
When it comes to chips, there is a big difference between a kicker and a fork.
The kicker is a successor that implements an architecture and design and that includes microarchitecture enhancements to boost core performance (core in the dual meanings of that word when it comes to CPUs) as well as taking advantage of chip manufacturing processes (and now packaging) to scale the performance further in a socket.
The fork is a divergence of some sort, literally a fork in the road that makes all the difference as Robert Frost might say. There can be compatibility – such as the differences between big and little cores in the Arm, Power, and now X86 markets. Intel and AMD are going to be implementing big-little core strategies in their server CPU lines this year, AMD in its “Bergamo” Epycs and Intel in its “Sierra Forest” Xeon SPs. Intel has had X86 compatible Atom and Xeon chips and now E and P cores for a decade and a half, so this is not precisely new to the world’s largest CPU maker.
And this kind of fork is what we think Japanese CPU and system maker Fujitsu will be doing with its future “Monaka” and “Fugaku-Next” processors, the former of which was revealed recently and the latter of which went onto the whiteboards with stinky markers – well, it was the beginning of a feasibility study by the Japanese Ministry of Education, Culture, Sports, Science, and Technology, with Education, Culture, Sports, Science being a variable X and thus making up the abbreviation MEXT – back in August 2022.
Fujitsu has been a tight partner of the RIKEN Lab, the country’s pre-eminent HPC research center, since the design of the $1.2 billion “Keisuko” K supercomputer, which began in 2006 to break the 10 petaflops barrier in 64-bit precision floating point processing and which was delivered in 2011. Design on the follow-on the $910 million, 513.9 petaflops “Fugaku” supercomputer, which saw Fujitsu switch from its Sparc64 architecture to a custom, vector-turbocharged Arm architecture, started in 2012. The Fugaku system was delivered in June 2020, was fully operational in 2021, and work on the Fugaku-Next system started a year later, right on schedule.
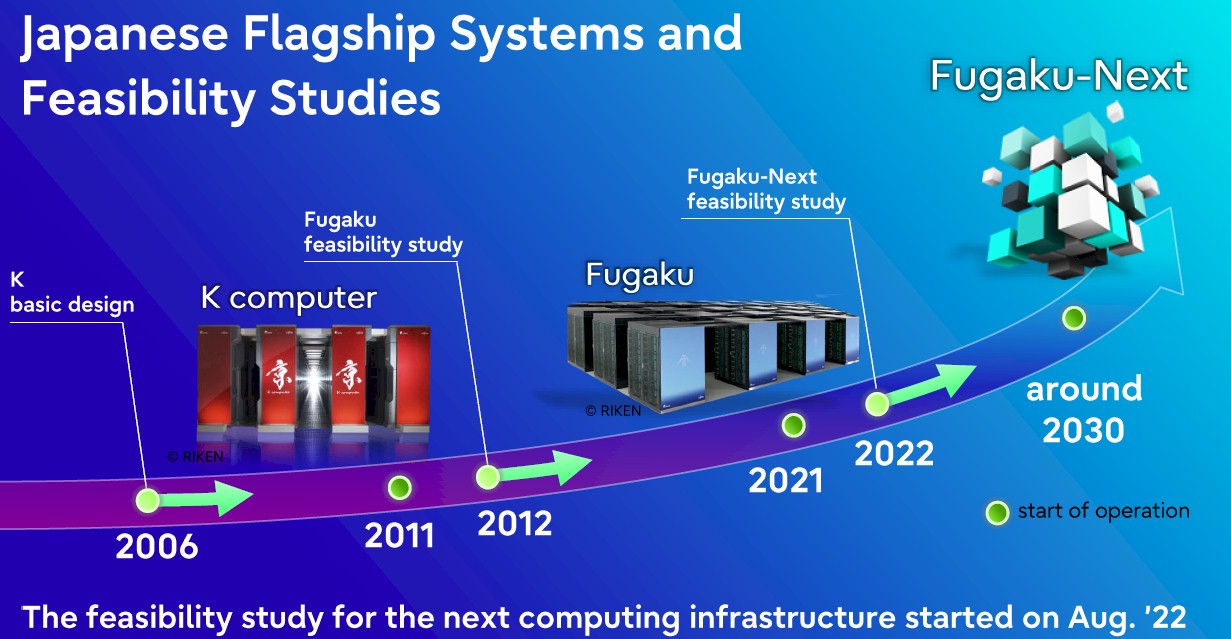
According to the roadmap put out by Fujitsu and RIKEN Lab at SC22 last November, the plan is for the Fugaku-Next machine to be operational “around 2030,” and that timing is important (we will get into that in a moment).
Here are the research ideas being tackled and the technology embodied in Fugaku-Next and who is doing the tackling:
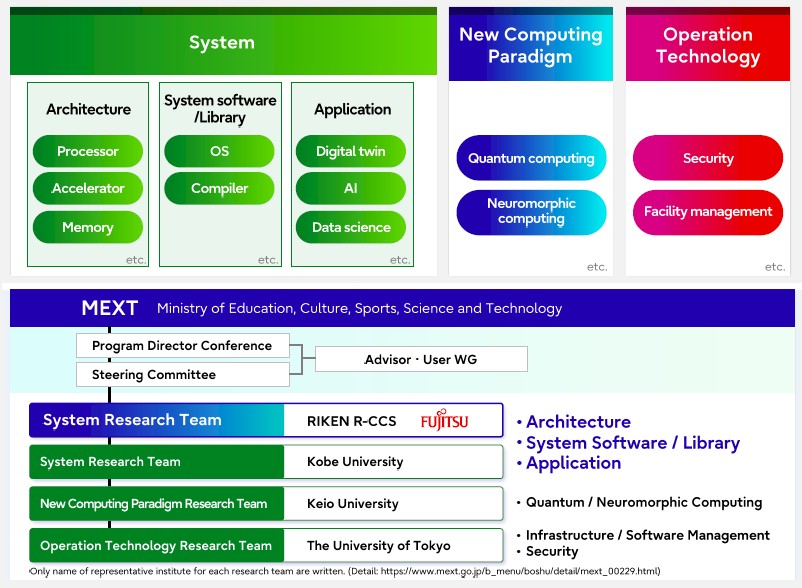
All of the ideas you would expect in a machine being installed in six or seven years are there – a mix of traditional HPC and AI and the addition of quantum and neuromorphic computing. Supercomputers in the future will be powerful, no doubt, but it might be better called “flow computing” more than “super computing” because there will be a mix of different kinds of compute and applications comprised of workflows of different smaller applications working in concert, either in a serial manner or in iterative loops.
Significantly, Fujitsu and RIKEN are emphasizing “compatibility with the existing ecosystem” and “heterogeneous systems connected by high bandwidth networks.” Fujitsu says further that the architecture of the Fugaku-Next system will use emerging high density packaging, have energy efficient and high performance accelerators, low latency and high bandwidth memory.
If history is any guide, and with Japanese supercomputers it absolutely is, then a machine is installed in the year before it goes operational, which means Fugaku-Next will be installed in “around 2029” or so.
Keep that all in mind as we look at the “Monaka” CPU that Fujitsu is working on under the auspices of the Japanese government’s New Energy and Industrial Technology Development Organization (NEDO). At the end of February, Fujitsu, NEC, AIO Core, Kioxia, and Kyocera were all tapped to work on more energy efficient datacenter processing and interconnects. Specifically, the NEDO effort wants to have energy efficient server CPUs and photonics-boosts SmartNICs.
Within this effort, it looks like Fujitsu is making a derivative of the A64FX Arm processor at the heart of the Fugaku system, but people are conflating this with meaning that Monaka is the follow-on processor that will be used in the Fugaku-Next system.
This is precisely what was said: “Fujitsu will further refine this technology and develop a low-power consumption CPU that can be used in next-generation green datacenters.”
Here are the tasks assigned to the NEDO partners:
- Fujitsu: Development of low-power consumption CPUs and photonics smart NIC
- NEC: Development of low-power consumption accelerators and disaggregation technologies
- AIO Core: Development of photoelectric fusion devices
- Kioxia: Development of Wideband SSD
- Fujitsu Optical Components: Development of photonics smart NIC
- Kyocera: Development of photonics smart NIC
The Monaka CPU is due in 2027 and aims to provid higher performance at lower energy consumption:

How this will happen is unclear, but the implication is that it will be an Arm-based server processor, but one optimized for hyperscalers and cloud builders and not for HPC and AI centers. That should mean more cores and less vector processing relative to A64FX (or rather, the kicker to A64FX in Fugaku-Next system) and very likely the addition of low-precision matrix math units for AI inference. Something conceptually like Intel’s “Sapphire Rapids” Xeon SPs and future AMD Epyc processors with Xilinx DSP AI engines in terms of capabilities, but with an Arm core and a focus on energy efficiency, much higher performance per watt.
In fact, as Fujitsu looks ahead to 2027, when Monaka will go into production systems, it says it will be able to deliver 1.7X the application performance and 2X the performance per watt of “Another – 2027” CPU, whatever that might be.
The confusing bit, which has led some people to believe that Monaka is the processor that will be the kicker to A64FX and used in the Fugaku-Next systen, is this sentence: “Not only boosting traditional HPC workloads, but also providing high performance for AI & Data Analytical workloads.”
But here is the thing, which we point out often:HPC is about getting performance at any cost, and hyperscalers and cloud builders need to get the best reasonable performance at the lowest cost and lowest power.
These are very different design points, and while you can build HPC in the cloud, you can’t build a cloud optimized for running Web applications and expect it to do well on HPC simulation and modeling or even AI training workloads. And vice versa. An HPC cluster would not be optimized for low cost and low power and would be a bad choice for Web applications. You can sell real HPC systems under a cloud model, of course, by putting InfiniBand and fat nodes with lots of GPUs in 20 percent of the nodes in a cloud, but it is never going to be as cheap as the plain vanilla cloud infrastructure, which has that different design point.
With Fugaku-Next being a heterogeneous, “flow computer” style of supercomputer, it is very reasonable to think that a kicker to the Monaka Arm CPU aimed at cloud infrastructure could end up in the Fugaku-Next system. But that is not the same thing as saying there will not be a successor to A64FX, which researchers have already shown can have its performance boosted by 10X by 2028 with huge amounts of stacked L3 cache and process shrinks on the Arm cores. That is with no architectural improvements on the A64FX cores, and you know there will be tweaks here.
We think it is far more likely that a successor to Monaka, which we would expect in 2029 given a two year processor cadence, could be included in Fugaku-Next, but that there is very little chance it will be the sole CPU in the system – unless the economy tanks and MEXT and NEDO have to share money.
The Great Recession messed up the original “Keisuko” project, which had Fujitsu doing a scalar CPU, NEC doing a vector CPU, and Hitachi doing the torus interconnect we now know as Tofu. NEC and Fujitsu backed out because the project was too expensive and they did not think the technology could be commercialized enough to cover the costs. Fujitsu took over the project and delivered brilliantly, but we suspect that making money from Sparc64fx and A64FX has been difficult.
But, with government backing, as Fujitsu has thanks to its relationship with RIKEN, and Japan’s desire to be independent when it comes to its fastest supercomputer, none of that matters. What was true in 2009 about the value of supply chain independence (which many countries ignored for the sake of ease and lower cost supercomputers) is even more true in 2029.
Fujitsu is not being specific, and Satoshi Matsuoka, director of RIKEN Lab and a professor at Tokyo Institute of Technology, commented on the reports that Monaka was being used in Fugaku-Next machine in his Twitter feed thus: “Nothing has been decided yet whether Monaka will power #FugakuNEXT; it is certainly one of the technical elements under consideration.” But he also added this: “Since #HPC(w/AI, BD) is no longer a niche market, the point is not to create a singleton ***scale machine, but S&T platforms that will span across SCs, clouds etc. For that purpose, SW generality & market penetratability esp. to hyperscalars are must. We will partner w/vendors sharing the same vision.”
We think there will be two Arm CPUs used in Fugaku-Next: One keyed to AI inference and generic CPU workloads and one tuned to do really hard HPC simulation and AI training. Call them A64FX2 and Monaka2 if you want. The only way there will be one chip is if the budget compels it, just as happened with the K machine.
But, this is admittedly just speculation, and we will have to wait and see.

Hope Springs Eternal For Arm Servers
IT organizations are funny creatures, indeed. On the one paw, they are eternally optimistic about the prospects for new technologies, and on the other paw, they are extremely resistant to change because of the economic and technical risks that change requires. For more than a decade now, the people who …

Taking A Superhybrid Approach To HPC/AI Convergence
AMD has been on such a run with its future server CPUs and server GPUs in the supercomputer market, taking down big deals for big machines coming later this year and out into 2023, that we might forget sometimes that there are many more deals to be done and that …

Fugaku Remakes Exascale Computing In Its Own Image
When originally conceived, Japan’s Post-K supercomputer was supposed to be the country’s first exascale system. Developed by Fujitsu and the RIKEN Center for Computational Science, the system, now known as Fugaku, is designed to be two orders of magnitude faster than its predecessor, the 11.3-petaflops (peak) K computer. But a …
A forked approach to progress from A64FX seems reasonable, with the hope of continued cross-fertilization, and neither branch ending up overly “less traveled”. As Paul mentioned some time ago, A64FX is quite elegant in enabling a single ISA to be used for both scalar and vector ops in the CPU (no need to program an external group of GPUs), for example (ARM assembly with SVE extensions):
ld1d z1.d, p0/z, [x0, x4, lsl #3] // load/gather vect from mem into z1
fmla z2.d, p0/m, z1.d, z0.d // vect mult z0 & z1, accum into z2
st1d z2.d, p0, [x1, x4, lsl #3] // store/scatter vect z2 back to mem
This natively integrated ability for vector-scatter/gather and vector-ops gives A64FX (or Fugaku really) its advantage in HPCG’s sparse matrix memory access kung-fu (fujitsu’s jui-jitsu?) relative to split CPU-GPU architectures. AVX-512 may also do this, of course, for the relevant alternative arch. For dense matrix karate of HPL (simple block-like mem access) the CPU+GPU wins out owing to the much greater oomph provided by its very numerous vector/matrix computational engines. So, the fork leading to Fugaku-Next may consider pairing A64FX with NEC vector processors (of previous Next Platform articles) to improve on that, especially if they do mixed precision well (Fugaku is 3rd on HPL-MxP, behind the much smaller LUMI). Meanwhile, the future stacked caches mentioned here should help it maintain its top spot on HPCG (most relevant to FD/FEM/CFD), against the split competition.
Ironically for ARM’s “power-sipping” reputation, the Fugaku’s 60MJ/EF, while acceptable I guess, is beyond Frontier’s 20MJ/EF (and Grace+Hopper’s possibly 15MJ/EF). It looks like the Monaka fork could bring this down to a much more attractive 18MJ/EF (60/1.7/2.0), but, long-term, additional precise slicing of the power budget, as per Zatoichi’s most awesome blind swordsmanship, will likely be required (proverbial knife, for either fork). Speaking of slicing, there is a whiff of administrative seppuku in the French government this evening (PM), as protesters metaphorically celebrate Dr. Antoine Louis’ 300th anniversary, in a “contre nous de la tyrannie” response, to forced passage of the pension reform. Irrespective, I would love to see deeper collaboration between Fujitsu-RIKEN and the musketeers of EuroHPC on this promising architecture, that already proved its worth — focused on sufficiently distant and uplifting goals, such as 10EF and 100EF.
This (above) also echoes Eric’s comment on “Intel Pushes Out Hybrid CPU-GPU […]” (credit where credit is due).