

There is a constant push and pull between budget and architecture in supercomputing, and the passing of time has not made anyone’s arms tired as yet on both sides of the bargaining table. And the thing that is refreshing about all of this is that mixed in with all of the accounting and intellect that drives these massive systems – the thing that makes the whole process really hum – is hope. A desire to test out a bunch of new ideas in a system that may or may not ever be broadly commercialized and yet is a platform upon which good and important science can be performed.
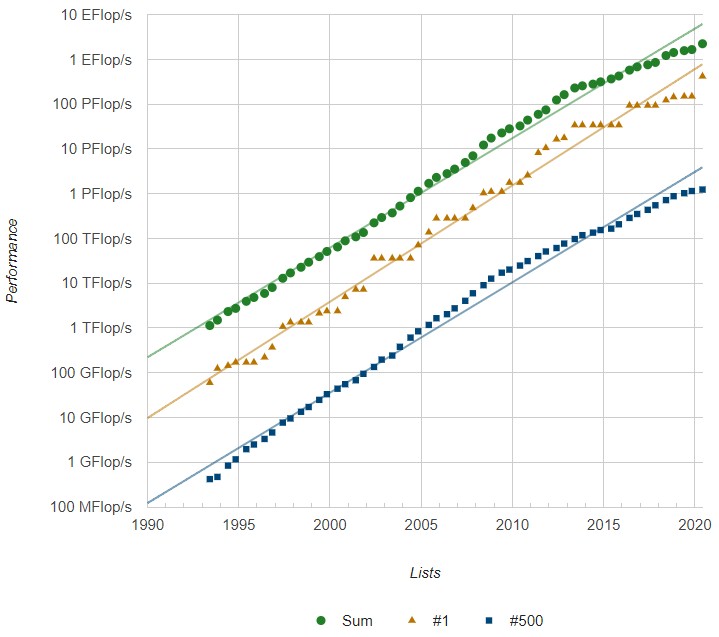
So, when machines like ASCI Red in 1996, or Earth Simulator in 1997, or ASCI Q in 2003, or Red Storm in 2005, or BlueGene in 2006, or Roadrunner in 2009, or Tianhe-1 in 2010, or K in 2011 – and this is by no means meant to be an exhaustive list of machines with innovative architectures, just the ones that come immediately to mind – make their debut, it is a big deal. And so it is this day for the Fugaku system at the RIKEN lab in Japan, which has become the most powerful computer in the world, according to the Top500 rankings announced today at the opening of the ISC 2020 Digital supercomputing conference. And it is not a coincidence at all that Fugaku is expected to do well on the Green500 ranking, ranking among the most energy efficient machines in the world – and one that is being deployed at a massive scale, not in a rack or two.
None of this is a surprise to us, of course. Fugaku is so by design. And the fact that RIKEN and its development partner, Fujitsu, chose the Arm architecture as the heart of the 48-core A64FX computation engines is groundbreaking and interesting and perhaps even represents a real tipping point for Arm in the datacenter. But only because of the way that the Arm architecture was extended with 512-bit Scalable Vector Engine math units, which support mixed integer and floating point precision that can drive HPC simulation and modeling in addition to machine learning training and inference all on the same platform. This is what makes Fugaku important, especially when it is coupled with the improved Tofu D interconnect that is a descendant of the Tofu1 and Tofu2 interconnects that made the K supercomputer and then the Fujitsu PrimeHPC systems that followed it into the commercial market able to run real HPC applications and benchmarks like High Performance Linpack (HPL) and High Performance Conjugate Gradients (HPCG) so well.
We suspect that the combination of the A64FX processor and the Tofu D interconnect will be potent. But today, this is about celebrating this new machine and its top spots on the Top500 and the Green500. It is the first of accolades for Fugaku, a rite of passage even for those who are cynical about HPL and ranking machines based on it.
The Fugaku system that was used to test HPL for the Top500 ranking had just under 7.3 million cores running at 2.2 GHz, which is just a stunning amount of concurrency to manage and is a little less than 3X the concurrency is you add up the number of cores and streaming multiprocessors (SMs) across the Power9 CPUs and Nvidia GV100 GPUs in the Summit system at Oak Ridge National Laboratories, which formerly held the top spot on the list. (But as Bronson Messer, the new director of science at Oak Ridge, explained to us last week, that is not the level of concurrency granularity that actual users on Summit deploy – it is a bit more complicated than that.) In any event, keeping 1.61 x 1016 cycles per second on the cores busy as much as possible is a mean feat and deserves our respect.
With those cores fired up, Fugaku had a peak theoretical performance of 513.85 petaflops at double precision floating point, which is the gauge that – for now – is most important for HPC simulation and modeling comparisons. Thanks to the efficiency of the compute and network design and the use of 32 GB of HBM2 main memory to feed the A64FX beast, Fugaku was able to deliver 415.53 petaflops of performance on the Linpack benchmark, which is an 80.9 percent computational efficiency. The machine will no doubt have its performance further optimized, as happened with the K supercomputer in 2010 and 2011. The K system achieved 10.51 petaflops on Linpack, for a 93.2 percent computational efficiency. This is a very high bar for any system to achieve, but you can bet that Fujitsu and RIKEN want to meet and beat that level.
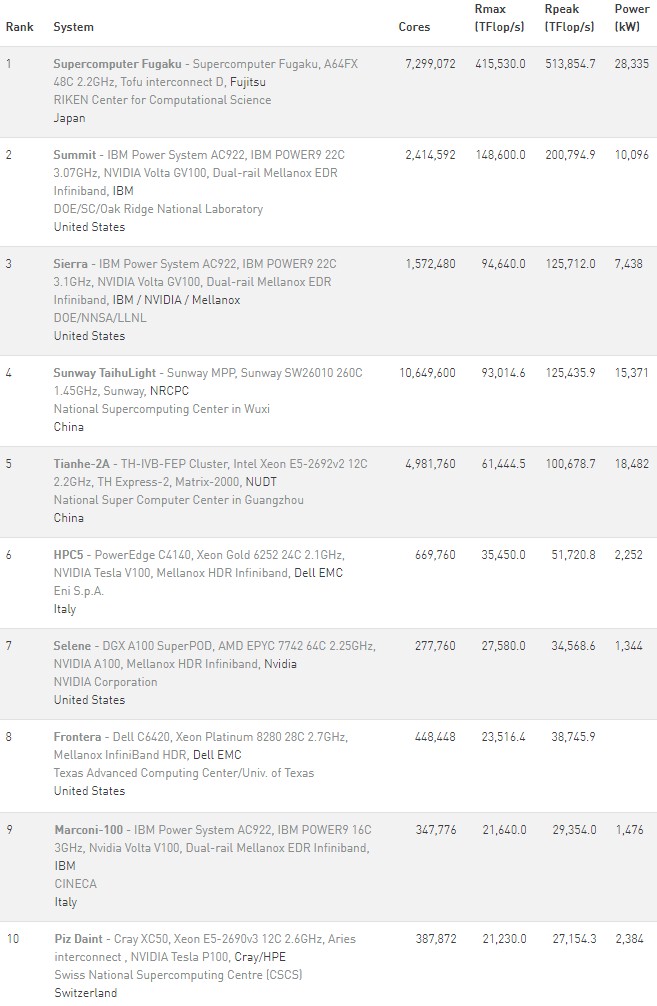
In terms of energy efficiency, the Fugaku system tested was rated at 28.33 megawatts, and when you do the math, that works out to 14.67 gigaflops per watt. Summit, by comparison, burns 10.1 megawatts to deliver 148.6 petaflops on Linpack, for a computational efficiency of 74 percent (not surprising given the hybrid CPU-GPU architecture) and a respectable 14.72 gigaflops per watt. Here’s the rub, though. Fugaku delivers 2.8X the Linpack oomph at 64-bits, but at a $910 million cost compared to around $205 million for Summit, it costs 4.4X to get there. This is why all-CPU systems have fallen out of favor, but they persist in some cases because keeping those hungry GPUs fed and doing work is problematic, even with an elegantly designed system like Summit.
We don’t have the full Green500 list as we go to press, but we do know that Preferred Networks has built a system called the MN-3 that has a matrix math accelerator called the MN-Core chip at its heart that has 1.62 petaflops in performance (ranking 395 on the Top500 list) and delivering 21.1 gigaflops per watt.
The number two machine on the Green500 list is the newly nicknamed and augmented Selene supercomputer, which we wrote about last month, that was built by Nvidia using its own DGX A100 servers, equipped with the “Ampere” GA100 GPUs as well as a pair of AMD “Rome” Epyc 7742 processors, and 200 Gb/sec HDR InfiniBand interconnect from its Mellanox division. Selene is used for AI software development, chip verification and testing, and other workloads, but is not used for chip design as far as we know. So it is mostly an AI machine. It has 280 DGX A100 systems with a total of 2,240 GA100 GPUs, interlinked with NVLink inside the nodes and InfiniBand across the nodes, with 494 Quantum switches (we think there is expansion room in that network, obviously, since the switch count exceeds the node count) with a total of 56 TB/sec of network fabric bandwidth (again, we don’t think this is all being used). This system has 7 PB of all flash storage as well. It came in at 27.6 petaflops running Linpack, for a computational efficiency of 79.8 percent but a rating of 20.5 gigaflops per watt, giving it the number two ranking. So the computational efficiency of the hybrid CPU-GPU systems has not changed much from Summit to Selene, but the energy efficiency of the GPUs moving from Volta to Ampere certainly has.
The NA-1 system built by PEZY Computing using its line of special purpose math accelerators was third on the Green 500 list with a machine with 1.27 million cores pushing 1.3 petaflops sustained on the Linpack test, for a computational efficiency of 72.7 percent and a respectable 16.3 gigaflops per watt. This machine ranked 469 on the list.
We spoke to Erich Strohmaier, senior scientist and group lead of the Performance and Algorithms Research group at Lawrence Berkeley National Laboratory and one of the co-creators of the Top500 list, in an interview that will air later today on Next Platform TV, and he tells us that with only 51 new machines on the list, the is the lowest level of churn that he has seen since the rankings were started in 1993. It is not clear if this lull is being caused by COVID-19, but there probably are some budgetary pressures down in the bottom half of the list. But we can’t really blame that wholly on the corona virus pandemic, either. (We also have an interview with Wu Feng of Virginia Tech, who puts together the Green500 list, coming later today on Next Platform TV. So stay tuned for that.)
The aggregate performance on the Top500 list stands at 2.23 exaflops, up 35.2 percent from the November 2019 list and almost exclusively due to the addition of the Fugaku system. You now need 1.24 petaflops to make the list. In terms of aggregate performance – which we are beginning to think is a better metric than system count to gauge the propensity to invest in supercomputing by nations – the United States had 644 petaflops compared to China with 565 petaflops and now Japan with 530 petaflops.
There are far too many machines on the Top 500 list submitted by hyperscalers and cloud builders, which dominate the middle of the list and that have little to do with either HPC or AI, to use country or vendor rankings to say much that is meaningful with regard to HPC or AI. We have complained much about this, and we not going to repeat ourselves. The list needs to be the Top500 supercomputers, not the Top500 clusters that ran Linpack this time around and submitted results.
Given all of this – real HPC and AI systems stacked up with cloud and hyperscale systems that simply ran the test for vendor and country bragging right – it is not a surprise that systems using X86 processors dominate the list, with 481 of the 500 machines based on X86.

Of these, 469 use Intel Xeon or Xeon Phi processors (or a mix), whole 11 use AMD Epyc processors and the final one using an Epyc clone from China’s Hygon. There are four machines based on the Arm architecture on the list, with three of them being based on Fujitsu’s AFX64 and one of them based on Marvell’s ThunderX2 processor.

A total of 144 machines have accelerators in some fashion supplying their floating point oomph, and the majority of these – 135 systems – are using Nvidia GPU accelerators.


Top500 Supercomputers: Who Gets The Most Out Of Peak Performance?
The most exciting thing about the Top500 rankings of supercomputers that come out each June and November is not who is on the top of the list. That’s fun and interesting, of course, but the real thing about the Top500 is the architectural lessons it gives us when we see …
A Tale Of Two Nvidia Eos Supercomputers
Note: This story augments and corrects information that originally appeared in Half Eos’d: Even Nvidia Can’t Get Enough H100s For Its Supercomputers, which was published on February 15. So, as it turns out, there are two supercomputers named Eos, and even the people in the press relations department at Nvidia, …

The Mystery Of Tianhe-3, The World’s Fastest Supercomputer, Solved?
We don’t like a mystery and we particularly don’t like it when what is very likely the most powerful supercomputer in the world – at this time anyway – is veiled in secrecy. But that is what the Tianhe-3 supercomputer built for the National Supercomputer Center in Guangzhou, China has …
The more relevant HPCG benchmark results were just posted today and Fugaku blew the doors off of everything else as expected. Fugaku and its PrimeHPC FX1000 derivatives maintained the ~2.5-3% of peak that the PrimeHPC FX100 had in HPCG.
While not quite as efficient as K, which dominated the HPCG benchmark until Summit and Sierra were released, 2.6% in an unoptimized early stage is extremely good.
That’s going to be the key to Fugaku’s domination of HPCG and outperforming systems that beat it in HPL FLOPS.
Summit and Sierra are 1.5% of peak, and Taihulight is 0.4% for comparison to other large systems. Nothing can really beat a system like Fugaku because everything is a spared no expense, bespoke design for HPC.
It will be interesting to see if Fugaku can stay at the top of the HPCG and Graph500 lists when systems with 10x the HPL FLOPS come out the way that K did.