
Updated: There is some chatter – some might call it well-informed speculation – going on out there on the Intertubes that Japanese system maker NEC is shutting down its “Aurora” Vector Engine vector processor business. If this turns out to be true, this would mark the end of the vector supercomputer era that Seymour Cray started way back in 1964 with the Control Data Corp 6600.
We had reached out to NEC for comment and had not heard back as yet when this story ran, but we have added the comment to the bottom of this story.
The only reason we bring this up at all is that Satoshi Matsuoka, director of the RIKEN Lab in Japan and a professor at Tokyo Institute of Technology, made some comments on Twitter suggesting that NEC was sunsetting the successor to the venerable SX line of vector machines that dates back to 1983. Aside from driving the design and installation of several generations of TSUBAME supercomputers at TiTech, Matsuoka spearheaded the development and installation of the 537 petaflops “Fugaku” supercomputer based on Fujitsu’s A64FX vector-enhanced multicore Arm processor.
“Buried in GTC/GTP excitement, NEC announces ceasing R&D of their next gen accelerator aiming to be 10x improvement in power efficiency, citing that commercial accelerators will match their objectives,” Matsuoka said in a tweet. “This could be the final nail in the coffin for their SX vector processors history. At 6.8 TB/sec mem BW target, MI300 would have buried them already in 2023… Not just MI300 but also the improved version of H100 w/Grace. Similar thing happened when they pulled out of K computer R&D in 2009 as a consequence of the Lehman shock, but SX survived as GPUs & HBM tech were still nascent. 2023 the situation is that there are upcoming products this year that will match them whereas their plan I believe was for 2026/27.”
There is a lot to unpack there. Let’s get to it.
The current incarnation of NEC vector machines debuted as the Aurora Vector Engines, used in the Tsubasa line of machines, in October 2017. In a sense, what used to be a massive SX vector system had been compacted down to a single socket on a PCI-Express card, and multiple of these Vector Engines can be plugged into an X86 server host and networked into a cluster of vector math units (using InfiniBand of course) that can scale to tens of petaflops fairly easily. The largest such Aurora-based system we can find is the Earth Simulator 4 machine at the Japan Agency for Marine-Earth Science and Technology Center, which has 640 nodes with eight Aurora VE20B motors each, which have eight vector cores each for a total of 40,960 vector cores delivering a peak 13.45 petaflops and ranking number 56 on the November 2022 Top500 ranking of the world’s supercomputers. The ES4 system has 720 all-CPU nodes as well as eight GPU-accelerated nodes for a total 19.5 petaflops of peak performance.
JAMSTEC is home of the legendary original Earth Simulator system that was built using 640 nodes with eight vector engines each, with a total of 10 TB of main memory spanning 5,120 logical vector processors and delivering 40 teraflops of peak double precision performance for a cool $350 million in 2001 dollars. That would be close to $600 million today, which is the cost of the 1.69 exaflops “Frontier” supercomputer at Oak Ridge National Laboratory.
That $600 million in inflation-adjusted cost for the original Earth Simulator, which was the fastest supercomputer in the world from 2002 through 2004, is nothing compared to the $1.2 billion that the Japanese government shelled out for the “Project Keisuko” supercomputer effort to break through the 10 petaflops barrier by 2010 (that is $1.67 billion in 2023 dollars), ultimately accomplished by Fujitsu for RIKEN Lab in the K supercomputer. It is also dwarfed by the cost of the kicker Fugaku system installed in 2021 at RIKEN and also designed by Fujitsu, which cost $910 million (about $1.05 billion today).
To a certain extent, if NEC is going to stop development of the Aurora Vector Engine accelerators, this is the consequential result of its actions during the Great Recession as it pulled out of the Project Keisuko effort back in May 2009 along with Hitachi, leaving Fujitsu holding the bag.
Project Keisuko, also known as the Next Generation Supercomputer Project, is sponsored by the Japanese Ministry of Education, Culture, Sports, Science, and Technology, also known as MEXT, which also paid for the Fugaku system and which is also doing a feasibility study right now for the “Fugaku-Next” supercomputer expected to be installed around 2030.
When the sub-prime housing market bubble burst in 2008 and caused the Great Recession in 2009, NEC and Hitachi bailed on the Keisuko effort. Under the original plan for the K machine, Fujitsu was designing the scalar processor, NEC was designing the vector processor, and Hitachi was designing the torus interconnect we now know as Tofu.
The Keisuko project survived budget cuts, and Fujitsu added fatter vector math units to its Sparc64 clones of Sun Microsystems’ Sparc architecture CPUs and linked a massive number of single-socket machines using the very efficient Tofu interconnect to make a powerful machine that did very well on both synthetic benchmarks as well as real-world applications. The Fugaku machine shifted the CPU architecture to Arm cores, fattened up the vectors, and scaled up the system with a higher dimension Tofu D interconnect.
Had NEC stayed in the Keisuko project, then Fujitsu and NEC would have no doubt created a hybrid architecture using a mix of scalar and vector processors, with the vast majority of the compute coming from the vector engines made by NEC. They would have created an offload model similar to that espoused by Nvidia with its GPU accelerators, and NEC would quite possibly have made a considerable amount more money with its SX systems. And it would have been part of the Fugaku system and very likely part of the Fugaku-Next system. In short: NEC could not reap what it was not willing to sow, and Fujitsu has done a good job demonstrating how ease of programming and making a vector-heavy hybrid scalar/vector compute engine is more elegant and efficient (given the right interconnect, of course) than having hybrid CPU and GPU combinations within a node and using InfiniBand to link nodes together.
It is interesting to us that Fujitsu sold off its chip making foundry in 2009 just as this was all going down. Maybe MEXT should have encouraged the foundry business as well as supercomputing design?
Last October, just ahead of the Supercomputing 2022 conference, NEC launched the third generation of Vector Engines in five years, the VE30, but the details were a little thin. Here was the roadmap at the time:
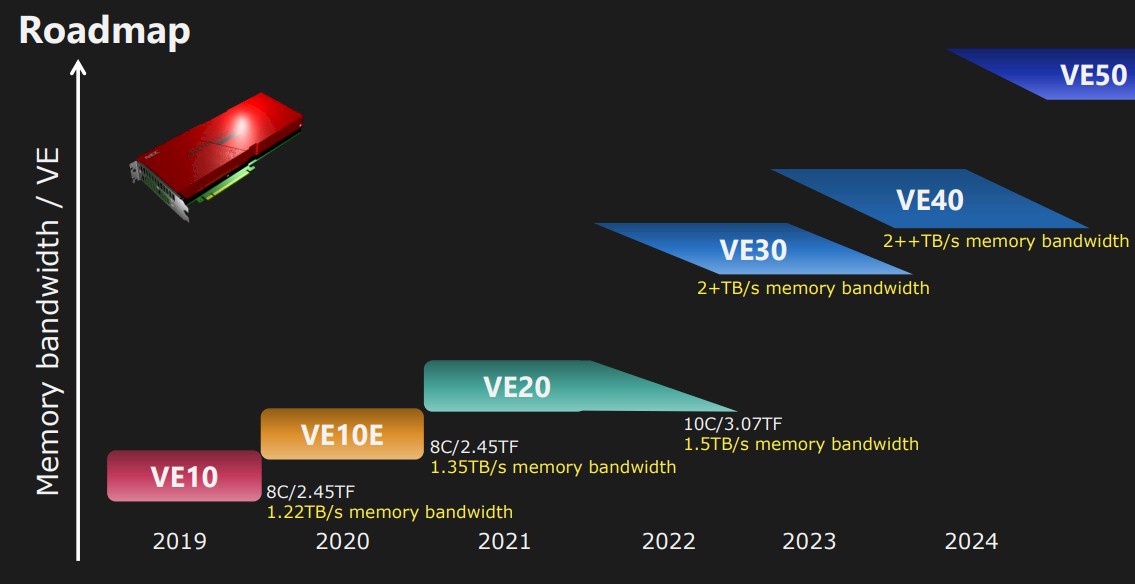
During its presentations at SC2022 in November last year, which talked about the Aurora VE30 devices as well as the next two generations, the roadmap looked like this:
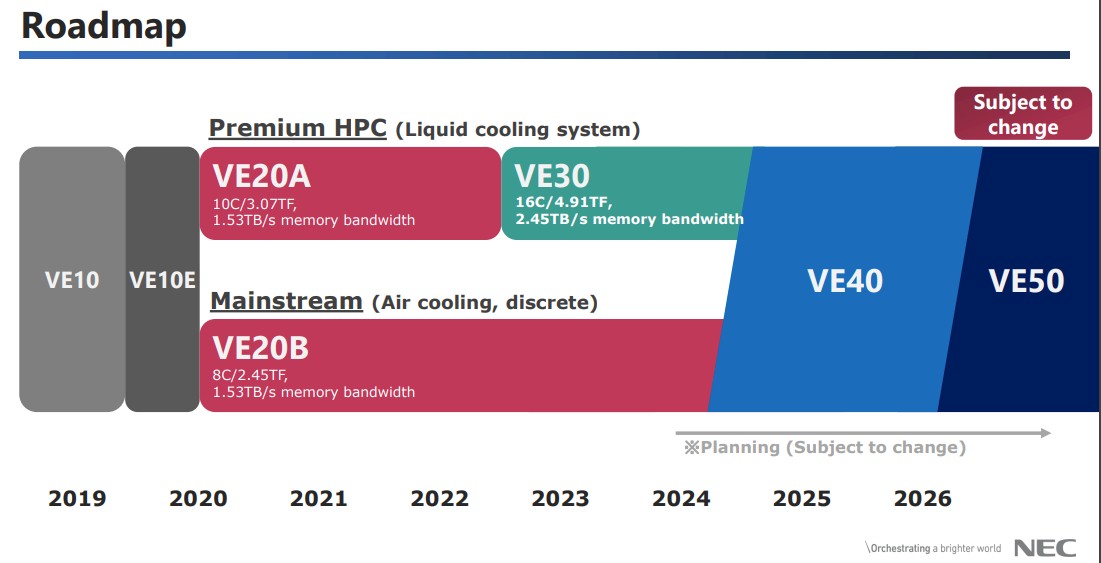 As you can see, the VE30 boosted the vector core count per package from 10 cores to 16 cores, a 60 percent increase, and pushed the HBM2e memory bandwidth up by 60 percent to 2.45 TB/sec. (We think HBM2e memory capacity might have doubled from 48 GB to 96 GB, but can’t find the specs anywhere on the Internet.) The performance of the VE30 was 69.2 percent higher than on the VE20 on the High Performance Linpack benchmark test, which suggests the VE30 was running at a slightly higher clock speed. We thing the VE30 was etched in Taiwan Semiconductor Manufacturing Corp’s 7 nanometer processes, compared to its 16 nanometer processes used for the VE20.
As you can see, the VE30 boosted the vector core count per package from 10 cores to 16 cores, a 60 percent increase, and pushed the HBM2e memory bandwidth up by 60 percent to 2.45 TB/sec. (We think HBM2e memory capacity might have doubled from 48 GB to 96 GB, but can’t find the specs anywhere on the Internet.) The performance of the VE30 was 69.2 percent higher than on the VE20 on the High Performance Linpack benchmark test, which suggests the VE30 was running at a slightly higher clock speed. We thing the VE30 was etched in Taiwan Semiconductor Manufacturing Corp’s 7 nanometer processes, compared to its 16 nanometer processes used for the VE20.
That SC2022 presentation focused a lot on simulating a quantum annealing quantum computer on the Vector Engine clusters and how it was working with D-Wave to build an interesting hybrid.
It is interesting to us that not once, but twice, on this simple roadmap in November 2022 we see the words “Subject to change” highlighted, and that the VE40 and VE50 were only in the planning stages and set for deliveries around 2024 and 2026, respectively. If the roadmap was pushed out further to 2026 and 2027, then other accelerators – and importantly hybrid accelerators mixing CPUs and GPUs from Nvidia and AMD – will be pushing the HBM boundaries and bringing both vector and matrix math to bear for both AI and HPC workloads.
Perhaps being a vector engine is no longer enough. We await the response from NEC about all of this.
Update: We did finally hear from NEC, whose public relations team sent us this message via email:
“I have consulted with our business teams, and they have indicated that although NEC is discontinuing efforts to develop low-power consumption accelerators with Japan’s New Energy and Industrial Technology Development Organization’s (NEDO) Green Innovation Fund, NEC is continuing its High Performance Computing business, including the NEC SX-Aurora TSUBASA.”
This is precisely the statement that Matsuoka said to expect when we talked to him via email before this story ran, and what he is talking about is apparently coming from discussions with others who are knowledgeable about a longer range plan — quite possibly a contingency plan — at NEC. It is possible that those doing the chattering have their stories mixed up, and we can’t blame that on getting lost in translation. Matsuoka was pretty clear to us that there were multiple sources and several things going on, without being specific about it.
Having said all of that, we come back to what we have pointed out above and what many of you have said in the comments. It gets harder and harder to afford the process shrinks on the Aurora vector processors given the rising costs and the relatively small market size they have. One recessional shock is all it might take to change the situation as described by NEC PR. It has happened before, after all.


The Most Complex Chip Ever Made?
Historically Intel put all its cumulative chip knowledge to work advancing Moore’s Law and applying those learnings to its future CPUs. Today, some of those advanced processors are destined for the forthcoming “Aurora” supercomputer at Argonne National Laboratory. However, demanding simulation and modeling workloads also benefit significantly from GPU acceleration. …

Top500 Supercomputers: Who Gets The Most Out Of Peak Performance?
The most exciting thing about the Top500 rankings of supercomputers that come out each June and November is not who is on the top of the list. That’s fun and interesting, of course, but the real thing about the Top500 is the architectural lessons it gives us when we see …

The World Has Changed – Why Haven’t Database Designs?
It seems like a question a child would ask: “Why are things the way they are?” It is tempting to answer, “because that’s the way things have always been.” But that would be a mistake. Every tool, system, and practice we encounter was designed at some point in time. They …
VE30 specs are not hidden: https://www.nec.com/en/global/solutions/hpc/sx/vector_engine.html
Clock is the same, the better than linear speedup might have come from bigger cache or architectural improvements.
They don’t compete against GPUs: if it’s been successfully ported to CUDA, the game is over. Memory bound hard-to-port-to-GPUs problems are their niche. Xeons with HBM may be their death knell.
They absolutely were when we wrote about the VE30 last year. Thanks for the link.
> They don’t compete against GPUs: if it’s been successfully ported to CUDA, the game is over.
Historically that was very much the case, but recently NVIDIA’s pricing has been scaling in line with their ML performance rather than HPC. A decade ago a colleague of mine procured a cluster of 36 K20’s for ~£100k, five years ago he got 16 V100’s for ~£100k, and now he is looking at 4 H100’s for about the same money.
NEC VE’s do very well in this category. The main issue is the attitude of NEC. Case in point they still charge for and license the ‘ncc’ compiler. No one else, not even Intel (!), is in that game anymore. You pay several thousands of dollars for a VE and then if you actually want to use it, need to fork out even more for a compiler license. (There is LLVM support, but the performance is not there.)
Irrespective of what improvements might have been planned, as far as I can tell they only managed to sell 5-10 thousand of these cards. No matter the architecture, designing a high performance chip for 3-5 nm process is going to cost hundreds of millions of dollars. Divide that by the units shipped and you’ve got tens of thousands of dollars in r&d costs per unit, before you even start in on software. There are very likely areas of HPC where NEC’s vector units perform better than a GPU or a CPU with HBM, but not many, and probably not in AI or any other hpc adjacent markets. Interesting, but not exactly cost effective.
I’m surprised by this turn of events as I would have expected vector-motors to “always” be ahead of GPUs in terms of their performance and efficiency at processing data vectors (and matrices, and tensors). GPUs were initially designed to process projected triangles for display, including pixel coordinates, colors, shades and textures, and only later re-engineered for more generic vectors, matrices and tensors, while the V-engines were designed for those from the get-go (unencumbered by triangular legacy). Market forces may have fostered broader adoption of GPUs, thanks to gamers with wealthy parents, or their own disposable income, and economies of scale (plus CUDA) that led to viral GPU adoption in HPC (and AI/ML), and to the enhanced designs that we see today — but from a purely logical and technical perspective, V-machines should have won out, from the onset (outside of gaming, VR, and other such display-focused apps). The situation reminds me of electric cars, such as “la fusée”, which can be seen at the “musée national de la Voiture de Compiègne”, that hit 100km/h (60mph) way back in 1899, but was abandoned in favor of internal combustion engine tech, only to find again (nowadays) that electric motors may not be such a bad idea after all … logic and reason eventually winning out over short term capex.
I wonder if somehow this is a bit of a trial balloon to see how much complaining there would be should such a thing come to pass. If people make enough of a fuss, then the funding will be found. I have seen this sort of thing before.
Hubert
A vector processor that is perfectly engineered to extract every bit of performance possible from a process node and memory subsystem might perform better than a similar gpu-derived architecture. However, NEC probably has 1/1000th the budget of nvidia in terms of tuning the design to the available resources.
Thanks … makes sense (unfortunately)!