
When Nvidia announced a deal to buy Mellanox Technologies for $6.9 billion in March 2019, everyone spent a lot of time thinking about the synergies between the two companies and how networking was going to become an increasingly important part of the distributed systems that run HPC and AI workloads. As far as we know, not every many people were thinking that the analog signaling circuits that Nvidia has created to link its GPUs to each other and to extend its systems were a strategic part of the deal.
But, as it turns out, they are. And very specifically, Nvidia’s expertise in designing serializer/deserializer circuits – that part of a chip that takes parallel data streams and turns it into a serial data stream suitable to be sent out over a network – has been instrumental in the new Spectrum-4 800 GB/sec Ethernet switches that Nvidia (formerly Mellanox) announced at the GTC conference recently.
We knew that Nvidia was pretty good at SerDes when we saw the 20 Gb/sec NVLink ports on the “Pascal” GP100 GPUs for the datacenter back in 2016, and we really saw that the company was serious about SerDes when it divulged the NVSwitch memory area network switches at the heart of the DGX line of systems based on the “Volta” GV100 and “Ampere” GA100 GPUs, And the free-standing, multi-layer NVLink 4.0 memory interconnect for GPUs that will be employed in the future DGX H100 systems based on the “Hopper” GH100 GPUs are extremely high bandwidth and low latency switches, which we talked about in detail here and which have circuits that rival anything that Mellanox, Broadcom, Marvell, and others can bring to bear.
In fact, the SerDes expertise that Nvidia has developed has been extremely valuable to the Mellanox team, and it is one of the reasons why with the Spectrum-4 switch, the company is jumping from the 12.8 Tb/sec aggregate bandwidth of the Spectrum-3 ASIC announced in March 2020 straight over a 25.6 Tb/sec device that many had been expecting to the 51.2 Tb/sec Spectrum-4 ASIC.
“On the digital side, with the packet processing engines, what I will say is that Mellanox was way ahead of everyone else in the market,” declares Kevin Deierling, vice president of marketing for Ethernet switches and DPUs at Nvidia. “I think we had the world’s best digital switch. And now, as part of Nvidia, we are leveraging the world’s best analog SerDes, which come from Nvidia. The analog circuits are usually the long lead item to get to the chip, and you have got to make sure that it is going to work. The packet engine, the digital part of the die, if you simulated it, that is the way that it behaves and that is it. With analog, it is as much an art as it is a science.”
Deierling is not ready to talk specifics about precisely which SerDes from Nvidia are used in the Spectrum-4 ASIC, but he did tell us that the performance and power of the SerDes and the savings on optical transceivers are going to be a big part of the Spectrum-4 story, which Nvidia will reveal to us later this year in a deeper dive before the ASICs and their companions ConnectX-7 SmartNICs and BlueField-3 DPUs are all shipping in volume. We strongly suspect that the same SerDes in the S[pectrum-4 are used in the NVSwitch 3 and the NVLink Switch 1 chips, but we can’t prove it yet.
What we can tell you is that the Spectrum-4 ASIC is actually a collection of chiplets that are integrated, and Deierling is not at liberty to say. As far as we know, both the digital package and the communication SerDes that wrap around it are implemented in the same 4 nanometer 4N process, which comes from foundry partner Taiwan Semiconductor Manufacturing Co and that is also used to etch the new “Hopper” GH100 GPU. Interestingly, the Hopper GPU is a monolithic die with 80 billion transistors while the Spectrum-4 ASIC has a chiplet architecture and has 100 billion transistors in the entire complex.
In the future, it is reasonable to expect that the packet engine will shrink to smaller transistor geometries, but given that making a SerDes smaller does not always yield better performance, that the SerDes chunks of the Spectrum ASIC complex for future generations will stay at the 4N process. AMD has done the same with the I/O hub in its Epyc processor complexes. With the “Milan” Epyc 7003s, the I/O hub is etched in GlobalFoundries 12 nanometer processes, but the compute core dies that hook into it are etched in 7 nanometer processes from TSMC.

The packet engine at the heart of the Spectrum-4 ASIC can handle 37.6 billion packets per second, which is 4X what the Spectrum-2 could handle at 9.52 billion packets per second and what we reckon was around 19 billion packets per second for Spectrum-3, or about 2X the throughput. The packet processing rate does not always go up in lockstep with the bandwidth growth with switch families, and Mellanox has always tried to beat the competition on this metric. The Spectrum-3 chip was a monolithic die etched in TSMC 16 nanometer processes.
As with prior Spectrum ASICs, the SerDes on the Spectrum-4 ASIC complex can be ganged up in groups of 2, 4, or 8 to create Ethernet ports at given bandwidths – in this case, 200 Gb/sec, 400 Gb/sec, and 800 Gb/sec because the lane speed is 100 Gb/sec (after encoding overhead is taken off, that is). The native signaling rate is running at 50 Gb/sec and with PAM-4 pulse amplitude modulation encoding, which allows two bits to be passed per signal, the effective lane speed comes to 100 Gb/sec. So with 2, 4, or 8 lanes the Spectrum 4 chip can drive 256 ports at 200 Gb/sec, 128 ports at 400 Gb/sec, and 64 ports at 800 Gb/sec – the latter of which is important for datacenter interconnects within a region that can be spanned by Ethernet wires.
Also important for those datacenter interconnect (or what is called DCI) use cases is the fact that the Spectrum-4 ASIC has built in MACsec encryption, which means data in flight can be encoded at one quarter of the line rate (or probably more precisely, on one quarter of the ports running at 800 Gb/sec or all of the ports running at 200 Gb/sec). The average encryption rate for switches used for DCI applications among hyperscalers and cloud builders is around 4 Tb/sec, so this is more than 3X that rate.
It would be very interesting to see a use case where Nvidia could break the Spectrum-4 ASIC down to host 512 ports running at 100 Gb/sec, and to contemplate how many switch hops in a Clos all-to-all topology spine/leaf network could be eliminated. But we suspect that many customers will be happy with a 12:1 compression if they move to 200 Gb/sec ports on the servers. Like this:
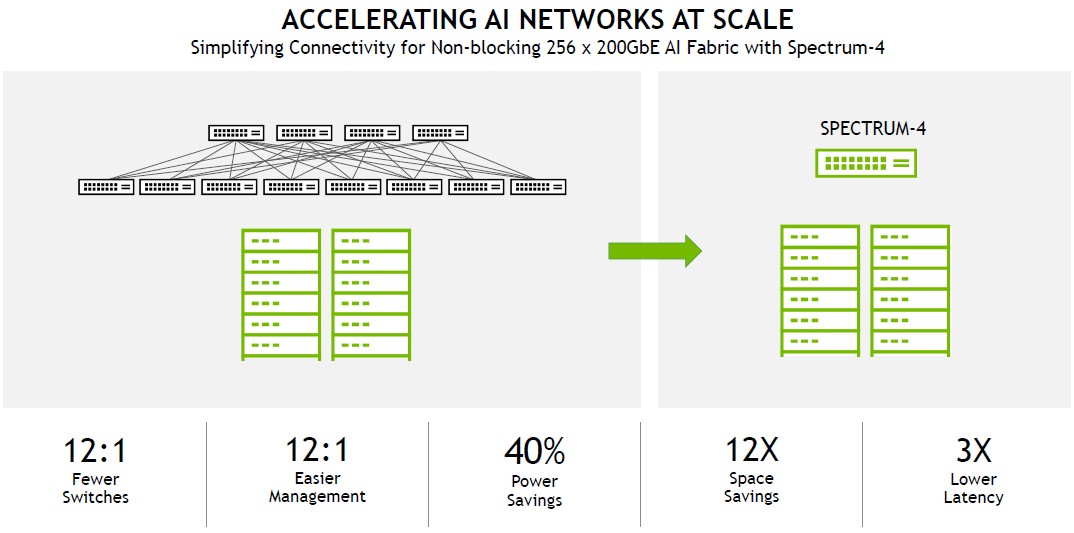
To connect 256 servers with Spectrum-4 means all of the machines are one hop away from each other. To connect the same 256 servers with Spectrum-3 switches would require 12X as many switches to make the spine/leaf network and would require an average of three hops between servers over the switch fabric, increasing network latency by a factor of 3X.
Pricing has not been set for the Spectrum-4 chips and switches as yet, but Nvidia will sell complete switches as well as ASICs as Mellanox always did. The rule of thumb on pricing is that for any given generational jump, the bandwidth per port goes up by 2X and the cost per port up by 1.5X to 1.6X. Seeing as though Nvidia is skipping over the 25.6 Tb/sec ASIC generation, that should mean an 800 Gb/sec port should run somewhere around $1,800 to $2,000, which is consistent where 100 Gb/sec ports started out back in 2015 when the 100 Gb/sec wave first started to build. This is also consistent with the fact that 400 Gb/sec ports are running at close to $1,000 right now.
The last big new technology that is coming out with the Spectrum-4 switch from Nvidia is adaptive routing and improved direct memory access between server nodes using the RoCE protocol, which is a riff on the RDMA direct memory access that gives InfiniBand (which Mellanox and now Nvidia champions) such low latency.
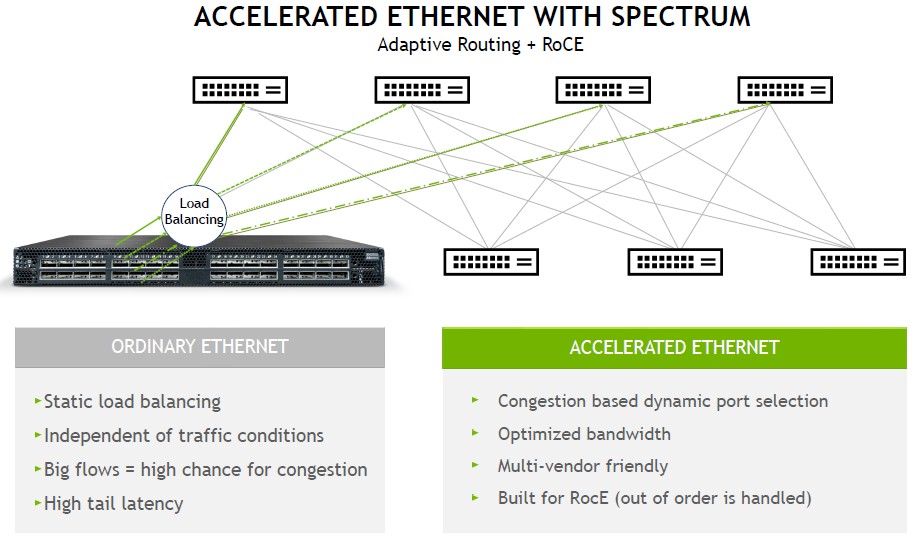
The adaptive routing is important, particularly for AI training workloads and distributed databases – places where Mellanox was getting traction with Spectrum ASICs among those who did not want to use InfiniBand.
“We have learned so much about AI and about databases,” explains Deierling. “In the traditional networking model, you have a ton of CPU threads and a ton of sockets that you are connecting to, and you have a ton of flows over the network. And here, you could use static routing such as Equal Cost Mutli-Path, or ECMP, routing. And everything works fine because these are mouse flows and applications really did not need to exchange a lot of data. But with AI and database workloads, they do, and you get these elephant flows, and with elephant flows you need to be a lot more careful. We determine where elephant flows are happening and we make sure that we don’t send too many of them on the same link, and so we achieve optimum bandwidth so these huge workloads can run at scale.”
Deierling says that this adaptive routing technology was derived from InfiniBand’s own adaptive routing, which it has had since the beginning and which is possible because InfiniBand was “software-defined networking before it was cool,” and is being added to its Ethernet products at the behest of two of the hyperscalers and cloud builders. One of them, we strongly suspect, is Microsoft, which is a big customer for Nvidia InfiniBand, but the other one might be Google.
Here is why we think that. Also new in the Spectrum-4 switch is a feature called ultra accurate timing, which implements the Precision Time Protocol and which is necessary in massive, distributed databases. With the Network Time Protocol, which has been around in networks for 35 years now, the best you can do is on the order of 10 milliseconds down to maybe 1 millisecond of synchronization. Anything that needs to be finer-grained than that requires some other timing mechanism – Google, for instance, uses atomic clocks in its datacenters to synchronize data reads and writes across its Spanner distributed database. With the ultra accurate timing feature in the Spectrum-4 ASIC, dataflows can be stamped with a precision down to tens of nanoseconds, which is sufficient enough to keep track of the order of writes to a database and make sure reads to a section of data are done after the writes are finished.
Such fine-grained, network-based data synchronization is necessary for all of the hyperscalers and cloud builders that use or sell massive scale databases, as well as their customers who are running them on infrastructure or using them as a service from these hyperscalers and cloud builders. But it would be interesting to see if Nvidia can win a networking deal with Google.


Academia Gets The First Production Cray “Shasta” Supercomputer
Indiana University is the proud owner of the first operational Cray “Shasta” supercomputer on the planet. The $9.6 million system, known as Big Red 200 to commemorate the university’s 200th anniversary and its school colors, was designed to support both conventional HPC as well as AI workloads. The machine will …
Ethernet Consortium Shoots For 1 Million Node Clusters That Beat InfiniBand
Here we go again. Some big hyperscalers and cloud builders and their ASIC and switch suppliers are unhappy about Ethernet, and rather than wait for the IEEE to address issues, they are taking matters in their own hands to create what will ultimately become an IEEE standard that moves Ethernet …

AIST Taps HPE And Nvidia For Next-Gen AI Cloud Machine
The National Institute of Advanced Industrial Science and Technology (AIST) in Japan is going to be installing the third generation of its AI Bridging Cloud Infrastructure 3.0 supercomputer. The machine will consist of thousands of Nvidia’s current “Hopper” H200 generation of GPU accelerators, which is not surprising. But interestingly, it …
Be the first to comment