

It is the nature of capability class supercomputers to try to push the envelope on as many different architectural fronts as possible. The very purpose of these machines to blaze a trail into the future, and that involves all kinds of risk taking and technological problems that, in the end, have to be solved. And, knock on wood, generally have been as long as we have been watching the upper echelon of computing for over three decades.
And so, HPC gurus the world over are waiting with bated breath for the next edition of the Top500 supercomputer rankings due in June during the ISC2022 supercomputing conference, when hopefully we will see the “Frontier” system at Oak Ridge National Laboratory, which will be the first exascale-class machine up and running in the United States, put through the paces on the Linpack and HPCG supercomputing benchmark tests.
No promises have been made on delivering those benchmarks at that time, but the Frontier system was installed last fall, and Oak Ridge said in a statement today, when talking about benchmarks run on the “Crusher” testbed system that is based on the same exact hardware and software used in Frontier, that the “promising performance on Crusher points toward success on the full Frontier system, which will be operational in the second half of 2022.” The statement from Oak Ridge goes on to say that Frontier will become fully operational on January 1, 2023 for the INCITE capacity allocation awards.
There Is Never A Final Frontier
Announced back in May 2019, the Frontier machine is part of the CORAL-2 procurement from the US Department of Energy and was expected to have in excess of 1.5 exaflops of peak theoretical double-precision floating point performance and to be installed sometime in 2021. Most of us expected Frontier to star on the November 2021 Top500 rankings, and to our chagrin this did not happen. Which is not at all surprising given that each Frontier node has a custom “Trento” Epyc 7003 processor from AMD lashed to four custom “Aldebaran” MI Instinct 250X GPUs from AMD, an updated Infinity Fabric 3.0 links from AMD that sport coherent memory sharing across the CPUs and GPUs, and a new “Rosetta” Slingshot interconnect and Slingshot network interface cards from Hewlett Packard Enterprise. Oh, and Frontier also has a new ROCm 5.0 software stack for GPU offload programming. That is a lot of new stuff, and new always involves risk, particularly when computing and networking at scale.
And thus, last October, to whet our curiosity appetites, Oak Ridge put out some pictures and details about the Frontier system, which we compared and contrasted to the also-late-running and much more beleaguered “Aurora” system going into Argonne National Laboratory, based on the same HPE “Shasta” Cray EX platform with the Slingshot interconnect, but sporting “Sapphire Rapids” Xeon SP processors and “Ponte Vecchio” Xe HPC GPU accelerators. The Aurora machine was supposed to hit around 1 exaflops peak in 2018 using a totally different “Knights Hill” Xeon Phi many core CPU and a totally different 200 Gb/sec OmniPath quasi-InfiniBand interconnect, but the entire architecture of the Aurora system was changed and last October its peak performance was pushed up to in excess of 2 exaflops.
From the statement just put out by Oak Ridge, which is revealing some comparative benchmarks on the Crusher testbed system it has set up to help programmers port code to Frontier and to help HPE and Oak Ridge do performance tuning on the new architecture, it looks like Frontier will have a little bit more raw performance than was expected three years ago. Which is always a good thing. The existing “Summit” supercomputer weighed in at 200.8 peak petaflops, and Oak Ridge says that it now expects for the Frontier machine to pack around 2 exaflops of FP64 oomph, and instead of using more than 100 cabinets to deliver that performance as was originally expected, it takes only 74 compute cabinets, or 9,408 total nodes, to do the job. That is 4.8X more peak performance per node and a little more than 2X the number of nodes to deliver 10X the peak performance of Summit.

Maybe they should have called the system “Scott,” after the engineer on the starship Enterprise, who admonished engineering students to underpromise and overdeliver. . . . .
The Crusher system has one and a half cabinets with a total of 192 nodes, which means there are 128 nodes per cabinet in both the Frontier and Crusher systems. The Frontier and Crusher nodes look like this in schematics:
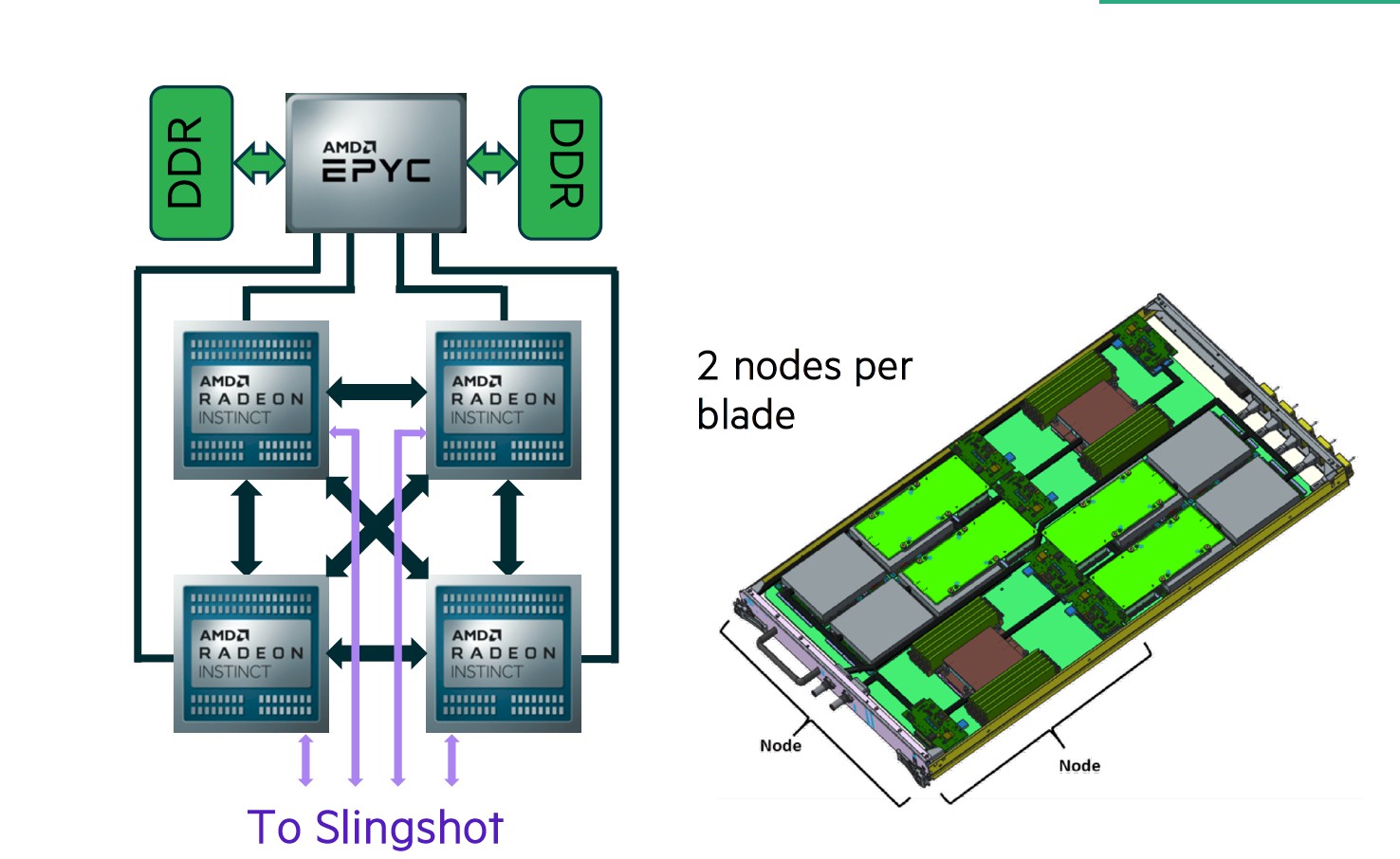
In the schematic above, the CPUs and GPUs were interleaved and the pair of nodes rotated 180 degrees from each other, but as you see in the chart higher up, AMD and Cray decided to put all the CPUs on one side and all of the GPUs on the other side of the tray. The branding has also changed since HPE put its schematic out. The GPUs no longer have Radeon in their name, just Instinct.
The Trento processors have 512 GB of DDR4 main memory and each MI250X GPU has 128 GB of HBM2e memory, for a total of 1 TB of main memory across the accelerators in the node. Add it all up, and there are 4.6 PM of main memory on the CPUs and 4.6 PB of main memory on the CPUs, and 47,040 total compute engines and 37,632 total “Cassini” Slingshot 11 network interface cards, one per MI250X GPU accelerator.

The statement put out by Oak Ridge said “Frontier provides an 8-fold increase in computational power from the center’s current 200-petaflop IBM AC922 Summit supercomputer,” and by this we interpret this to mean an eight-fold increase based on the High Performance Linpack benchmark test and not the raw performance inherent in the Frontier machine, which is clearly 10X based on the data we have. If that is the case, then that implies the Linpack performance is expected to be around 1.2 exaflops on Frontier, which would be a computational efficiency of around 60 percent.
This is consistent – and frankly, better than – some rumors we heard last fall that had the initial Linpack performance tests for Frontier coming in at below the magic – and necessary for political reasons – 1 exaflops level. (We have calls into Oak Ridge for clarification about the eight-fold increase they are talking about and we do not expect much comment on Linpack performance rumors.)
Even if our interpretation of these statements turns out to be true, we think there is plenty of time to tune up Frontier, and that the performance level on Linpack and HPCG will continue to rise, both as the test results are being put together for publication and as more tuning is done in the hardware and software even after they are first reported. There is no reason to believe that in the long term that Frontier cannot reach the computational efficiency of the Summit machine, which has 200.8 petaflops of raw performance but which delivered 148.6 petaflops of Linpack number-crunching. That is a 74 percent computational efficiency., and at that same level, Frontier would obviously do about 1.48 exaflops on Linpack.
What really matters, of course, is the performance Frontier shows on real-world workloads, and Oak Ridge offered us up a taste of four different workloads:
- Cholla for astrophysics hydrodynamics simulations – Compared to the baseline tests done for this application on Summit back in 2019, this code is showing a 15X speedup, with about 3X coming from the hardware and 5X coming from the software. We really want to understand what happened here, because you always want to get as much or more improvement from software as you get from new hardware. This has certainly happened in the AI revolution, and it is good to see it happening in the HPC re-evolution.
- LSMS for materials modeling: This code, which can simulate up to 100,000 atoms at a time, has been ported to Crusher; performance results are not yet in.
- CANDLE transformer machine learning model for cancer research: This code was ported to Crusher and is seeing an 80 percent performance increase.
- NuCCOR simulation for nuclear physics: This is an Oak Ridge code, and it is seeing an eight-fold increase moving from Summit to Crusher.
We presumed that these tests are comparing the performance at a node level, which is how we think about systems, but Bronson Messer, director of science at Oak Ridge, who we talked to at length about Fronter in July 2020, told us by email that the comparisons were for slices of Summit and Crusher/Frontier with 64 GPU motors. And to be really precise here, it was for 64 Nvidia GV100 GPUs and for 32 dual-chip Aldebaran graphic compute dies, or GCDs.
It makes sense to talk about comparisons at the GPU level because that is how MPI ranks treat GPUs for a lot of applications. And obviously generally speaking, if you stack up the Nvidia “Volta” V100 GPU accelerators against the AMD MI250X GPU accelerators, there is a big leap.
Let’s do the math. The V100 was rated at 7.8 teraflops on its vector engines and did not support FP64 math on its Tensor Core matrix engines; the MI250X is rated at 47.9 teraflops on its vector engines and 95.7 teraflops on its matrix engines. (Those are stock MI250X GPU accelerators). If you do the math on the number of accelerators in the full Summit and Frontier systems, you get 215.7 petaflops for Summit (which implies that several hundred of the nodes were not driving the tests or we need more significant digits in the raw performance for the GPUs) and we get 1.80 exaflops peak for Frontier. To reach 2 exaflops peak on Frontier implies that the custom MI250X is overclocking at about 11 percent compared to the stock parts. Which is possible given that Frontier is a water-cooled version of the Shasta system. So on FP64 workloads, the range of hardware performance from the V100 to half of an MI250X is 3X to 6X – 7.8 teraflops for the V100 versus just under 24 teraflops to 47.9 teraflops for the Aldebaran GCD.
Now, let’s have some more Frontier pictures.
Here is the inside of the Frontier node tray with one of the 1 by 4 nodes visible:

And here is the liquid cooling for out of the nodes, with blue intakes and red outtakes for the liquid:

And finally here is a part of the network using the Slingshot switches:

We look forward to having the Frontier architectural deep dive when Oak Ridge is ready.


HPC Pioneers Pave The Way For A Flood Of Arm Supercomputers
Over the past few years, the Arm architecture has made steady gains, particularly among the hyperscalers and cloud builders. But in the HPC community, Arm remains under-represented. But perhaps not for long. The “Fugaku” system at RIKEN Lab in Japan is without a doubt the largest and best known Arm …
Spectrum-4 Ethernet Leaps To 800G With Nvidia Circuits
When Nvidia announced a deal to buy Mellanox Technologies for $6.9 billion in March 2019, everyone spent a lot of time thinking about the synergies between the two companies and how networking was going to become an increasingly important part of the distributed systems that run HPC and AI workloads. …
Opening Up The Future “Venado” Grace-Hopper Supercomputer At Los Alamos
There are many interpretations of the word venado, which means deer or stag in Spanish, and this week it gets another one: A supercomputer based on future Nvidia CPU and GPU compute engines, and quite possibly if Los Alamos National Laboratory can convince Hewlett Packard Enterprise to support InfiniBand interconnects …
Be the first to comment