

Sponsored When it comes to compute engines and network interconnects for supercomputers, there are lots of different choices available, but ultimately the nature of the applications — and how they evolve over time — will drive the technology choices that organizations make. And such is the case with the new Earth Simulator 4 supercomputer at the Japan Agency for Marine-Earth Science and Technology Center, or JAMSTEC.
JAMSTEC has a long and storied history of innovation in supercomputers, and is notable for the original Earth Simulator massively parallel vector supercomputer that was installed in 2001 and operational in 2002 and which was the most powerful supercomputer in the world for many years. JAMSTEC has invested in four generations of Earth Simulator systems in the past two decades, and the machines have evolved along with the vector compute engines from Japanese system maker NEC and, with the latest generation which became operational in March 2021, includes hybrid compute capabilities that mix NEC “SX-Aurora TSUBASA” vector co-processors and Nvidia “Ampere” A100 GPU accelerators inside of host server nodes that employ AMD Epyc X86 server processors, all lashed together by high-speed Nvidia HDR 200 Gb/sec InfiniBand networking.
Moore’s Law advances and architectural changes have allowed JAMSTEC to get a lot more compute and networking for a lot less money and in a lot less space over the two ensuing decades, which is a testament to the innovation in the supercomputing industry.
That first Earth Simulator was based on NEC’s SX-6 architecture, and it had 640 compute elements with a total of eight sockets and 16GB of main memory per element. The sockets presented themselves as single nodes to the SUPER-UX Unix operating system that spanned the 5,120 logical nodes in the machine, which had a stunning — remember, this was two decades ago — 10TB of memory capacity. The Earth Simulator 1, or ES1, system had 700 TB of storage and 1.6 PB of tape archive, and it delivered a world-record 40 teraflops of peak double-precision floating-point processing across its aggregated vector engines.
This system, which cost $350 million — a price tag that was also a world record at the time — is similarly a testament to the Japanese government’s enthusiasm to invest heavily in advanced technologies — something that continues to this day. The ES1 machine was important because it was the first supercomputer that could simulate the climate of the entire Earth, including the atmosphere and the oceans, at a resolution of ten kilometers.
In 2009, JAMSTEC upgraded to the ES2 supercomputer, which was based on the NEC SX-9/E architecture, and which had 160 compute elements, one-fourth the number of ES1 but supplying a peak performance of 131 teraflops at double precision. The ES2 compute elements had eight sockets, in common with the ES1, based on a single-core vector processor with 102.4 gigaflops of oomph and 128GB. ES2 had 1,280 processors and 20 TB of memory, which was a lot of both in a system of the time. Importantly, ES2 delivered a factor of 3.3X more performance in one quarter the number of compute elements, lowering costs and thermals while increasing compute density — all important for a research facility that is focused on the effects of climate change.
With the ES3 system launched in 2015, JAMSTEC wanted to run much finer-grained simulations and added compute, memory, and interconnect performance to scale up the speed of simulations while at the same time increasing the resolution of those simulations. ES3 had a total of 5,120 SX-ACE four-core vector processors, each equipped with 64 GB of main memory that delivered 256 GB/sec of bandwidth into the processing complex and 256 gigaflops of performance across those cores. Across the 20,480 cores, the ES3 system could deliver 1.3 petaflops of peak double-precision performance and 1.3 PB/sec of bandwidth across a total of 320 TB of main memory. The number of compute nodes in the ES3 system was back up to the same 5,120 as in ES1, but the number of cores went up by a factor of 4X, the peak performance rose by a factor of 32.5X, the memory capacity rose by 32X, and the bandwidth rose in sync with it.
Back in 2017, NEC shifted the architecture of its vector engines, adding HBM2 memory stacks to them — the same memory used with other GPU accelerators and now a few CPUs aimed at supercomputing — while at the same time putting them in adapter cards that plug into PCI-Express slots in host machines. We discussed this “Vector Engine” accelerator card as well as the “SX-Aurora TSUBASA” hybrid CPU-VPU system that NEC has created based on this architecture at length when it was unveiled in October 2017.
NEC has refined this SX-Aurora TSUBASA system over time, but the important thing is that rather than have a proprietary interconnect linking standalone vector engines to each other, the new architecture has host servers linked by fast and industry-standard InfiniBand interconnects that are the preferred method of lashing supercomputers together in the upper echelons of the HPC industry.
With the ES4 system, JAMSTEC is going hybrid on a couple of different vectors (pun intended). Here are the complete feeds and speeds of the ES4 machine:
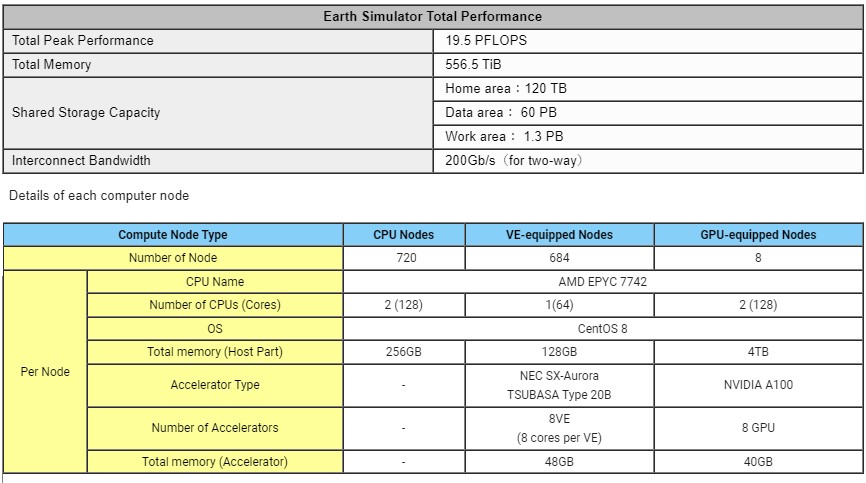
Here is a more simplified view of the ES4’s architecture:
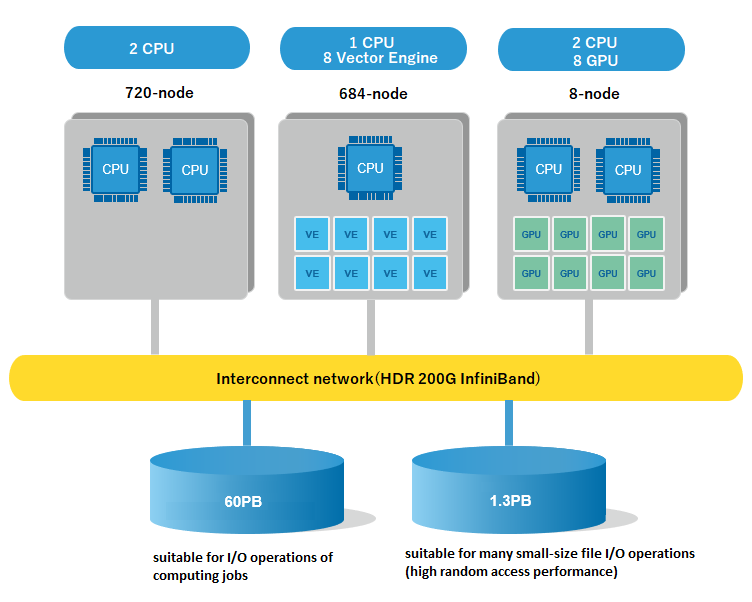
ES4, as you can see, is really a cluster of clusters and is designed to support an application workflow that will make use of partitions on the machine that run CPU-only code, vector-accelerated code, and GPU-accelerated code. This is an important distinction from the prior Earth Simulator machines and reflects the substantial advancement in codes related to climate modeling on CPU architectures that have embedded vector engines. as well as the parallel computing power of GPUs. It also illustrates JAMSTEC’s continuing need to support its portfolio of vector applications. Given this, it is vital to have a single network with low latency and high bandwidth that can tightly couple these three different types of compute elements together. Nvidia InfiniBand not only fits all these requirements, but through its advanced In-Network Computing acceleration engines and hardware offloads, decreases the amount of data traversing the network to dramatically reduce time of operation.
The vector nodes in the ES4 system are based on the SX-Aurora TSUBASA B401-8 server nodes, which have a variant of the Vector engines that have had their performance goosed by 25 percent compared to the stock parts. These B401-8 nodes have eight PCI-Express cards that have vector engines on them, each with 2.45 teraflops of performance, for a total of 19.6 teraflops of aggregate performance.
Each Vector Engine card has 48 GB of HBM2 stacked memory, for a total of 384 GB of capacity in the node. The host B401-8 machine has a single AMD Epyc 7742 processor, with 64 cores and 128 GB of its own DDR4 memory. Across the 684 nodes in this vector partition, there are a total of 5,472 vector engines with a combined 43,776 vector cores, all fed by 256.5 TB of HBM2 memory and 8.3 PB/sec of aggregate memory bandwidth, delivering 13.4 petaflops of 64-bit peak performance. The Epyc 7742 processors in this partition add another 1.57 petaflops of 64-bit calculating power across 85.5 TB of memory and 140 TB/sec of memory performance. Most of the performance in this partition obviously comes from the SX-Aurora TSUBASA Vector Engines, which delivers 10.3X more performance and 6.3X more bandwidth than the ES3 system it replaces.
But the ES4 machine is more than just its vector engine partitions. There is a CPU-only partition that has 720 nodes with a pair of Epyc 7742 processors, each rated at 2.3 teraflops with its integrated vector processors for 4.6 teraflops per node. These systems are Apollo 2000 Gen10 Plus server nodes from Hewlett Packard Enterprise, with 256 GB of memory per node. If you do the math, this CPU-only partition has 3.3 petaflops of peak performance across 92,160 cores, with a total of 180 TB of main memory and 294 TB/sec of memory bandwidth. The performance of the CPU-only partition is itself 2.5X more than the ES3 machine, but its memory bandwidth is a little more than a fifth as much. The gap between performance and memory bandwidth is substantially wider than with the vector partition, and that will make a big difference in what parts of the application workflow end up on this CPU partition.
Finally, the ES4 machine has a modest number of GPU accelerated nodes, which nonetheless provide a reasonably large amount of 64-bit performance, HBM2 memory capacity, and HBM2 memory bandwidth. This GPU partition has eight HPE Apollo 6500 Gen10 Plus nodes, each with eight Ampere A100 GPU accelerators with 40 GB of HBM2 memory. These nodes also have a pair of AMD 7742 processors, which have negligible 64-bit performance compared to the rest of the ES4 hybrid cluster, given that there are only sixteen of them. But the 64 A100 GPUs have substantial oomph of their own, delivering 1.24 petaflops of performance using Tensor Core units at 64 bits across 2.5 TB of aggregate HBM2 memory and 99 TB/sec of aggregate memory. That is less than a third of the memory bandwidth as the whole ES3 system itself, but it is nearly the same compute performance and nearly twice the memory capacity — all crammed into a mere eight nodes.
All told, across all the compute elements in the ES4 hybrid cluster, there is a total of 20.2 petaflops of vector performance at 64-bit precision, 556.5TB of main memory (the combination of DDR4 and HBM2 memory), and 8.7PB/sec of memory bandwidth. This is a big system by any measure, but clearly Moore’s Law has made it possible for it to take up a lot less space and cost a lot less money than the original ES1 system from two decades ago.
These systems do not act in isolation, of course. The whole point of the ES4 machine is that the nodes within each cluster partition are tightly coupled to each other for shared work but then also to the other two partitions and to the two different types of storage that are shared among these compute partitions.
To that end, the CPU-only partitions in the ES4 machine have a single HDR 200Gb/sec InfiniBand port within each node that connects into the network, while the vector and GPU nodes have a pair of such ports coming out of the nodes.
For storage, there are two different clustered storage arrays, both of which come from DataDirect Networks and both of which run the Lustre parallel file system. There is an all-flash partition aimed at accelerating small file I/O that has 1.3 PB of capacity based on the DDN ES200NVXE, which employs NVM-Express flash to substantially raise the storage bandwidth and lower its latency. A more general purpose Lustre array base on disk drives has a 60 PB of capacity and is based on the DDN ES7990XE platform. All of the storage and all of the compute partitions are on the same 200 Gb/sec InfiniBand network. This is not just radically simpler than the networking that is often done with supercomputers and their storage, but it balances out performance across the compute-storage infrastructure.
The purpose of this hybrid system with its integrating network is not just to be fast and flexible, but to do real things. Like weaving traditional HPC simulation and modeling with AI techniques to find the epicenters of earthquakes that are caused by volcanic activity — something that Japan, which is a massive volcanic island arc, wants to be able to do more quickly and more accurately. Any extreme phenomena, such as volcanic activity and the earthquakes and tsunamis that might follow them or precede them, are very difficult to build a model of from observational data. But researchers at JAMSTEC have learned to create simulated seismic wave propagation patterns and then run these through 3D convolutional neural networks to train them to recognize different earthquake patterns and to find their epicenters. This 3DCNN is used to learn from videos of earthquakes to regress the motion level of many regions to seismic source parameters, and these can be plotted out to find the epicenter.
Given the hybrid nature of the workload, the performance of the GPU-accelerated portion of the ES4 system is therefore key to the ability of the JAMSTEC to do the epicenter analysis that it needs to do for public safety. Here is how the new GPU-only partition of the ES4 machine compares to the Data Analyzer (DA) system that was installed in 2018, that was based on Nvidia’s “Pascal” P100 accelerators, and that was used for machine learning applications in the past.
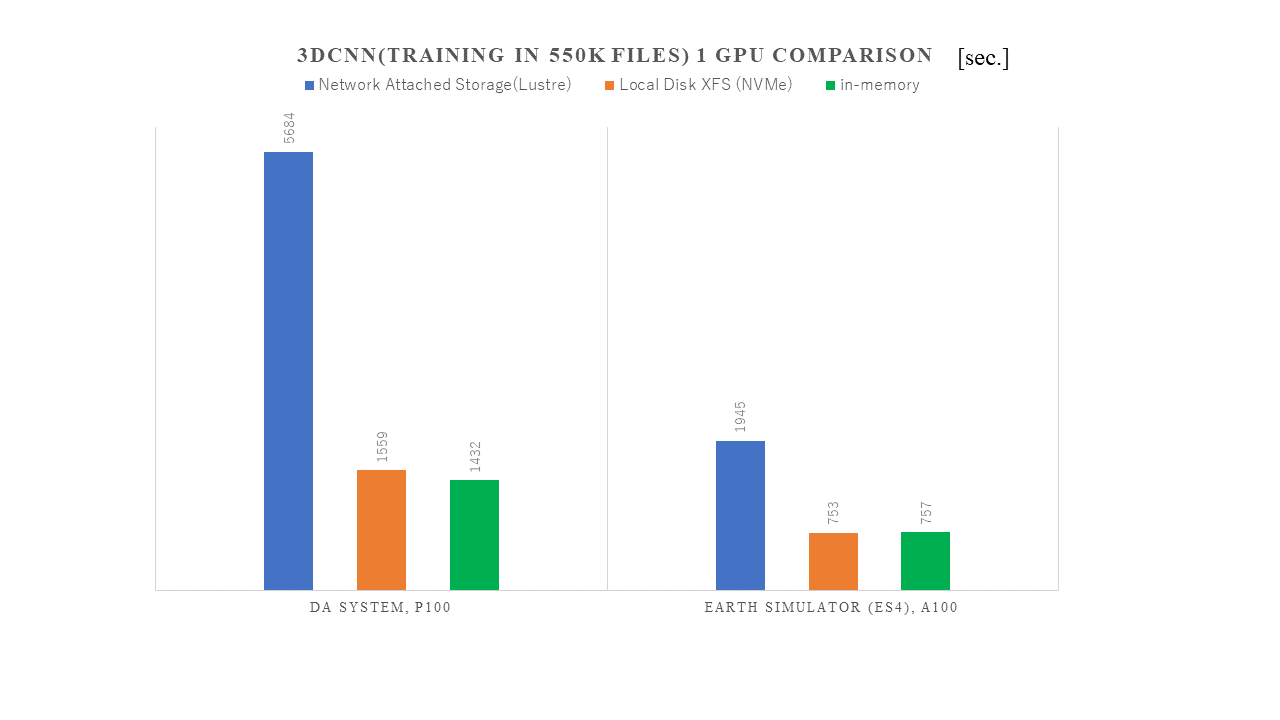
The DA system had 20 P100 accelerators, while the GPU partition on the ES4 machine has 64 A100 accelerators, which collectively have a lot more memory capacity, a lot more memory bandwidth, and a lot more floating-point and integer performance for driving 3D CNN performance.
The first thing to note is that this is the performance of running only one GPU across one epoch, which means each sample in the machine learning dataset has been used to update the parameters of the machine learning model. On the DA system, it took 5,684 seconds to run one epoch through the model when pulling data from the Lustre parallel file system, but the entire dataset had 100 epochs to do the machine learning, which works out to 157 hours to do each machine learning training run. So cutting the time here is important, which happened by moving to the GPU partition of the ES4 system, where the time per epoch was cut by a factor of 2.9X. And even using local NVM-Express flash and the XFS file system or running the data in-memory, the performance can be boosted by 2X on the new ES4 GPU partition.
The ES4 system has so much more performance for GPU, vector, and GPU compute that JAMSTEC hopes to be able to dramatically improve the speed and accuracy at which it can calculate the epicenters of earthquakes. And this is but one project that JAMSTEC is working on with this hybrid system.
This article is sponsored by Nvidia.


With AI, You Need To See The Bigger Hardware And Software Picture
Sponsored Feature: It’s a decade and a half since researchers dazzled the tech world by demonstrating that GPUs could be used to dramatically accelerate key AI operations. That realization continues to grip the imagination of enterprises. IDC has reported that when it comes to infrastructure, GPU accelerated compute and HPC …
Aurora In A Socket: What Intel’s “Falcon Shores” XPU Might Do
We are still chewing through some of the announcements that came out of Intel Investor Day and the ISSCC 2022 chip conference, and one of the things we want to circle back on is the “Falcon Shores” hybrid CPU-GPU that Intel is working on for future servers. Given all of …
Hell Freezes Over: Cisco And Nvidia Cross-Pollenate AI Networking
UPDATED Networking giant Cisco Systems and AI platform provider Nvidia have hammered out a deal to mix and match each other’s technologies to create a broader set of AI networking options for their respective and – importantly, prospective – customers. Nvidia has been a competitor of Cisco’s in the datacenter …
Given they only ordered 8 GPU nodes, I think those are the AI/ML nodes to satisfy the handful of researchers in the organization who need lots of low precision ops.
Interesting that the vector nodes have dramatically more flops, and hugely better scalar performance, but essentially the same network bandwidth per node and memory bandwidth per processor of the original Earth simulator from 20 years ago. One wonders if there are a lot of codes whose performance is largely unchanged, though at a much lower price tag.
Good insight. Thanks.