
If there is anything that hyperscalers and cloud builders value more than anything else, it is regularity and predictability. They have enough uncertainties to manage when it comes to customer demand that they like for their systems to behave as deterministically as possible and they like a steady drumbeat of innovation from their silicon partners.
In a way, the hyperscalers and cloud builders created the merchant switch and router chip market, and did so by encouraging upstarts like Broadcom, Marvell, Mellanox, Barefoot Networks, and Innovium to create chips that could run their own custom network operating systems and network telemetry and management tools.
These same massive datacenter operators encouraged upstart switch makers such as Arista Networks, Accton, Delta, H3C, Inventec, Wistron, and Quanta to adopt the merchant silicon in their switches, which put pressure on the networking incumbents such as Cisco Systems and Juniper Networks on several fronts.
All of this has compelled the disaggregation of hardware and software in switching and the opening up of network platforms through the support of the Switch Abstraction Interface (SAI) created by Microsoft and the opening up of proprietary SDKs (mostly through API interfaces) of the major network ASIC makers.
No one has benefitted more from all of this openness than Broadcom. And because of the heated competition in the merchant networking silicon market and now the addition of Silicon One merchant switch and router chips from Cisco, Broadcom has had to be relentless in delivering anywhere from six to eight switch and router chip variants every year to address all of the needs of its enterprise, telco, service provider, hyperscaler, and cloud builder customers.
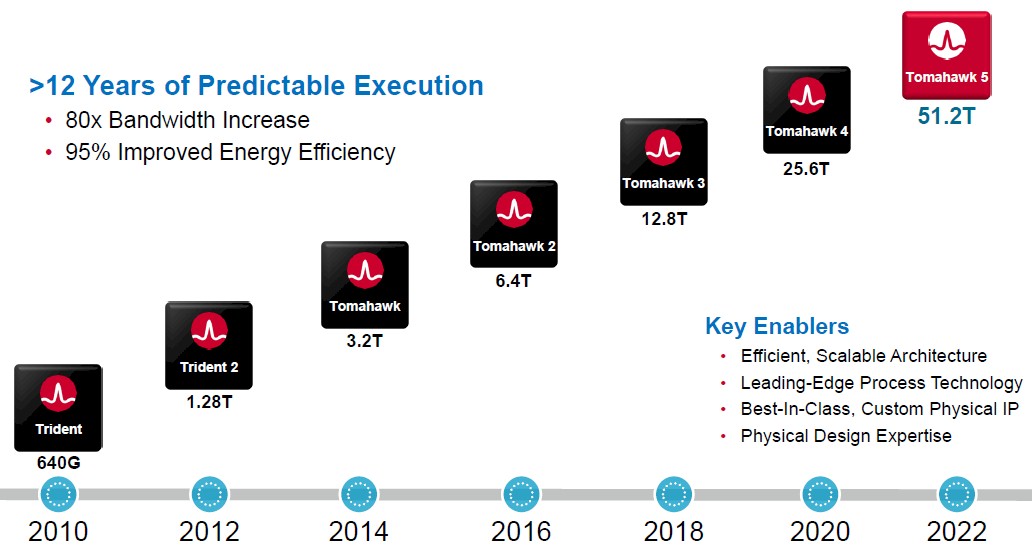
Broadcom started out with its “Trident” line of switches, bought its way into deep packet switching and routing with the “Jericho” line, and eventually had to fork its datacenter switch line to include a cost-optimized, high performance, no frills “Tomahawk” line. And it is these three switch chip families that still make up the heart its datacenter networking chip business today.
Peter Del Vecchio, product manager for the Tomahawk and Trident lines at Broadcom, tells The Next Platform that many customers mix and match ASICs across their networks. For instance, a lot of cloud builders who sell compute and network capacity for a living (many of whom are also hyperscalers that have advertising-driven or subscription-driven services at the software layer) want to offer bare metal servers or move enterprise applications into their systems. And therefore they might chose a Trident ASIC for their top of rack switches and then use the Tomahawk ASICs in the rest of the network fabric above it. At higher levels of the network fabric, some cloud builders and hyperscalers choose the Jericho ASICs because of its gigabytes of packet buffers, which helps deal with congestion and the scalability of Internet routing tables. But in general, Trident is aimed at enterprises that need to support the widest array of protocols, Tomahawk is aimed at hyperscalers who are focused on cost per bit, thermals, and scale, and Jericho is aimed at telcos and service providers who are managing huge network backbones.
All of these Broadcom ASIC families share a single set of APIs across a single SDK as well as support for SAI interfaces, which provide a modicum of compatibility across the switch ASIC vendors that have been compelled by the buying power of the hyperscalers and cloud builders to support SAI.
With the “Tomahawk 5” StrataXGS, Broadcom is right on time with another doubling of bandwidth, and is doing so with a monolithic chip design etched in the 5 nanometer processes from foundry partner Taiwan Semiconductor Manufacturing Co.

This single chip Tomahawk 5 can drive 51.2 Tb/sec of aggregate bandwidth, double that of the Tomahawk 4 that was unveiled two years ago – right on the two year cadence that Broadcom likes to keep its switch ASICs moving on. With the Tomahawk 4, Broadcom had one version that had 512 SerDes running at 50 Gb/sec using PAM-4 modulation to drive a total of 25.6 Tb/sec of bandwidth, another one that had 256 SerDes that ran at 100 Gb/sec, and a bunch of variations that had a smaller 12.8 Tb/sec of aggregate bandwidth for more modest use cases. With the Tomahawk 5, the 512 SerDes that wrap around the packet processing engines and buffers are running at 100 Gb/sec speeds, yielding that 51.2 Tb/sec of bandwidth. We can expect a bunch of different variations of the Tomahawk 5 family of ASICs – these have not been revealed as yet. What we do know is that the Serdes design for the Tomahawk 5 is brand new, and for good reason.
“This generation of SerDes was designed from the get-go to be very flexible,” Del Vecchio says. “This 100 Gb/sec SerDes can push copper up to 4 meters, and we can handle front panel optical pluggable modules, of course, and we can also drive our co-packaged optics.”

We have caught wind of the co-packaged optics that Broadcom has been working on, and will be doing a follow up on that. But suffice it to say, Broadcom thinks that it can drive the cost of switching down with co-packaged optics – something that not everyone, including and maybe especially including Andy Bechtolsheim of Arista Networks, believes is possible during this generation of switches. We can assure you that Arista Networks will be at the front of the line peddling switches with co-packged optics if the economics works out the way Broadcom says they will.
The important thing for the hyperscalers and cloud builders, and what drives these generational transitions in networking is that the cost per bit moved goes down and the watts per bit moved comes down, too. With the Tomahawk 5 ASIC, Del Vecchio says that Broadcom can deliver under 1 watt per 100 Gb/sec of signaling.
The Tomahawk 5 chip can drive 64 ports running at 800 Gb/sec, 128 ports running at 400 Gb/sec, and 256 ports running at 200 Gb/sec. These days, the hyperscalers and cloud builders like switches with 128 port radix running at 400 Gb/sec per port, with 64 ports going down to the servers in the rack and 64 ports going up into the spine layer of the network fabric. But that could change depending on how far down they want to push the economics of a port. Some of the flat machine learning clusters will just use 256 ports running at 200 Gb/sec
In theory, a single Tomahawk 5 could be carved down with cable splitters to 512 ports running at 100 Gb/sec, which would radically cut the cost of a 100 Gb/sec Ethernet port. But the contraction in switch ASIC count that is enabled just by the doubling of the bandwidth from generation to generation is enough to help keep cost per port down as bandwidth doubles.
To be specific, here is what the jump from Tomahawk 4 or indeed any other 25.6 Tb/sec switch chip to Tomahawk 5 gets you in terms of creating 51.2 Tb/sec of non-blocking aggregate bandwidth for each:
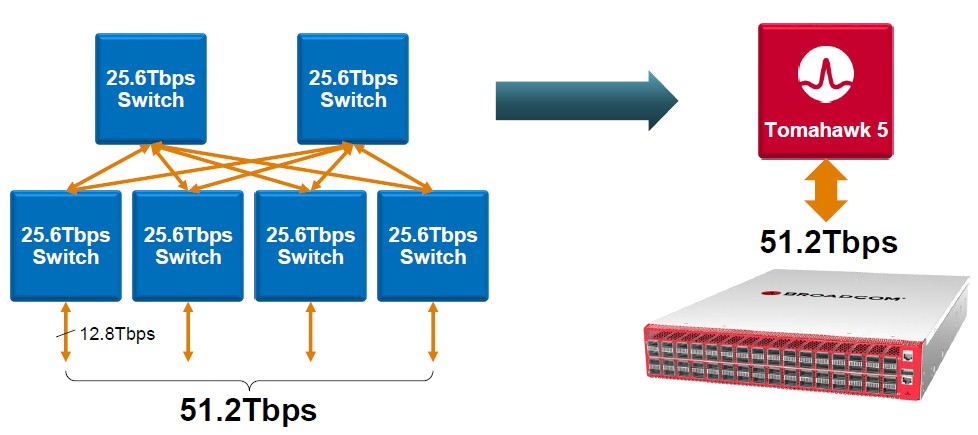
It takes six 25.6 Tb/sec chips interlinked into what amounts to a leaf/spin network inside of a switch to deliver the same ports that a 51.2 Tb/sec chip can do all by itself. This has huge economic and thermal implications. In general, in a generational move at the switch level, a port has 2X the bandwidth and costs around 1.5X as much per port initially and eventually falls to 1.3X as much per port over time. Initially, the cost per bit transferred only goes down by 25 percent in this scenario, which is not great but it is kind of like a Moore’s Law improvement, and you do get 2X the bandwidth per port, which is worth something. But the big benefit it that it costs 4X less to provide a total of 51.2 Tb/sec of aggregate bandwidth. So the network can scale much further or just cost less, depending on the topology and how many ports you need. (A typical cloud and hyperscaler datacenter is like 100,000 machines.) This kind of contraction is how Broadcom has been able to drive an 80X increase in bandwidth over a dozen years, and cut the energy consumption data movement (in terms of joules per bit moved) by 95 percent over that same time period.
This pace of improvement is what makes modern hyperscale and cloud networking economics work. And you can see it in the market data for the 400 Gb/sec ramp and you will see it in the 800 Gb/sec ramp that will start in about a year or so (it takes about that long to go from a switch ASIC sampling to deployment at hypercalers and clouds) and the 1.6 Tb/sec ramp that will start, if all goes well, about two years after that. Take a look:
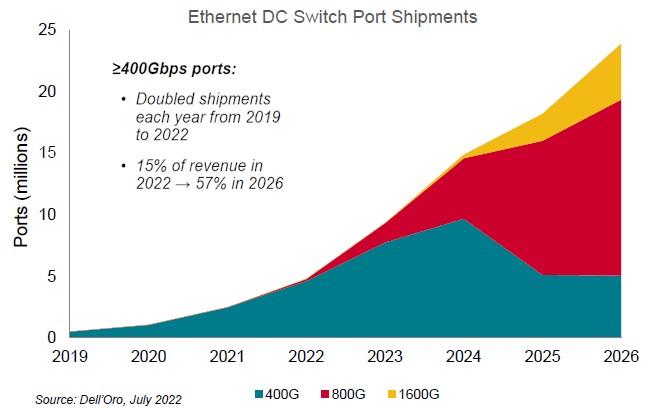
Del Vecchio says that the volumes of 400 Gb/sec ports doubled each year between 2019 and 2022, and now accounts for about 15 percent of total datacenter switching revenue. The market for ports that run at 400 Gb/sec or faster speeds is expected to grow to 57 percent of revenues by 2026, according to market researcher Dell’Oro, cited in the chart above. Del Vecchio says that most of the 800 Gb/sec ports that will initially be sold with splitters breaking them into two 400 Gb/sec ports and later the market will move to native single 800 Gb/sec for new ports and the existing ports can be unsplit to also yield 800 Gb/sec ports.
One of the things that Broadcom thinks is a big differentiator for the Tomahawk 5 chips is the way it does buffering inside the ASIC. Broadcom is using a shared buffer inside of Tomahawk 5, compared to a sliced buffer inside of an unnamed competitive design:
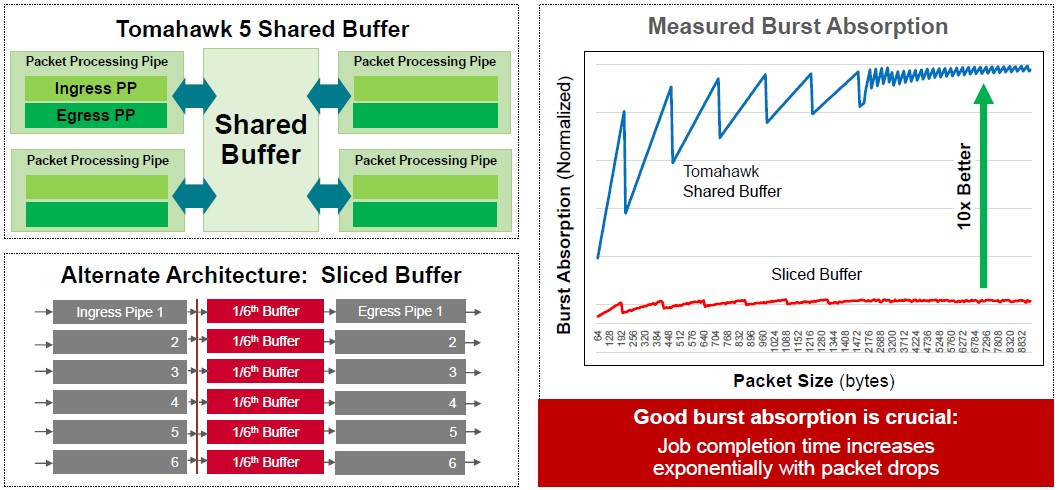
“Our shared packet buffer has excellent burst absorption,” explains Del Vecchio. “What is extremely important for machine learning training is congestion control, the rate at which they can ingest data from different sources into the systems running the machine learning frameworks. We have high precision time synchronization, which can be used to synchronize jobs throughout the network. We also have hardware-based link failovers, and we can figure out links that are going to fail by carefully watching codeword errors in the forward error correction that is necessary because of PAM-4 encoding. You can look and see that a link is degrading over time. For the hyperscalers and clouds, they are still mostly Clos and fat tree topologies, but we can do this for torus, dragonfly, and other interconnects.”
The Tomahawk 5 chip is sampling now, and will ramp over the next year or so.

Nvidia Hints At Upcoming AI-Focused Spectrum-4 Ethernet
It is no surprise at all that Nvidia’s datacenter business is making money hang over fist right now as generative AI makes machine learning a household word and is giving us something akin to a Dot Com Boom in the glass houses of the world. It is also no surprise …
Upstart Xsight Labs Raises Up The Programmable Switch Banner High
The best minds in networking spent the better part of two decades wrenching the control planes of switches and routers out of network devices and putting them into external controllers. We called this software-defined networking, or SDN, and it gave network operating centers a holistic view of the network and …

VMware Wants To Redefine Private Cloud With VCF 9
We all had been wondering what VMware would look like when it became part of Broadcom’s massive universe following the semiconductor giant’s $69 billion acquisition of the virtualization juggernaut. Now, we are finding out. The industry got a glimpse in June, when Prashanth Shenoy, vice president of product marketing for …
What is the switch Latency?
Timothy, any idea on TDP?
I can look into it.