

Emulation is not just the sincerest form of flattery. It is also how you jump start the adoption of a new compute engine or move an entire software stack from one platform to another with a different architecture. Emulation always involves some form of performance hit, but if you are clever enough, it can be modest and a fair compensation for the time and effort saved in actually porting code from one compute engine to another.
With CPUs now getting both vector and matrix math units and with a shortage of GPU compute engines compared to the huge demand thanks to the generative AI boom, there is without question not only a need for alternatives to the CUDA parallel programming environment that Nvidia created as the core of its GPU compute platform, but a need to run CUDA codes on anything and everything that can do vector or matrix math. Alternative and parallel (in terms of features and functions) programming environments such as HIP from AMD (part of its ROCm stack) and SYCL from Intel (the core of its oneAPI effort) can help CUDA programmers take their knowledge and apply it to a new device, which is great. But there is plenty of fussing around with some parts of the code and there is not yet a universal emulator that can convert CUDA to any GPU or CPU.
What we need for GPU and CPU vector/matrix compute is something akin to the QuickTransit emulator, which was created by a clever team of techies at the University of Manchester, which launched in 2004 as a commercial products by a company called Transitive after four years of development, and which had huge potential to upset a lot of server platform apple carts in the datacenter, but didn’t for reasons that will become obvious in a second.
Many of you have used QuickTransit without knowing it. Supercomputer maker SGI was the first to employ this emulator as it shifted from MIPS to Itanium architectures, and Apple followed suit, basing its own “Rosetta” emulation environment on QuickTransit as it shifted from PowerPC to Intel Core processors for its client computers. IBM acquired Transitive in 2008 and basically sat on the technology because it was too dangerous to let loose. (Big Blue did use it to provide an X86 runtime environment for Linux on its Power iron, which it withdrew from support in 2012.)
We don’t have QuickTransit for GPUs, but we do have something with the unwieldy name of Cuda for Parallelized and Broad-range Processors out of researchers from the Georgia Institute of Technology and with contributions from Seoul National University that can take CUDA kernels and automagically port them to run on the LLVM compiler stack and execute on GPUs or CPUs. (Interestingly, Chris Lattner, one of the creators of LLVM, is chief executive officer at Modular AI, which is creating a new programming language called Mojo to provide a kind of portability for AI applications at a higher level across many devices.) This CuPBoP framework is a bit like QuickTransit in concept, but is a very different beast entirely.
The CuPBoP framework was introduced in a paper published back in June 2022, and the source code for the framework is available on GitHub. CuPBoP came to our attention this week as the Georgia Tech researchers released a variant of the framework called CuPBoP-AMD that is tuned to work on AMD GPUs and that presents an alternative to AMD’s HIP environment in ROCm to port Nvidia CUDA code to AMD GPUs. Lots of people are thinking about that now that AMD is shipping its “Antares” MI300X and MI300A compute engines, which can stand toe-to-toe with Nvidia “Hopper” H100 and H200 devices. The CuPBoP-AMD paper is at this link. (This framework needs a better name, folks. . . .)
While AMD and Intel talk about porting or emulating CUDA applications, here is how the Georgia Tech team sees the situation as of when this latter paper was presented at the SC23 supercomputing conference in Denver:
“Intel has a Data Parallel C++ (DPC++) library called SYCLomatic for converting CUDA to SYCL, which has runtime support for AMD GPUs for ROCM 4.5.1, but it is in beta mode without complete feature support at the time of this writing. AMD utilizes HIPIFY for source-to-source translation of CUDA to HIP. However, HIPIFY does not account for device-side template arguments in texture memory and multiple CUDA header files “.cuh”. Thus, manual manipulation by the developer is required in HIPIFY. Manual manipulation by developers can be cumbersome in large repositories of CUDA programs, which is a reason the CuPBoP framework aims to resolve. CuPBoP is a framework to allow the execution of CUDA on non-Nvidia devices.”
The trick with CuPBoP, in part, is to use the LLVM framework and its Clang compiler, which can compile both Nvidia CUDA and AMD HIP programs to a standard intermediate representation (IR) format, which in turn can be compiled into a binary executable for the AMD GPUs. The CuPBoP compilation pipeline looks like this:
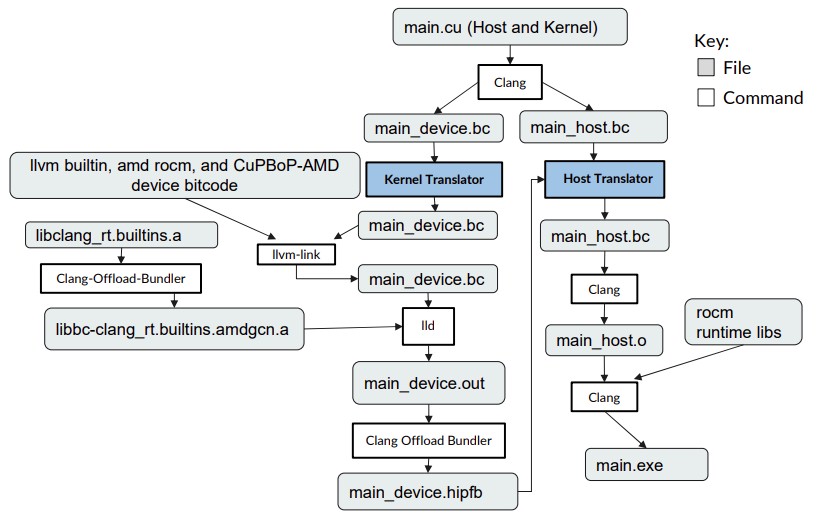
The CuPBoP framework creates two IR files, one for the kernel code and one for the host code, and it is at this IR level that the translation to the AMD GPUs is done rather than at a higher level where translating macros and separate header files gives AMD’s HIP tool some trouble.
At the moment, the CuBPoP framework only supports the CUDA features that are used in the Rodinia Benchmark, a suite of tests created by the University of Virginia to test current and emerging technologies that first debuted back in 2009, right as GPUs were starting to make their way into the datacenter. The Rodinia applications and kernels cover data mining, bioinformatics, physics simulation, pattern recognition, image processing, and graph processing algorithms – the kinds of things that advanced architectures are created to better tackle.
Here is how CuPBoP-AMD variant of the CuPBoP framework lines up against AMD’s HIPIFY tool in the ROCm stack:
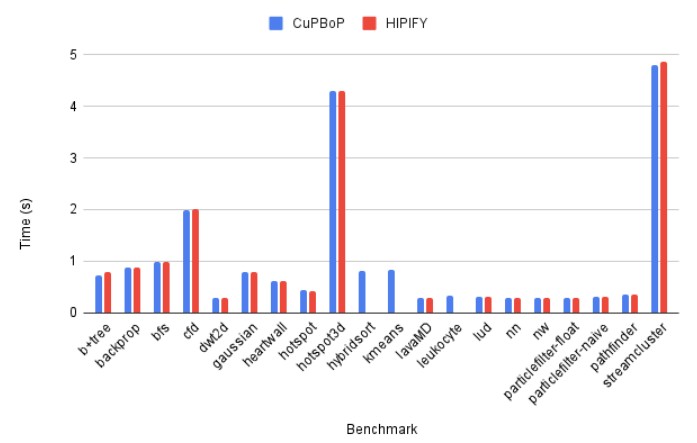
In terms of the execution of CUDA code that has been translated to run on AMD GPUs, the performance of CuPBoP-AMD looks to be indistinguishable from HIP. We would love to see how this translated CUDA code compares to running natively on Nvidia A100, H100, and H200 GPUs, of course. The researchers say that CuPBoP-AMD is still a work in progress and more Rodinia Benchmark features need to be enabled. And that is always the issue with emulators and translators: They are always playing catch up. But, then again, they allow a new platform to actually catch up faster.
The wonder is that AMD has not already bought the rights to this tool and hired the Georgia Tech team . . .




So its CUDAN for AMD? mb
Not really. It’s more like a translation layer added to ROCm to convert CUDA calls to ROCm calls. The only problem of it is, it would only work with existing CUDA and would take time for new extensions to be added if the spec evolves.
The main purpose I would argue is that this translation exists so that AMD gpu’s can be used for hw acceleration in software that’s CUDA bound with no loss in performance or efficiency, so in reality, there would be no need to worry if it works with NV hw or not, since the software can just default to original CUDA if an NV gpu/accelerator is detected in the system.
Unless they are looking to replace CUDA with CuPBoP-AMD, but not sure how that would work if the software relies on CUDA for making use of the GPU in the first place and CuPBoP-AMD just acts as a translation so AMD accelerators and GPU can be used for HW acceleration (effectively enabling CUDA to run on AMD).
So, not really sure why they are bothering with NV hw to start with since they can work off the original CUDA code.
At this point its just a matter of integrating the CuPBoP-AMD so AMD hw can be used in AI and pro software instead.
Way to ROCm SOCm with HIPly syncopated CuPBoP Bebop! The GIT’s Clang-Clang of compiler pipeline dancing in the moodycamel queue, QuickTransit stepping with the best Mojo! The rotund Rodinia benchmarking the dancefloor, with Warp-Level function supporting its motion! CUDA woulda shoulda, toe-to-toe SYCLomatic, in one fell IR swoop, clearly automagic! 8^b
Let’s kick a verse for my man called Miles
‘Cause seems to me he’s gonna be ’round for a long while
‘Cause he’s a multi-talented and gifted musician
Who can play any position
It’s no mystery that you’re no risk to me
‘Cause I’m the lover and tell your girl to throw a kiss to me
And hop in bed and have a fight with the pillow
Turn off the lights and let the J give it to ya
And let the trumpet blow as I kick this
‘Cause rap is fundamental and Miles sounds so wicked
A little taste of bebop sound with the backdrop of doo-hop
And this is why we can call it the doo-bop
Now go ahead and play like a wannabe
You know it’s gonna be
I hate to cut the throats of MC’s up in front of me
When I’m out blow make the A want to sing
My rhymes be shining on brothers
Like they flippin’ on they high beams
And when I just come through
You think you bad ’cause somebody has seen you
Climbing the tree like Jack Be Nimble
Yo, Miles blow the trumpet off the symbol
Miles Davis style is different, you could describe it as specific
He rip, rage and roar, no time for watchin’ Andy Griffith
You can (whistle) all you want, go ahead
While he take to doo-hop and mix it with bebop
Just like a maker in the shoe shop
Easy Mo Bee will cream you like the nougat
And usually we doo-wop but since Miles wanna cool out
You can do that Miles, blow your trumpet
Show the people, just when it’s to doo-bop
– Miles Davis
Sorry. Hadda do it
No apologies, man. You’re good.
At Least Intel’s OneAPI and associated GPU compute stack works for Intel’s Consumer Meteor Lake processors so folks can use the ARC Graphics Tile on Meteor Lake for Blender 3D GPU accelerated Cycles Rendering workloads as Phoronix’s testing has shown in that article published on 12-20-2023 that’s testing the Meteor Lake Integrated Graphics for compute workloads on Linux. And as for AMD’s ROCm/HIP and GPU compute for AMD’s latest iGPUs, the Rzdeon 680M/780M iGPUs, that’s got no ROCm/HIP support so no results can be shown from AMD’s iGPU hardware.
And Michael at Phoronix describes as:
“The Intel Meteor Lake processors enjoy support already by the Intel Compute-Runtime stack providing OpenCL 3.0 support as well as oneAPI Level Zero support. Loading up the existing Intel Compute Runtime, oneAPI Level Zero Loader, and IGC with the existing upstream Linux 6.7 yielded the Arc Graphics GPU compute support “just working” without any fuss. In comparison, AMD doesn’t officially support ROCm on their integrated graphics products with the with the official support at least for ROCm on consumer Radeon GPUs being a mess… Not to mention the ROCm binaries catering just to a set of enterprise Linux distributions/versions. So in the case of loading up the Intel Compute Runtime atop Ubuntu 23.10 with Linux 6.7 and having everything just work as intended is terrific.” (1)
And as we all Know the Blender Foundation has dropped support for OpenCL as the GPU Compute API for Blender 3D 3.0/Later editions that only support Nvidia’s CUDA and Apple’s Metal GPU graphics/compute APIs and so AMD and Intel have to use their respective ROCm/HIP and OneAPI/related software stacks to take that CUDA and transform that to a form than can be run on the respective AMD and Intel GPU hardware.
(1) [See Page 6 of the article for the iGPU compute test results]
“Intel Meteor Lake Arc Graphics: A Fantastic Upgrade, Battles AMD RDNA3 Integrated Graphics
Written by Michael Larabel in Graphics Cards on 20 December 2023.”
https://www.phoronix.com/review/meteor-lake-arc-graphics
For the Ryzen 7940hs processor, you can get HIP code running as follows. Install Visual Studio 2019. Install AMDs HIP stack for Windows. Open one of the rocm-examples in VS. Change the Properties > General[AMD HIP for clang] > Offload Architectures value, add device string gfx1103 to the list. The code will compile and run. I have the Floyd Warshal example running this way. There is also an environment variable HSA_OVERRIDE_GFX_VERSION which can be set to 11.0.3, and I am told this works for Linux too.
This is much like CUDA with it’s compute_NN values and sm_NN values. Though CUDA is more friendly, it’ll fall back to runnable spec code on newer silicon if your config strings are old. HIP just drops core at kernel launch if I haven’t included the right arch string at compile time.
I almost have HIP Caffe compiling on Windows 11 lol.
Please stop stripping out all the CRs and empty line spacing of posts here as that’s just wrecking the readability of the replies and turning them into huge walls of Text that are not very human readable!
I am not doing any such thing. Perhaps the tech people need to take a gander.
Um…. How long has openCL been around? (Quick check: Wikipedia sez over 14 years)
Multiplatform, multios, works on all GPUs (and many CPUs), supported by AMD, Intel, Nvidia and most other GPU houses
So why are programmers persisting with proprietary extensions? (Hint: MSIE wasn’t a “standard” either)
The Blender Foundation stopped supporting OpenCL with Blender 3D 3.0 and only natively supports Nvidia’s CUDA or Apple’s Metal GPU graphics/compute APIs! And so for AMD’s GPUs to be able to be used with Blender There has to be the ROCm/HIP translation stack employed to take the CUDA and translate that to a form that can be run on AMD’s Radeon hardware. And ditto for Intel’s OneAPI and making that CUDA work for Intel’s GPUs. So just you try and Get Blender 3D 3.0/later to emit anything but some CUDA or Metal compatible Intermediate Representation there for anything but Nvidia’s or Apple’s respective GPU drivers to consume. AMD and Intel have to eat the CUDA and translate that to work with Blencer3D 3.0/later editions on their respective GPU hardware.
And Linux has never had a good cross platform Modern OpenCL implementation in the MESA driver package supported over the years and that’s part of the reason that the Blender Foundation dropped OpenCL support in favor of CUDA/Metal. And Linux/MESA is only now getting a more modern OpenCL supported with the Rusticl(OpenCL) project(Modern OpenCL implementation written in Rust) added to the MESA driver packages that ship installed on most Linux Distros. It’s good for any Linux Applications that still use OpenCL as the GPU compute API but too late for Blender 3D 3.0/Later editions.
A not so hassle-free could be transpiling/transcoding (a word borrowed from video processing workflows) Nvidia Cuda high level code to Python style and feed the new Mojo compiler with that.
Some smart persons would use the new AI LLM methods augmenting the conversion phase with more accuracy.
Language2Language Transformers: machine learning to build transpilers.
(https://tomassetti.me/language2language-transformers-machine-learning-to-build-transpilers/)
I remember QuickTransit with fondness and sadness: fondness, because it was extremely cool and sadly, because IBM bought it and put it into their ‘poison locker’, so it couldn’t be used “the right way”, which would haven been a better Hercules (z/Arch emulator) or what Gene Amdahl had been working on in his later career.
That they licensed it to mainframe customers who might want to x86 workloads on z/Arch was almost too painful to bear!
The problem is, that something as simplistic as QT won’t do the job here. QT is at a similar level as the internal translation engines of x86 CPUs that take the x86 ISA and turn it into their respective native codes or akin to Transmeta’s Crusoe.
If you’re in want of a metaphor, it enables a guy who’s used to build a cottage from mud bricks, to erect a similar structure from autoclaved aerated concrete blocks.
But in CUDA the job is to build a Cheops pyramid before people forget who Cheops was (at least they managed to preserve the corpse while it was waiting). You can’t just dump thousands of cottage makers on a pile of bricks and have them build a pyramid: they need to be finely orchestrated in variable sized teams meshed in several levels of gears. Any individual stepping out of the carefully synchronized dances creates havoc.
And that dance script cannot be translated to an Eiffel type wrought iron or pre-stressed concrete variant of the pyramid by translating the worker’s instructions from ancient Egyptian to the Hindi the current crew understands.
The challenge here is that it’s not about translating the code, it’s about translating the various layers of abstractions that CUDA also had to create in order to have thousands of cores work with the least amount of waste on a huge undertaking. And that IMHO also creates a potential IP minefield, as those abstractions by themselves represent a significant body of work.
What helps, is that those who create the current wave of pyramid building instructions are very intent on avoiding to code in the Egyptian long prosed by team Nile-Green and try to use something more commonly spoken like this new Babylonian.
Well, this aged as it should’ve.
AMD is supporting HIP on 780M GPUs and Ryzen processors, the 680M is just asking too much. It was not based on the same gen as 6000 series desktop even.