

Last fall, supercomputer maker Cray announced that it was getting back to making high performance cluster interconnects after a six year hiatus, but the company had already been working on its “Rosetta” switch ASIC for the Slingshot interconnect for quite a while before it started talking publicly about it.
At the Hot Interconnects 26 conference in Santa Clara this week, which was hosted at Intel, Cray chief technology officer Steve Scott divulged many details about the Slingshot architecture and its Rosetta ASIC, the first implementation it is putting into the field.
As we discussed last fall when the Slingshot effort was revealed, pretty much putting the kibosh on Intel’s Omni-Path 200 effort, which has just been formally discontinued, as well as on the current “Aries” interconnect that Intel acquired back in April 2012 for $140 million and that, technically speaking, Cray is still selling. But not really. Cray is getting ready to ship its “Shasta” systems with the first generation Slingshot switches and their Rosetta ASIC in the fourth quarter, and the silicon is so good, according to Scott, that Cray can do so on the A0 stepping of the chips coming back from Taiwan Semiconductor Manufacturing Corp. It is very rare for an A0 stepping to go straight to customers, so that is remarkable in its own right.
Apparently, Cray didn’t design the HPC Ethernet protocol that is used on the Rosetta ASIC completely by itself, but worked with an unnamed third party Ethernet switch chip designer to come up with it. Scott is not at liberty to say who it might be, and it is not obvious from the Rosetta design who it is. The obvious and most neutral choice is (from Cray’s point of view) is Broadcom, which has the lion’s share of ASIC sales into the datacenters of the world today. Cray’s Rosetta chip bears some conceptual similarities to the “Tomahawk 3” ASIC, which at 12.8 Tb/sec of aggregate bandwidth can drive 64 ports at 200 Gb/sec and which does not have a deep packet buffer philosophy just like Cray’s Rosetta does not.
It is probably not Intel, either, that has partnered with Cray on the protocol design. Not given the experience Cray has had working with Intel in switching in the past seven years. Intel has not fielded an Ethernet switch chip of its own since it acquired Fulcrum Microsystems, a maker of high performance 10 Gb/sec Ethernet switch chips. (Intel bought Fulcrum in July 2011, and one of its founders, Uri Cummings, is chief technology officer of the Connectivity Group within Intel’s Data Center Group.)
Intel was in the process of taking technology from the Aries interconnect, which it bought from Cray for $140 million in April 2012, and marrying it to the QLogic implementation of InfiniBand, which Intel acquired in January 2012. That QLogic InfiniBand formed the foundation for 100 Gb/sec Omni-Path, which Intel has been selling since 2015, and 200 Gb/sec Omni-Path, which is not going to see the light of day. The CPU maker took a run at acquiring Mellanox earlier this year, lost out to Nvidia, which is paying $6.9 billion for the networking company, and then changed gears completely and acquired Barefoot Networks for an undisclosed sum. That Barefoot Networks deal just closed, and we expect to be talking to Intel’s top brass about the deal at The Next IO Platform event that we are hosting on September 24 in San Jose.
Cray could have partnered with Mellanox on the HPC Ethernet protocol. Mellanox is in the process of making tweaks to the Spectrum-2 ASIC design to double it up to 12.8 Tb/sec as Mellanox was already planning to do. Barefoot Networks has its Tofino 2 design, announced late in 2018 and having a 12.8 Tb/sec variant and a completely programmable pipeline. Innovium, which has developed an ASIC called Teralynx aimed at hyperscalers and cloud builders that can drive 64 ports at 200 Gb/sec as well and that is starting to ship. But the Teralynx chip has a deep buffer design, just like the “Jericho” line of switch ASICs from Broadcom do. We think that probably means Cray did not partner with Innovium as the foundation of the HPC Ethernet protocol, either.
If we had to guess, we would say 75 percent it is Broadcom, 25 percent it is Mellanox. And considering that Broadcom has no interest in HPC networking as we know it – and Mellanox would have little interest in helping a competitor. Given the similarities between Rosetta and Tomahawk 3, we think Cray’s partner is Broadcom. (Both slingshots and tomahawks are primitive, hand-held weapons, too.) Whoever it is, Cray’s partner has apparently retained the rights to sell variants of the HPC Ethernet protocol – so we suspect that sooner or later, we will find out.
None of that is really important, even if it is interesting. The important thing is that Cray took an existing Ethernet protocol, substantially altered it for HPC and AI purposes, adding some of the ideas about congestion control that it got through its acquisition of Gnodal back in 2013 and expanded upon, and its own ideas in adaptive routing, which first came out in 1996 with the Cray T3D parallel supercomputer and which was in the market a decade ahead of the competition, and put them into this Rosetta ASIC. Cray is no stranger to high radix switches, either, with its “BlackWidow” YARC router in the X2 parallel vector supercomputer from 2007 having 64 ports and implementing a folded Clos network topology. Cray invented the dragonfly topology for its Aries XC systems precisely to try to eliminate as many costly optical links in a cluster as it could while still being able to scale a system uniformly.
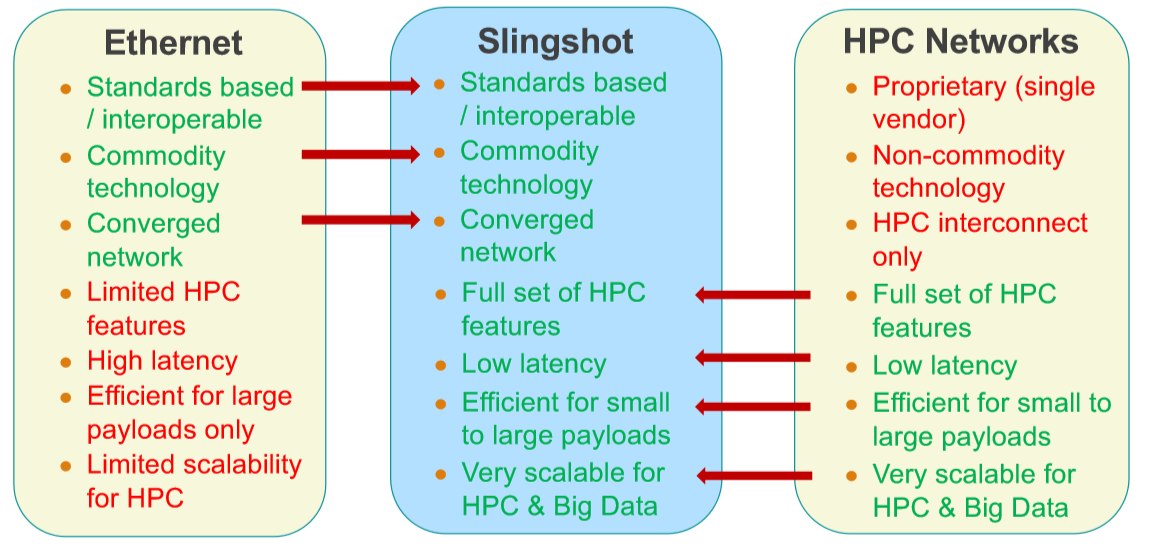
The key aspect of Slingshot is that Cray is not only embracing Ethernet as its networking standard going forward, but that it is creating a superset of Ethernet, which it calls HPC Ethernet, that makes Ethernet behave more like a traditional HPC interconnect while at the same time improving adaptive routing and, as Scott put it, making a step function improvement in congestion control over what is available in Aries, InfiniBand, Omni-Path, or any of the various Ethernet ASICs out there today. All of the best ideas it has had at the heart of its systems – high radix switching, dragonfly topology, adaptive routing, congestion control – are being brought to bear with the Slingshot interconnect.
And that is why Cray has won three out of three of the exascale system deals in the United States. HPC and AI centers don’t have to choose between Ethernet and something else. The Rosetta ASIC can handle normal Ethernet frames or the trimmed down ones that are specifically created for HPC and AI workloads that embody the HPC Ethernet alternative. To use a metaphor, Rosetta can handle plain English or shorthand notation and translate between the two. (Hence the allusion to the Rosetta Stone in the codename of the ASIC and the switch that uses it.) The Slingshot interconnect can be deployed to great effect in a dragonfly topology as Cray wants to do in Shasta, or used in any other kind of topology as customers see fit, or hybrid topologies as well. It is just more flexible, and that is what is going to matter in the long haul.
Rosetta: The Feeds And Speeds
The heart of the first Slingshot interconnect is, of course, the Rosetta ASIC and the integrated and top of rack switches that Cray is building from them to create the Shasta systems. Like other shiny new switch ASICs supporting 100 Gb/sec, 200 Gb/sec, or 400 Gb/sec ports, Rosetta is using 56 Gb/sec signaling on the SERDES plus PAM-4 data encoding to push 100 Gb/sec (after encoding overhead) through each lane. That yields 32 ports at 400 Gb/sec, 64 ports at 200 Gb/sec (the sweet spot that Cray has chosen), and 128 ports at 100 Gb/sec. Hyperscalers and cloud builders probably would like to cut that down further, but can chop a port up using their SmartNICs if they want to give 25 Gb/sec or 50 Gb/sec to a server. HPC and AI workloads need more bandwidth than this, and hence it really is 200 Gb/sec coming out of each endpoint in the Shasta architecture and into the Rosetta ASICs.
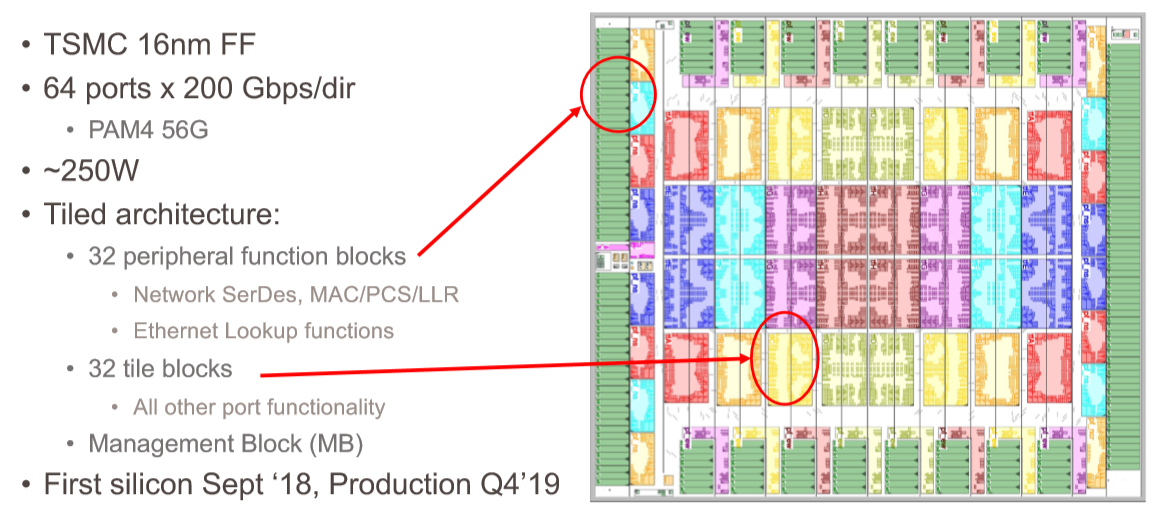
We have never seen the Tomahawk 2 and Tomahawk 3 ASICs from Broadcom, but we did catch a glimpse of a Tomahawk 1 ASIC back in late 2014:

There is certainly some similarity there, you have to admit. And Tomahawk 3 was etched in 16 nanometer FinFET from TSMC. (Tomahawk 4, which Broadcom has not announced yet, will no doubt use 7 nanometer TSMC processes, like the “Trident 4” ASIC for enterprise-class switches, which has been announced, does.)
The Rosetta ASIC has 32 tile blocks in the center of the switch, which implement the crossbar switching between the ports and other functions, plus 32 peripheral function blocks that provide the SERDES to drive the signals off the chip, plus the MACs, physical coding sublayer (PCS), and least loaded routing (LLR) and Ethernet lookup functions.
We suspect that what Cray has done is rejiggered the routing crossbars inside of the Rosetta ASIC from plain vanilla Ethernet to be more reflective of what an HPC and AI supercomputer needs. (Scott is world-renowned expert in routing, which makes sense. The YARC router in the Cray X2 is not only Cray spelled backwards, but is short for Yet Another Router from Cray.)
As you can see from the diagram above, there are four rows of eight tiles that implement the intra-switch routing, with two switch ports handled per tile. (We presume you could make it one port per tile at 400 Gb/sec or four ports per tile at 100 Gb/sec.) Here is what it looks like:
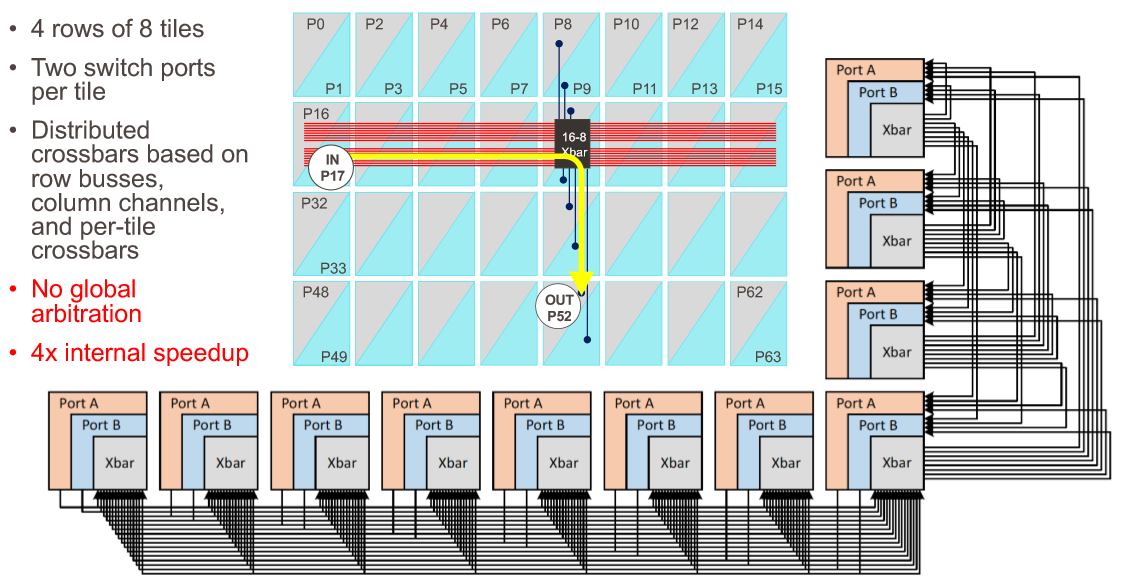
And this is what Scott had to say about it:
“The tile architecture allows you to build a 64 port router, but you never have to build the 64 port arbiter anywhere in the system. Everything is done hierarchically. So there are eight rows. Sorry. Four rows of eight tiles, with two switch ports per tile. So we’ve got a profitable port zero in port one here for two or three there. And then the distributed crossbar is based on a set of row busses and column channels with per tile crossbars. So every port has its own row bus, which communicates across its row, and then every tile has this that has a 16-input, 8-output crossbar, which is used to do corner turns, and then a set of eight column channels that feed up to the eight ports that are contained in that column. So if you want to go from, say, input port 17 to output port 52, you basically route along the row bus, you go through a local crossbar which is only a 16 to 8 arbitration, and then up a column channel to the other port. In terms of the total routing through all the set of distributed crossbars, there is four times more internal bandwidth than there is external bandwidth. And what that basically means – and we have verified this in the simulation and running this in the lab – is that you can pretty much put any arbitrary permutation of traffic through this thing and it does it does very nicely keeping up with all the ingress.”
There are actually five separate distributed crossbars implemented on the Rosetta ASIC inside of those tiles, each handling a different aspect of the switching traffic, like this:
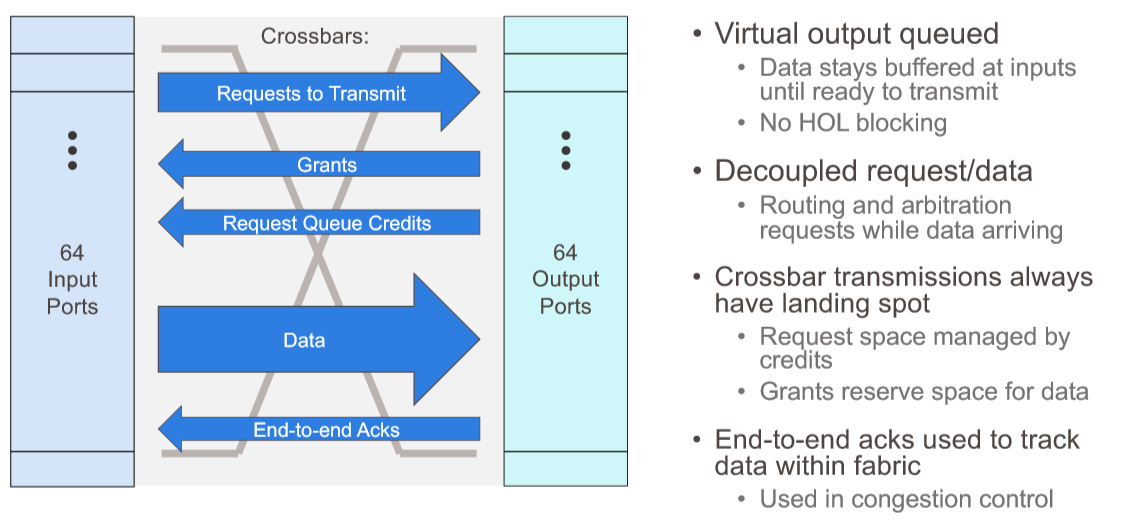
These routing crossbars are the secret sauce that makes a Rosetta ASIC very different from standard, merchant silicon like Broadcom’s Tomahawk 3 ASIC. Bigtime different. Hyperscalers and cloud builders wish they had something this good, and if they can get over their not invented here syndrome, they might actually use switches based on Rosetta, which can certainly scale to the size of one of their datacenters – and then some. Almost three of them, in fact, at a maximum of 270,040 endpoints in a full dragonfly topology, and with a maximum of only three hops over the network between any two endpoints, and depending on the configuration, somewhere between 80 percent and 90 percent of the links being short and cheap copper cables instead of long and expensive optical ones. Like this:
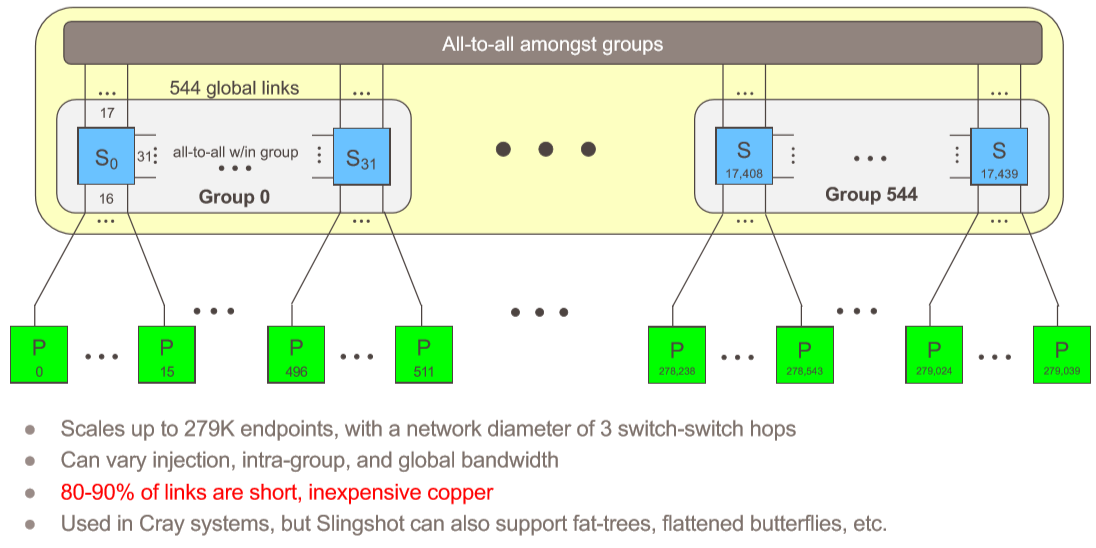
There are some important aspects to these distributed crossbars. First, this routing mechanism does not cause head of line blocking, which plagues many other switch architectures. The routing path for data is determined before it is let into the routing tiles, so it always knows where it is going and the order can be managed before it is routed, not after the fact where packets can stack up in the wrong order and cause all kinds of congestion. (When you say that out loud, it makes sense, and the wonder is why this has not always been the way Ethernet has worked.) The landing spot for data is always known before it moves across the switch and requests to transmit and grants to transmit are separated on different crossbars so they don’t bump into each other. Data has its own crossbar, too, and then finally the end to end acknowledgments, which are used to do the new congestion control, track data across the entire Slingshot fabric. To put it another way: the state of the network is managed inside of the switches, in real time, instead of out of band like Google does with its Andromeda network controller. The congestion management in Slingshot tracks all outstanding packets between every pair of endpoints, and it has big enough buffers on the front end to be useful and applies just enough backpressure on the transmissions to keep congestion from getting out of hand – what Scott called “an itchy trigger finger.” The congestion control and quality of service features of the Slingshot interconnect are suitable for dynamic traffic – meaning it is changing all the time and often unpredictably – and is specifically aimed at reducing mean latency and those outlying tail latencies that can kill application performance and stall big clustered systems. (That tail latency is an obsession of Google’s, and it is why it created its Andromeda software-defined networking stack.)
So how good is Slingshot? Here are a few data points for now, but we will be getting into the benchmark results that Cray has done in a separate story.
First, let’s compare Slingshot based on the Rosetta ASIC to its HPC peers. Here is how it stacks up:
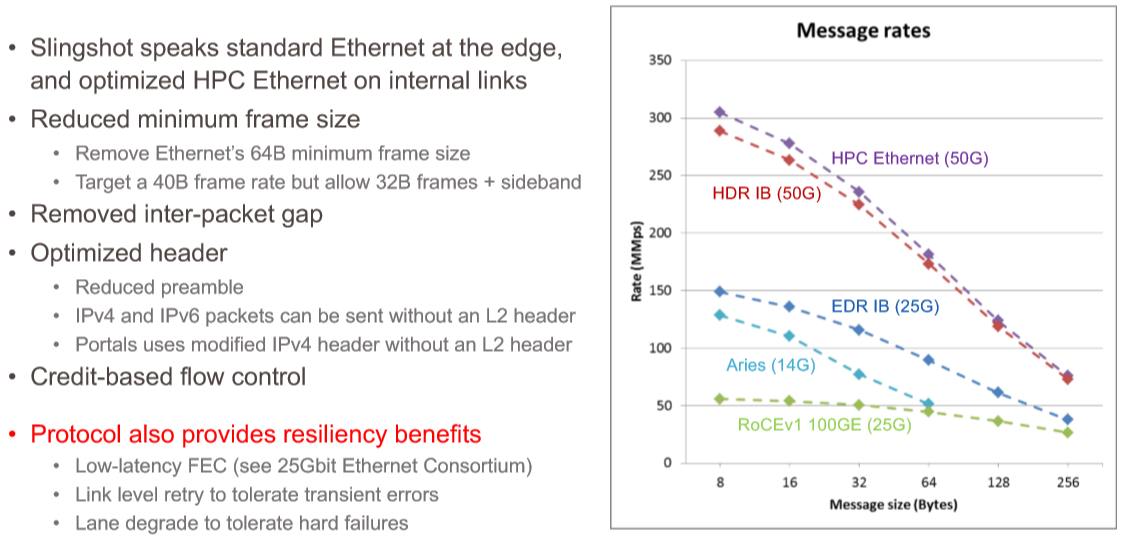
Many HPC and AI applications have relatively small message sizes, which are supported by InfiniBand as well as Aries and modern 100 Gb/sec Ethernet using the RoCE variant of RDMA. But not all interconnects do well on small frame sizes and Aries did not have large frame size support, making it unsuitable for plain vanilla, Ethernet-style frames that can be larger. With the HPC Ethernet protocol, Cray is removing the 64 byte lower limit for Ethernet and supporting 40 byte frames and a special 32 byte frame with the spare 8 bytes used for sideband stuff do help with congestion control.
As you can see from the chart above, 100 Gb/sec Ethernet with RoCE does about what you would expect against 200 Gb/sec InfiniBand from Mellanox and 200 Gb/sec Slingshot from Cray with large frame sizes, but it really sucks at small message sizes. Even Aries, with 14 Gb/sec signaling compared to the 25 Gb/sec signaling on this Ethernet, can handle a message rate that is more than 2X with small frames. Aries, as you can see, holds its own against 100 Gb/sec EDR InfiniBand – it is a little bit slower, but it is also many years older. But Slingshot is able to go toe to toe, frame size to frame size, in a nice smooth curve all the way down to 8 byte message frames and all the way up to 256 byte frames.
Aries, even Scott admitted, did not have very good congestion control. But the simulations for Slingshot, which he shared at Hot Interconnects, look very promising indeed. Take a gander at this:
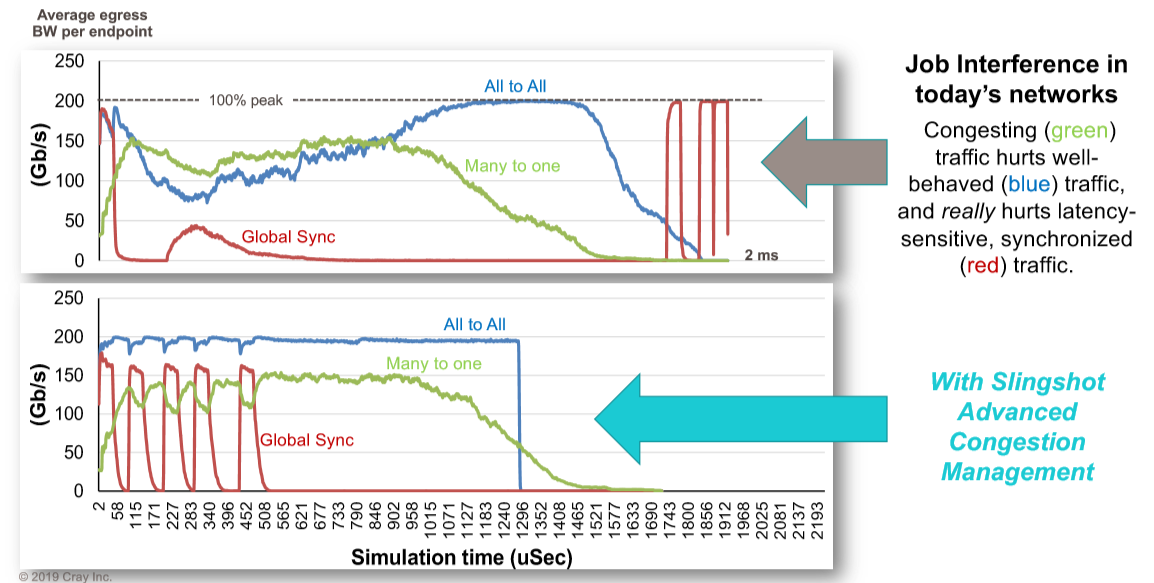
There are three workloads running in the system. The red line is a spikey global synchronization routine, the green one is a many to one collective operation, and the blue one is an all to all scatter operation. This shows Slingshot running with congestion control turned off and then turned on. In the top scenario, the red workload spikes right out of the gate, wildly reduces the blue workload and pulls down the green workload. As they are crashing because of backed up packets, the global synchronization tries to send out another pulse, and it gets stepped on, and it goes totally flat as the blue all to all communication takes over and the green many to one collective finishes up, leaving it some breathing room. Finally, after they are pretty much done, the global synchronization spikes up and down like crazy, finishing its work only because it pretty much as the network to itself. The whole mess takes 2 milliseconds to complete, and no one is happy.
Now, turn on the congestion control that is part and parcel of all that routing hardware and software Cray added to the ASIC. The workloads affect each other a bit, to be sure, but the global synchronization finishes in about 500 microseconds, the all to all scatter operation finishes in about 1.3 milliseconds, and the many to one collective finishes in about 1.5 milliseconds. Here is another simulation showing the latency of traces on the network with a bunch of applications running, some of them causing congestion:
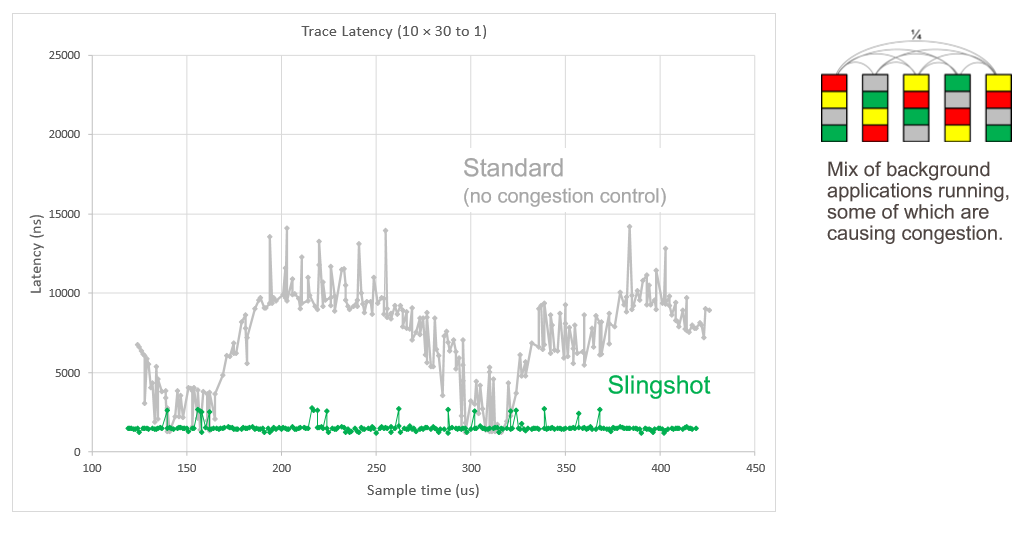
Everything runs smoother and seems happier with Slingshot. The more balanced performance of these very different workloads is made possible by that adaptive routing, congestion control, and quality of service software working in concert.
Next up, we will show some real-world benchmarks that Cray has done against prior generations of supercomputers against its test Shasta system in its lab.


Ethernet Switching Still Booming As Routing Soldiers On
If the datacenter is the computer – and it certainly is for hundreds of companies comprising somewhere well north of half of server sales worldwide – then the Ethernet fabric, consisting of switches and routers, is the backplane of that computer. And as a consequence of sales to the hyperscalers, …
NCSA Delta Supercomputer Adopts Slingshot But Forgoes Cray “Shasta” Design
When it comes to supercomputing in academia, the cost of a cluster is almost always an issue and this, coupled with the desire to drive as much compute as possible, drives architectural choices. A great example of this dynamic is the National Center for Supercomputing Applications at the Urbana-Champaign campus …
Frontier: Step By Step, Over Decades, To Exascale
Any time you build anything with more than 60 million parts, it is going to be a headache. And if you have to create a space in a datacenter and build an exascale system with all of those parts, each of which is crucial, during a global pandemic, it gets …
‘Rosetta’ is most commonly associated with the Rosetta Stone, which was not a weapon.
I realize that, of course. I was talking about Tomahawk and Slingshot.
It is wrong to call it Ethernet. The network protocol is marketed as “improved Ethernet” or in other words another proprietary network.
Not so fast. You can put any Ethernet NIC in a server and hook it up the the Rosetta switch and it can process regular Ethernet frames all day and all night, and in fact, Cray wants to do this so it can hook its machines up to any and all network-attached storage. It is only when it is attached to the Shasta/Slingshot NICs on its own servers that this HPC Ethernet variant kicks in and can do the smaller messages and other HPC features. As far as I know, the congestion control and adaptive routing work for the special Ethernet frames as well as normal Ethernet frames.
Not so fast too 🙂 the fact you have a an option in the switch to connect to standard Ethernet does not make it more suitable to HPC. There were other vendors in the past that did the same, and still do – have a network product that can connect to multiple network protocols. Ethernet is not the best choice for HPC, because of the many limitations is has. For HPC Cray has their own new proprietary network, which is being used when you connect the switches together, not only switch to slingshot nic. Having 2 modes – proprietary or standard Ethernet, does not mean you bring Ethernet to HPC. And of course all the proprietary features are on the proprietary network mode.
Mellanox has InfiniBand and Ethernet on the same adapter – does it mean they brought EThernet to HPC 10 years ago? It is 2 modes of a network device, same for Slingshot. Myricom had option to run Myrinet and Ethernet on their devices 15 years ago. Same for Quandrics.
Congestion control and adaptive routing are basic network functions. Why are we so amazed by such basic network functions that exist in many other networks for years? maybe because Cray did not had them in their previous generations?
As for the storage comment – why would Ethernet storage be the best option for HPC? food for thought.
Hi Ben. Thanks for your comments. The Rosetta switch uses an Ethernet physical layer, supporting standard Ethernet protocols as a baseline, and then negotiates enhanced features when connected to devices that supports them. The negotiated “HPC Ethernet” protocol is used between Rosetta switches, and with NICs that support it. The reason we call it HPC Ethernet, is that it’s a format that is very sympathetic to Ethernet and allows easy/efficient conversion back and forth. What this means is that a Slingshot network can (and is indeed intended to) connect to standard Ethernet devices at the edge, allowing full interoperability with the rest of the ecosystem, while employing the higher performance and reliability protocol internally. In contrast, Mellanox produces completely separate switches for IB and Ethernet, so an IB network will not interoperate with Ethernet NICs and switches.
All of the adaptive routing, QoS, and congestion control mechanisms in Slingshot work independently of the edge protocol. So you can still take advantage of the unique congestion control even though the interactions with the NICs use standard protocols. While data center congestion control mechanisms like ECN and QCN have been around for years, they’re not well suited for dynamic HPC workloads (hard to tune, fragile, not very stable across different communication patterns, etc.). The congestion control in Rosetta is quite different, providing faster convergence, greater stability, and fabric-wide freedom from HOL blocking. We think it’s a pretty significant step forward. At the same time, Rosetta can still interoperate with data center applications that are using ECN. Our internal congestion management mechanisms allow for more accurate ECN marking, distinguishing flows that cause congestion from those that pass through congested points.
FYI LLR is meant to mean Link Layer Reliability, not Least Loaded Routing.
Thanks for the comments. Supporting different network protocols is not a negative thing. Mellanox NICs (they had it also in previous switch generations I believe) support both Ethernet and InfiniBand on the same port. Myricom had both Myrinet and Ethernet running on the same port, Quadrics had same for QsNet and Ethernet. “HPC Ethernet” is not Ethernet – having a different packet format means changing the wire protocol. You can decide to name a proprietary network “HPC Ethernet”, and nothing wrong in supporting multiple protocols, but lets name the child correctly. The item that is unknown at this point, is what capabilities Cray does include in the real Ethernet option of Slingshot, and what capabilities exist in the proprietary network version of Slingshot, beyond of course the basic network elements. By the way, having dual protocols on the same network device can be an advantage, and can be a disadvantage. i.e. latency….
As for the congestion control etc. items, there are multiple implementation models and technologies created for Ethernet, and the hyperscale folks are using something much better than what is being described in the comment. It is good to see that Cray finally supports one of the basic network elements. Hard to understand why would it be the highlight of a network technology released in 2019, as the industry already defined good set of solutions for these issues, and now dealing with more relevant problems.
Couple more comments: “as Scott put it, making a step function improvement in congestion control over what is available in Aries” – well, there is no congestion control in Aries, so “over what is available in Aries” is very funny….
Second, the first line in the table “Standards Based / Interoperable” – Ethernet is standard based, Slingshot is not. The only relevant word is “Interoperable”, not “Standards Based”. Someone said marketing?
Hi,Scot
Please intrudoce what’s the difference of Cray’s “HPC Ethernet” with mellanox’s “IPOIB”, which can trasform Ethernet packages through IB network, thank you very much.