storage arrays, and the Cray Programming Environment (a full Linux and compiler stack aimed at HPC workloads) to create the Cray XD line. The machines can be equipped with Slingshot 10 or Slingshot 11 interconnects using PCI-Express NICs, and also make use of an air-cooled Slingshot switch. HPE’s ProLiant DL servers of servers are also in the process of being qualified to run the air-cooled versions of the Cassini Slingshot 11 NICs.
In general, it takes three to four years to bring a switch ASIC and matching NICs from concept to market, and there is no reason to believe that HPE will be too different from the likes of Broadcom, Cisco Systems, Nvidia, Intel, Marvell, and a handful of others in keeping a steady pace of bandwidth expansion and feature improvements in their switch and adapter chips. It is nearly impossible to lower latency by much, and vendors are doing things to make networks more efficient, such as the congestion control and adaptive routing that has been under development at Cray for decades and that has reached a level of maturity with Slingshot.
HPE has a lot of different levers to pull as it puts together the next two generations of Slingshot and thinks about a third and fourth.
There are process node shrinks to 7 nanometers, 5 nanometers, and 3 nanometers than can provide the foundation of future Slingshot switch ASICs, and it is reasonable to assume that Cray, like others, will offer chiplet architectures that keep SerDes on higher, more mature processes that work better for signaling – we think SerDes at 7 nanometers will persist for a while – while breaking free packet processing engines and other network functions into chiplets that can be shrunken and made more cheaply and run more efficiently. This same thing is happening on CPU packages, with memory and I/O controllers staying back on process nodes while the cores keep shrinking. Running I/O on smaller transistors causes all kind of problems, and this is why we think networking engine as well as compute engine sockets will keep getting bigger and, eventually, taller. There are also other encoding tricks – PAM8 and PAM16 are a possibility – to coincide with faster raw signaling, moving from 25 Gb/sec to 50 Gb/sec to 100 Gb/sec. There are a couple of different paths to 400 Gb/sec, 800 Gb/sec, and even 1.6 Tb/sec port speeds for HPE’s Slingshot, just as there are for other Ethernet and InfiniBand interconnects.
What HPE does on the Slingshot roadmap depends on a lot of things, but it is not just a drive for raw bandwidth such as what Broadcom, for instance, chases every two years with its “Trident” and “Tomahawk” switch ASICs.
“Broadcom’s market is datacenter networking, and networking only,” explains Kleyn. “Whereas for us, we are building a system. And so the steps we take, and the timing, is tied to what you can do on the compute platform and what kind of speed can you get into and out of it. So we are tightly linked to PCI-Express 5.0 and PCI-Express 6.0 and when it makes sense to move to these – and we have to look at CXL on top of those.”
“When Broadcom builds its really high end systems, they are aggregated devices being fed from two or three layers’ worth of speed up along the network,” Terpstra elaborates further. “But Slingshot is way closer to the actual compute endpoints, and we are very much tied to what you can get into and out of an endpoint. That really determines our edge speed and therefore the speed of the ASIC that sits behind it. So you have to be careful not to make speed assumptions for Slingshot based on the roadmaps of Broadcom and others.”
But, by the same token, when you give HPC and AI applications more bandwidth, they can often make use of it – unlike hyperscale analytics and infrastructure applications, which don’t need more than 25 Gb/sec or 50 Gb/sec ports coming out of their servers, much less 100 Gb/sec ports. With the hyperscalers and cloud builders, the bandwidth leaps in each Ethernet ASIC generation allow for fatter pipes for datacenter interconnects and higher radix switches that lower the per-port cost of a 100,000 node datacenter Clos network because huge numbers of ASICs are eliminated with each doubling of bandwidth. In some cases, with HPC workloads, having more ports going into a system is better than having one fatter pipe.
We are curious how HPE will balance all of these opposing forces with Slingshot 20 and Slingshot 30, as well as Slingshot 40 and Slingshot 50.




Be the first to comment