

Just because Intel is no longer interested in being a prime contractor on the largest supercomputing deals in the United States and Europe — China and Japan are drawing their own roadmaps and building their own architectures — does not mean that Intel does not have aspirations in HPC and AI supercomputing. It most certainly does.
This was made clear to The Next Platform in a question and answer session following the keynote at open day of the Intel Innovation virtual conference, when Intel chief executive officer Pat Gelsinger answered some questions about the “Aurora” supercomputer being installed at Argonne National Laboratory and then tacked on some thoughts about Intel’s zettascale goals as a final thought. These turn out to be more important than what Gelsinger said about Aurora having its processing capacity almost doubled.
So, let’s just cut to the chase scene on Gelsinger pointing to the upper decks of zettascale and then circle back to some further insight into the new and improved Aurora system. Here is what Gelsinger said after answering our questions — well, sort of answering them — about the Aurora expansion and the $300 million writeoff that Intel Federal is taking in the fourth quarter (which we have presumed, since Intel mentioned in last quarter, was related to writing off some of the $500 million in revenue that was coming in from the US Department of Energy for the Aurora machine).
“But to me, the other thing that’s really exciting in the space is our Zetta Initiative, where we have said we are going to be the first to zettascale by a wide margin,” Gelsinger told The Next Platform. “And we are laying out as part of the Zetta Initiative what we have to do in the processor, in the fabric, in the interconnect, and in the memory architecture — what we have to do for the accelerators, and the software architecture to do it. So, zettascale in 2027 is a huge internal initiative that is going to bring many of our technologies together. 1,000X in five years? That’s pretty phenomenal.”
When you ask a question, you don’t get follow-up, and our microphone was cut to move onto the next question before we could ask for some qualification. So we will say what we will here. Zettascale means zettaflops — more precisely, it means 64-bit precision zettaflops and no doing any funny reduced precision counting, or retooling of the applications into lower precision and saying it behaves like a machine with 1,000 exaflops at 64-bits.
As far as we can tell, the A0 stepping of the “Ponte Vecchio” Xe HPC GPU accelerator, which Intel talked about back in August in some detail, has 47 tiles with 100 billion transistors and delivers 45 teraflops at single precision; the rumor is that it is running at 1.37 GHz. Intel has not released 64-bit precision figures for the Ponte Vecchio GPU complex, but its presentation says that the Xe core, which has eight vector engines and eight matrix math engines, can do 256 operations per clock for either FP64 or FP32 data. And while we didn’t fully process this at the time, it implies Intel can deliver 45 teraflops of double-precision floating point performance across the Ponte Vecchio complex, not half as much (or 22.5 teraflops) as you might expect if there were a single FP32/FP64 math unit. It does look like the FP32 unit is double pumped to give its 512 operations per clock rate, but we are inferring that.
We know that the Aurora node has two HBM-boosted “Sapphire Rapids” Xeon SP processors and six Xe HPC GPU accelerators, also crammed with lots of HBM as it turns out. The original Aurora machine based on Intel “Knights Hill” many-core processors was to have more than 50,000 single-socket nodes with lots of near and far memory to deliver 180 petaflops for a $200 million price tag. The updated “Aurora A21” system, which was proposed to Argonne in early 2019, cost $500 million, was based on a combination of Intel CPU and GPU accelerators, and was to deliver more than 1 exaflops of sustained double precision floating point performance. This is slated to take more than 9,000 nodes, which means more than 18,000 Sapphire Rapids CPUs and more than 54,000 Ponte Vecchio GPU accelerators. That’s roughly the same number of heavy compute engines as in the original Aurora machine, but assuming a 70 percent computational efficiency on the GPUs, which is common on GPU-accelerated LINPACK benchmark runs, and that the CPUs don’t contribute much in LINPACK, but do in real workloads, the Aurora A21 machine should have had a raw theoretical peak performance of about 1.4 exaflops to hit that 1 exaflops sustained floor that Argonne set for the revised deal.
Well, if you do the math on the node count and Ponte Vecchio performance at 64-bit precision (which we did not do to our great shame), you end up with a 9,000-node machine that delivers at least 2.43 exaflops. So the performance was in what Intel had been saying all along. Somewhere in the back of our minds, we must have been thinking if FP32 was 45 teraflops for Ponte Vecchio, then FP64 would naturally be 22.5 teraflops, and that would mean an Aurora machine with 1.22 exaflops at double precision. It fit our preconceived notion, so we didn’t think about it further.
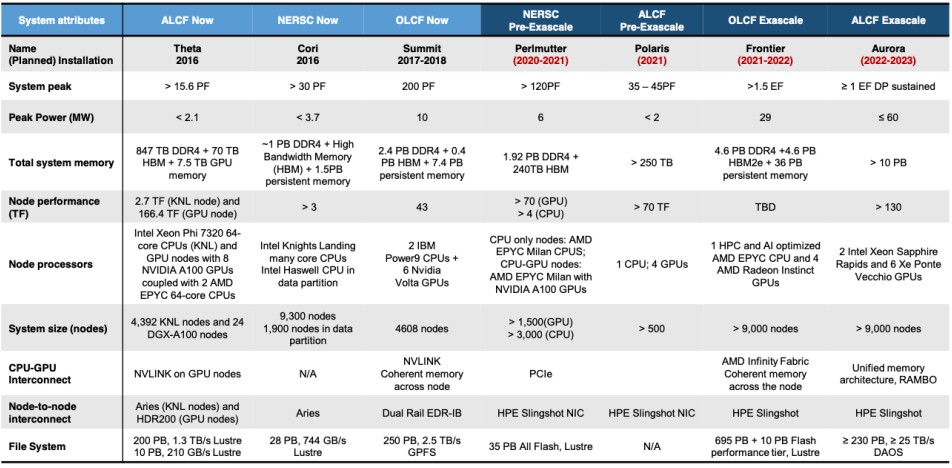
Also, tables like this one above from the Exascale Computing Project, which we walked through in our analysis of Frontier and Aurora earlier this month, didn’t help, since when someone says ≥ 1 EF DP sustained we all assume that it is close to 1 exaflops and they are not deliberately obfuscating. Hopefully what Gelsinger did not mean is that Aurora is going to have a peak performance of over 2 exaflops but only deliver a little more than 1 exaflops sustained performance on the machine. That would be less than a 50 percent computational efficiency, which would frankly be terrible. We don’t think that was what Intel meant. But the feature image used in this story clearly says over 2 exaflops of peak performance, just for the record. And if the Aurora hardware and software is as computationally efficient as we think it is, and if it is really somewhere around 2.43 exaflops peak, it should hit somewhere around 1.7 exaflops sustained on LINPACK.
So, in the course of it all, what seems to have happened is that Ponte Vecchio has a lot more oomph than Intel was planning on, and Gelsinger said as much to us as he tried to explain that $300 million writeoff. Here is the full quote:
“Clearly, with the original concept of Aurora, we have had some redefinition of the timelines, of the specs associated with the project’s effort,” Gelsinger said, and that is the understatement of the year. And it was also not on his watch, which is very much a different one from his predecessors. “Obviously, some of those earlier dates when we first started talking about the Aurora project moved out and changed the timelines for a variety of reasons to get there. Some of those changes, it will lead to the write off that we are announcing right now. And basically, the ways contracts are structured, part of it is that the moment that we deliver a certain thing, we incur some of these write offs simply from the accounting rules associated with it. As we start delivering it, some of those will likely get reversed next year as we start ramping up the yields of the products. So some of it just ends up being how we account for and how the contracts were structured. On the two exaflops versus one exaflops bill, largely Ponte Vecchio, the core of the machine, is outperforming the original contractual milestones. So when we set it up to have a certain number of processors — and you can go do the math to see what 2 exaflops is — we essentially overbuilt the number of sockets required to comfortably exceed 1 exaflops. Now that Ponte Vecchio is coming in well ahead of those performance objectives, for some of the workloads that are in the contract, we are now comfortably over 2 exaflops. So it was pretty exciting at that point that we will go from 1 exaflops to 2 exaflops pretty fast.”
It’s great that Argonne is getting a much more powerful machine — if we are right, then 2.4 exaflops instead of 1.4 exaflops at peak — but we doubt very much anyone is going to use the word “fast” when talking about how Intel was moving. This machine will have taken nearly four years to get into the field and functional when it is running early next year.
The Aurora installation has, by the way, begun, and here is photographic evidence, however blurry:

So why is this important right now? For political reasons, of course. First, now Argonne will have a machine that has a higher raw performance than the “Frontier” hybrid CPU-GPU machine being built by Hewlett Packard Enterprise with AMD motors. (Both Frontier and Aurora are using the “Shasta” Cray XE system and Slingshot interconnect to lash the nodes together.) That machine, which cost $600 million, is expected to have more than 1.5 exaflops of peak performance at 64-bit floating point precision. So it is the politics between Department of Energy HPC facilities that is coming into play. Argonne wants to have a bigger machine than Oak Ridge, which is natural enough. The “El Capitan” CPU-GPU supercomputer going into Lawrence Livermore National Laboratory starting next year and fully ready for service in 2023 — and missing from the chart above for some reason — is being built by HPE, too. But it is using later generations of AMD CPUs and GPUs (and off the shelf rather than custom ones at that) and is slated to be “in excess of 2 exaflops” peak performance. And it will do so in somewhere above 30 megawatts (the original goal) and substantially less than 40 megawatts (what the lab told us more recently). As far as we know, Frontier is rated at 29 megawatts, but Aurora is coming in at around 60 megawatts. So while Aurora might end up being the most powerful supercomputer in the United States for the next several years, it will also possibly be the most power hungry.
Why is Aurora pushing perhaps as high as 2.4 exaflops peak important? Intel beats AMD, and the United States beats China. As we reported yesterday, China already has two exascale-class machines in the field that it has run LINPACK on — and did so back in March in plenty of time for the June 2021 Top 500 rankings. But it did not submit the results and therefore make them public. The Sunway “Oceanlite” machine at the national supercomputing center in Wuxi is rated at 1.3 exaflops peak and 1.05 exaflops sustained on LINPACK, making it the fastest machine in the world right now. The Tianhe-3 machine at built for NUDT in China is rated at 1.3 exaflops peak as well and has gone above 1 exaflops on LINPACK, according to our sources. If Aurora performs as we expect based on what Intel is now saying, it could be the number one machine for a while.
That brings us all the way back to zettascale by 2027. Yes, it sounds crazy. We will say it again: Yes, that sounds ab-so-freaking-lutely bonkers, especially after all the machinations that Intel has been through with Aurora. But Gelsinger clearly believes Intel has a path to actually achieve zettaflops in the next five years (2021 is basically done, but it is really more like six years) or he would not say a peep about it.
If you built a zettaflops Aurora machine today, assuming all of the information that we have is correct, it would take 411.5X as many nodes to do the job. So, that would be somewhere around 3.7 million nodes with 7.4 million CPUs and 22.2 million GPUs burning a mind-sizzling 24.7 gigawatts. Yes, gigawatts. Clearly, we are going to need some serious Moore’s Law effects in transistors and packaging.
If Intel doubled compute density every year for both its CPU and GPU components, it would still take somewhere around 116,000 nodes to do the zettaflops trick. And if it could keep the node power constant — good heavens, that is a big IF — it would still be 772 megawatts. Lowering the power and the node count while driving up performance by a factor of 411.5X on the node and system level … tilt.
And here we were thinking the next five years were going to be boring. Apparently, we are going to witness technical advances so great they will qualify as magic. We look forward to seeing how this Zetta Initiative unfolds. You got our attention, Pat.


Sometimes The Road To Petaflops Is Paved With Gold And Platinum
Supercomputing, with a few exceptions, is a shared resource that is allocated to users in a particular field or geography to run their simulations and models on systems that are much larger than they might otherwise be able to buy on their own. Call it a conservation of core-hour-dollars that …

For CPU Makers and OEMs Alike, It’s A Platform View
Dell took a look at the two weeks between the rollouts by AMD and Intel of their latest server processors and, after some debate, decided to unveil its entire portfolio of new and enhanced systems – featuring the new chips from both vendors – at the launch of AMD’s latest …
Ampere Readies 256-Core CPU Beast, Awaits The AI Inference Wave
How many cores is enough for server CPUs? All that we can get, and then some. For the past two decades, the game in compute engines has been to try to pack as many cores and additional functionality as possible into a socket and make the overall system price/performance come …
This is a great step in the right direction but I will believe it when I see it. Intel has been redrawing Aurora plans since the day they got the contract, went through 4 or 5 design choices for the processor. Of course, they want to get better publicity and show that they are fighting back, but really, they should just give up the Aurora and let HPE do the prime, and focus on improving their stance in processor design, power, memory, storage and manufacturing.
“At IEDM 2021, Intel demonstrated the world’s first experimental realization of a magnetoelectric spin-orbit (MESO) logic device at room temperature, which showed the potential manufacturability for a new type of transistor based on switching nanoscale magnets.”
https://www.intel.com/content/www/us/en/newsroom/news/intel-components-research-looks-beyond-2025.html
I think this must be the silver bullet for zettascale by 2027…
LINPACK is easy, and the industry should just stop quoting it. The real question is application performance. As in, “do we get 10x application performance compared to Summit, which is rated at 200 PF peak, for DOE applications?” I don’t think that will happen for Aurora.
Ben – The DOE typically does list performance requirements for a bunch of their preferred codes, typically in terms relative to prior machines. The linpack number is for the press, and for the government bureaucrats who need a single number to look at. When I say press, I don’t mean nextplatform or hpc wire, but more general interest press that doesn’t have the time or expertise to dig into anything other than “Big machine X times faster than last year’s big machine!”
“This machine will have taken nearly four years to get into the field …”
Optane, DAOS, CXL, DDR5, AMX, PCIE5, DSA, foveros 3D manufacturing at a scale unseen before … all leading edge features. Sapphire Rapids was sampling in Nov 2020, but this HBM version appears to have been a late addition. Quite a list of features that are unmatched by the competition.
Intel’s delivered a huge amount of software as well… all that oneAPI code.
The whole point of saying 2 EF is so they can deliver 1EF usable performance. Intel delivered nothing yet as of today – What relevant software are you referring to? Who cares about oneAPI? They only state it because now they want to sell just another GPU system which others have been doing for more than 10 years. Where is the innovation? The original interconnect is dead, DDR5 and PCIE5 are industry standard, DAOS is blah … whats the point of it than to try and sell more NVMe … if they really want to derisk they need to just get a Lustre file system and call it a day, focus on the silicon. All this nonsense while ORNL and China already deployed Exascale systems with much higher efficiency and working perfectly. Intel keeps shooting itself in the leg and asks “why , me?”. Really, we are aiming for ~50% efficiency for a leading system in 2022? Who are they kidding? If Pat knows whats good for Intel, bow out of Aurora, pay ANL its money back and let them buy a machine from HPE/Cray. Enough of this long drawn mess and dragging ANL/DOE along. Only a fool keeps doing the same thing and expects a different result – both Intel and ANL are doing the same thing over and over since the past ~6+ years and expecting a different outcome.
The point must be that Intel wants to stay relevant in HPC, which means having some sort of accelerator. They must believe that Xe has merit in the HPC business, or at least that the successor will have merit. Bailing on the contract now will not only kill Intel as a prime contractor, but it will make customers unlikely to trust Intel’s product roadmap for any non-prime deals. Why would HPE/Dell/Atos/etc propose a machine based on Intel’s accelerator instead of Nvidia or AMD? Intel has to deliver a better product (price/performance) and engender trust that they can actually deliver what they promise. Intel already walked away from their previous HPC accelerator architecture, which really was the result of walking away from a prior accelerator that never made it to market. If they walk away from another, and leave the customer holding an empty bag, they will lose a lot of good customer credibility.
Intel has viewed reality thru the lense of marketing for far too long.
It’s best for Patrick Gelsinger to stop making public appearances unless he has the product is already shipped and reviewed by external reviewers.
All this noise will have negative impact on Intel. Patrick Gelsinger should behave like a CEO instead of marketing executive or a car salesman.
With 60Mw of consumption it needs a very good electrical supply
Keeping it running is going to be very expensive