

Paid Feature Great hardware is the foundation of any compute platform. But hardware, in and of itself, is never sufficient to create a platform. And in fact, it takes two other important things for any platform to be realized.
After the hardware, a platform requires a complete stack of software that can be easily and, we argue, relatively inexpensively adopted for application development on that hardware foundation.
This software stack has to be both inclusive and complete, encompassing algorithms and libraries suitable for the target markets, and a software development kit that supports familiar programming languages and programming models. Even if the software layer in this platform doesn’t start out complete – none of them ever do – they have to get to a reasonable level of completeness in a matter of years.
In terms of speed of development and adoption, it helps for this software layer to be open source, but that is not a requirement for success. And when it comes to deploying the platform in production environments, the software stack must have enterprise-grade technical support and a reasonable pricing model. The latter enables companies to put what the developers have created on their laptops and across their proof of concept systems into production at scale.
The third thing that is required to make a compute platform is an ecosystem of developers who create applications that run on the combined hardware and software. Just like a tree falling in the woods makes no noise because there is no person to hear it, great hardware and great software together are not a credible platform until a critical mass of people adopt those wares.
By this definition, the AMD ROCm open software stack is what turns a server or cluster of servers that employ its AMD EPYC CPUs (or those of others) and some of its Radeon and AMD Instinct accelerators into a true platform. We think it is a platform that now can compete head-to-head with Nvidia’s hardware plus its CUDA stack and Intel’s hardware plus its oneAPI stack. The added twist, ROCm can also deploy GPU code for Nvidia accelerators and any other accelerators that support C++.
The software stack is always the hardest part of the platform to develop, and ROCm is no exception in this regard. AMD had been working on heterogeneous CPU-GPU computing for many years, including its Heterogeneous System Architecture, when Nvidia suddenly took the HPC market by storm with its CUDA software stack in 2008 and then rode the shockwave of the AI explosion in 2012, expanding CUDA to cover machine learning training and inference workloads in addition to HPC simulation and modeling.
ROCm was first unveiled as “Project Boltzmann” back at the SC15 supercomputing conference in November 2015 as a means of providing an open source alternative to Nvidia’s closed source CUDA stack. Project Boltzmann was able to create C++ code that could be offloaded to AMD GPUs but also to Nvidia GPUs through the Heterogeneous Interface for Portability, or HIP, API, which is a CUDA-like API that allows for runtimes to target a variety of CPUs as well as Nvidia and AMD GPUs.
The GPU runtimes are included in the ROCm stack, which is open source and available through AMD and on GitHub, and the CPU runtimes are available as open source on GitHub, too. The ROCm stack also supports OpenMP for C and C++ programming on multithreaded CPUs and GPUs, and similarly, the GPU runtime for OpenMP is included in ROCm and the CPU compiler and runtime is available on GitHub.
The ROCm stack has been maturing at an accelerating pace, right alongside the ever-improving AMD Instinct GPU compute hardware coming out of AMD, starting out with common math libraries used in HPC and AI plus the OpenCL effort for running C and C++ across heterogeneous compute engines that originally came out of Apple and which became a standard in 2008.

Creating a platform is always a journey, and it is one that AMD has been on since it first put its weight behind the OpenCL approach to creating heterogeneous applications and then started Project Boltzmann in 2015 to create a broader platform that could compete against Nvidia’s CUDA.
AMD focused on the AI opportunity with ROCm first, and the ROCm 2.0 stack from 2018 was aimed predominantly at machine learning applications. But make no mistake about it. AMD has a long history in traditional high performance computing and was only able to take down exascale-class systems because of its commitment to enhance ROCm to become a full and complete stack for both HPC and AI workloads, something that arguably happened in 2020 when ROCm 4.0 was delivered.
Significantly, with ROCm 4.5 release in November 2021, concurrent with the preview of the AMD Instinct MI200 series accelerators that are being deployed in the 1.5 exaflops “Frontier” supercomputer at Oak Ridge National Laboratory, the first US system to break through the exaflops barrier at 64-bit floating point precision, has unified memory support between CPUs and GPUs.
The cache coherency between CPUs and GPUs has also evolved in the ROCm software stack over time, too, as illustrated in the chart below, all with the goal of making the programming of GPU compute engines more transparent and driving higher performance through better hardware (AMD Infinity Fabric links between CPUs and GPUs are key here) and better memory management techniques.

With ROCm 5.0 generally available, AMD is working its way back to the developer and helping ensure that the software stack will run on the new AMD Instinct MI200 series accelerators (and make use of 64-bit floating point in the GPU’s matrix engines), but also on workstations using Radeon PRO W6800 GPUs.
“With ROCm, we have done a lot of work over the years to provide a production ready software stack that can go live in deployments, but that is not the end of the story,” Tushar Oza, director of software product management for datacenter GPUs at AMD, tells The Next Platform. “Developers can create and test their code on a workstation and then take it to a large system and run it in a performant manner. And we are also about providing choice for developers – not just in the hardware, but with the programming environments through our support of OpenMP target offload and the HIP APIs.”
The compatibility with the Nvidia CUDA stack will be the key to the rapid adoption of AMD GPUs and the ROCm software stack by both the HPC and AI communities. It all starts with equivalency across the math and communication libraries, like this:
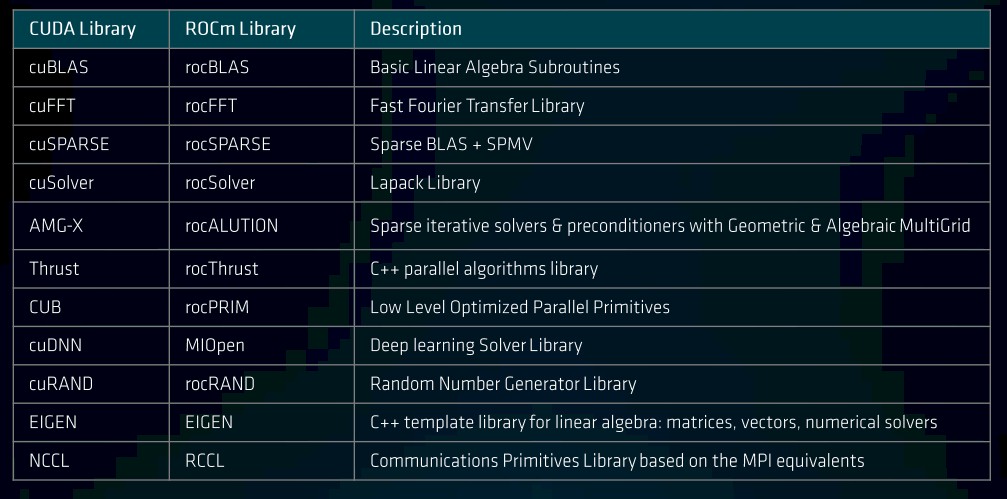
But when it comes to getting a lot of applications ported to AMD GPUs and the ROCm environment, HIP is absolutely the most important tool in the AMD toolbox. As we said above, this is the key to creating a widely adopted platform because it will make it relatively easy to port C++ codes that have been running in accelerated mode using Nvidia GPUs to a variant of C++ that can be deployed on Nvidia or AMD GPUs or X86 CPUs without any further code changes. And the evidence suggests that such porting is relatively easy and does not significantly affect performance:
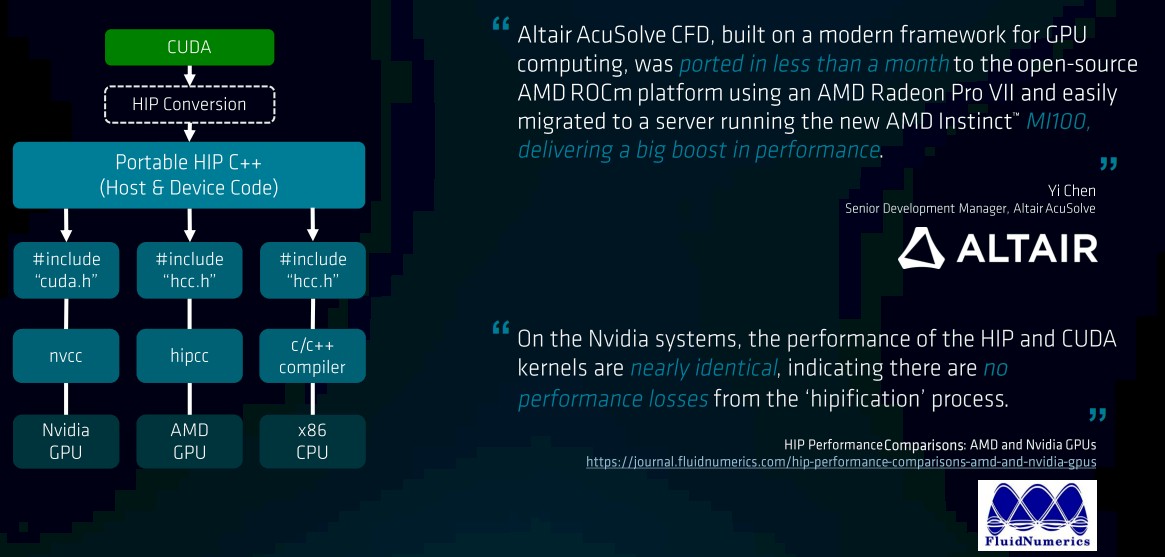
The portability works both ways with HIP, which is one of the things that makes it so appealing. Once code has been “HIPified” to move it from Nvidia GPUs to AMD GPUs, with only a 1 percent or 2 percent performance overhead – which is negligible considering the value of portability – it supports the compilation path for both hardware platforms with a single code base, easily enabling testing, performance comparison and migration. This is another way that openness cuts both ways for AMD – and keeps both vendors honest and competing.
The most important thing for competition, however, is that AMD has reached critical mass with ROCm 5.0 and the AMD Instinct MI200 GPU accelerators, garnering support and adoption from developers, ISVs and the open-source community. As the commercially supported applications with ROCm 5.0 become available this year, the AMD ecosystem will expand from their exascale system wins to a broad range of customers, partners, and systems across HPC & AI markets.
Sponsored by AMD

Cerebras Shows Off Scale Up AI Performance For Big Pharma And Big Oil
Historically, the largest organizations in the world – the Global 2000 plus the biggest national government and academic research institutions – have always had the most complex data processing needs. And by virtue of the size of their IT budgets and the sophistication and scale of their workloads, they get …
AMD Builds Out Its AI Software And Services Stack With Silo AI Buy
You can build a software ecosystem if you have time. But sometimes, you want to speed things up, and then you have to pay to build that ecosystem out. And that is precisely what AMD has been doing for the past year, and what we expect the company to do …
Nvidia Lays The Foundation For Wider AI Adoption
For a decade and a half, Nvidia has been pushed its way into the datacenter, making its presence felt with its GPU accelerators that are designed to improve the performance and power efficiency of servers in HPC and enterprise compute environments and also expanding the opportunities for running highly parallel …