
When Jim Keller talks about compute engines, you listen. And when Keller name drops a programming language and AI runtime environment, as he did in a recent interview with us, you do a little research and you also keep an eye out for developments.
The name Keller dropped was Chris Lattner, who is one of the co-founders of a company called Modular AI, which has just released a software development kit for a new programming language called Mojo for Linux platforms. Lattner is probably one of the most important people in compilers since Dennis Ritchie created the C programming language in the early 1970s at AT&T Bell Labs for the original Unix. Ken Thompson created its predecessor, B, also while at Bell Labs, and interestingly now works for Google, which we might even call Ma Search, and created the Go language for system-level programming (like Kubernetes) that is like many, many languages, a derivative of C.
Every new domain has its programming languages that evolve with that domain, and every platform has its preferences, as does every programmer. And thus, the cornucopia of programming languages have evolved in that Cambrian explosion manner. This magnificent programming language genealogy tree from Wikipedia, which was created by Maximilian Dörrbecker and which ends in 2008 so it is missing a bunch of stuff, gives a pretty good overview of the first couple of decades of the dominant programming languages beyond plug boards and assembler and how they relate to each other – or don’t. Love this:
{kind=link}
For many of us of a certain age, the dawn of the PC era meant that BASIC was transformative in our lives because it gave us the power of programming at a price that we could afford. But no one would call it a great language for creating complex, modern applications. Even in 1985. Many of us learned FORTRAN (now less shouty as Fortran) and COBOL and got a taste of other esoteric languages – ours were Pascal and Smalltalk. We talked about why Fortran persists and its skills gap problem recently.
We were too busy doing other things – starting businesses and raising families – to get into Java, PHP, and JavaScript, but we call these three out from the chart because they solved very specific problems in enterprise computing at the time, which is ultimately what we care about here at The Next Platform. We love theory, but we love practice more.
Java was created because C and C++ were too damned hard – and an unnecessarily so in a macho kind of way – for programmers in the enterprise who just want to craft business logic and not have to worry about system architecture. They wanted the ease of COBOL, RPG, and similar high level languages and they want to have the complexity of the underlying hardware – things you really need to know about with C and C++ – underneath a virtual machine that interprets the language and that allows for a certain degree of compilation for performance but which ensures the maximum platform portability. While some have joked that Java has the portability of C++ and the readability of assembly, it was an obvious improvement, which is why Java took off in the enterprise in application areas where performance, in an absolute sense, was not as much of a concern as programmer productivity and quick turn around on code. We had so many clock cycles and threads laying around, and you know the server makers were happy to sell machines to run this interpreted program rather than a strictly compiled one that ran like a bat out of hell on cheap iron. Still, when it comes to performance, a lot of modules of code are still written in C or C++ within a stack of Java.
PHP and JavaScript did for the front end of applications what Java did for the backend. There are others, of course.
Making such statements, we are bracing for – and absolutely expecting – contrarian opinions. There is nothing like talking about programming languages to bring out the prides and prejudices. Which is fun and fine. But make no mistake, and don’t just listen to all of the AI whitewashing that Modular AI is doing, which helped them to raise $100 million in venture funding two weeks ago. Lattner and his Modular AI co-founder, Tim Davis, don’t just want to fix AI programming. They want to fix programming. And if there are two people who can do that – in a way that Dennis Ritchie with C and James Gosling with Java and Ramus Lerdorf did with Personal Home Page – Lattner and Davis are those two.
The Lovechild of C++ And Python
Here in the third decade of the 21st century, if you asked programmers what language a newbie should learn, we think most of them would say Python, which is a language created by Guido von Rossum more than two decades ago to make it easier for programmers to do neat things.
Pythonic languages (and there are many) are not in love with their own complexity, just like languages such as BASIC, RPG, and COBOL are not. Other languages are definitely in love with their own complexity – and they are macho about it. But in this era where software makes up a by-far dominant portion of the overall IT budget, we don’t have time for this.
If you put a gun to the heads of most programmers and asked the same question – what programming language should you learn? – they would probably say C or C++ because they are universally applicable and ultimately more useful in terms of both portability and performance for both the code and their careers. In the corporate enterprise, the programmers would no doubt say Java, which is C++ playing on idealized hardware in a sense.
Lattner and Davis think this is a false dichotomy, and with Mojo they are creating a superset of Python that can do all of the same high-level stuff and can even absorb and run literal Python code in its runtime while at the same time giving Mojo the same low-level performance programming that C and C++ offer and that has given them such longevity in the market. (Maybe we can think of it as the lovechild of C++ and Python.) The Mojo runtime can do CPython code, but it can do its own stuff, too. And this is the key.
The pedigree of Mojo’s creators is impeccable. Lattner got a bachelor’s degree in computer science at the University of Portland and was a developer on the Dynix/ptx Unix variant for the big X86 NUMA boxes from Sequent Computer Systems for a while. Lattner got his master’s and PhD degrees from the University of Illinois at Urbana-Champaign after the Dot-Com Boom, and created the Low Level Virtual Machine project with his advisor, Vikram Adve. LLVM is, of course, integral to most compilers today, and it is a set of compiler tools that uses a language-independent intermediate representation that is constructed from any high-level programming language on its front end that can be targeted and compiled down to any instruction set for any kind of device on its back end. The important thing about LLVM, according to Lattner, is that it is modular and extendible through APIs – the LLVM toolchain is like the non-monolithic code that programmers are trying to create, which means they can tweak it to do all sorts of things.
While at Apple, Lattner drove the development of Clang and Swift, two C-alikes, and then did a brief stint at Tesla as vice president in charge of its Autopilot software, and then moved to Google to be the senior director of the TensorFlow AI framework that Google had open sourced a few years prior.
It was at Google that Lattner met Davis, who has a bachelor’s degree in chemical engineering from the University of Melbourne and a law degree from Monash University in Australia as well as studying computer science at Stanford University. Davis founded his own machine learning startup, called CrowdSend, in 2011 and did the engineering for another startup called Fluc in 2013, where he spent three years before becoming a product manager in the Google advertising business in 2016. Davis joined the Google Brain team to work on TensorFlow in 2018 and was one of the creators of the TensorFlow Lite variant, and eventually became the group product leader for machine learning at the company, leading the development of machine learning APIs, compilers, and runtimes.
In September 2019, both Lattner and Davis were the tag team distinguished engineer and product manager for TensorFlow when the Multi Level Intermediate Representation, or MLIR, compiler infrastructure for heterogenous compute engines was contributed to the non-profit LLVM Foundation for which Lattner is the benevolent dictator for life. The two left Google in January 2022 to start Modular AI.
Modularity Is The Key
The name Modular AI is important, and not the AI part except for the fact that this is a great place to start a new programming language like Mojo. There are so many different ways to get code onto so many different kinds of compute engines that it is enough to make your stomach churn, and there is a modicum of lock-in, intended (as with Nvidia’s CUDA stack) or not (as with AMD’s ROCm and Intel’s OneAPI).

“The tools used to deploy AI models today are strikingly similar to compilers and tools in the 1990s and 2000s,” wrote Lattner and Davis when Modular AI was unveiled back in April 2022. “We see severe fragmentation across these systems, with a wide variety of hardware, each having bespoke tools. The world’s biggest tech companies have built multiple in-house toolchains specific to different hardware products over the years, and these are often incompatible and share little code. How many flaky converters and translators does one industry really need?”
One should do. Ahem.
Lattner and Davis unveiled the Mojo language in May of this year,
What got us to writing about Mojo was the fact that the first software development kit, obviously for Linux, was released yesterday, with SDKs on the way for Windows and MacOS/iOS platforms coming down the pike.
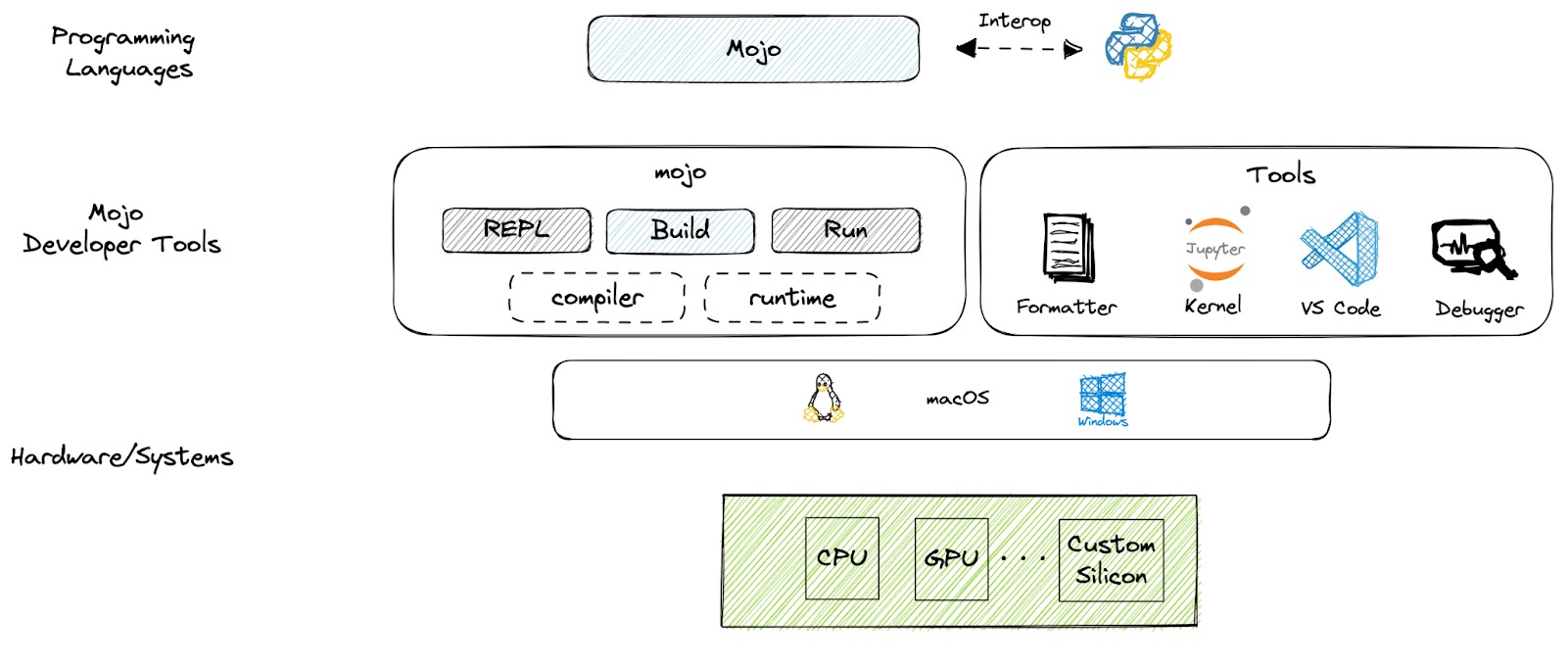
Mojo itself was unveiled in May of this year, and over 120,000 developers gave come and kicked the tires on this “new” language and over 19,000 of them are chatting away about it on Discord and GitHub. It is illustrative to hear why Lattner and Davis created Mojo directly from them, so you should read that manifesto.
One of the big changes between Python and Mojo is that Mojo is multithreaded and can run across multiple cores, and because of this, Modular AI can show a 35,000X speedup calculating Mandelbrot sets compared to the CPython runtime in Python 3. That is a much bigger performance increase than using the PyPy variant of Python that has a just-in-time compiler and it even beats the tar out of moving the code to C++, which is neat:
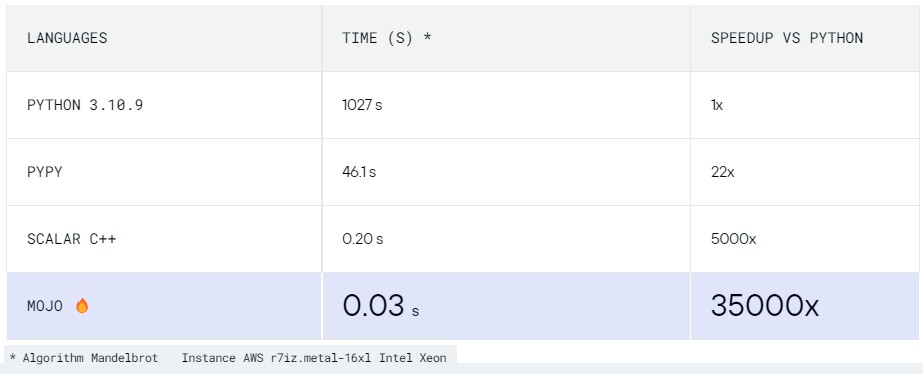
To our eyes, this just shows how interpreted languages should never be left uncompiled, given the tremendous need for compute and the flattening of the cost curves thanks to the creakiness of Moore’s Law reductions in the cost of transistors on compute engines.
To show that the Mojo pudding has some proof, Modular AI created its own Modular Inference Engine, which can take trained AI models from TensorFlow and PyTorch machine learning frameworks, the JAX numerical function transformer, the XGBoost turbocharger for gradient descent calculation acceleration and accelerate the heck out of them and then output transformed and accelerated inference models for compute engines based on Intel and AMD X86, various Arm, and various RISC-V CPUs as well as for GPUs from Nvidia, AMD, and Intel.
Here is the speedup of the Modular Inference Engine compared to TensorFlow and PyToch on various AWS instances using Intel Xeon SP, AMD Epyc, and Graviton2 instances running on Amazon Web Services:

While Modular AI is focusing its attention on the AI sector right now, there is nothing to say that Mojo can’t become a true system software programming language like C and C++ has always been and unlike Java ever was. Wouldn’t it be nice to have a unified way to program front-end and back-end applications? Something like what JavaScript and Node.js are trying to do in a more limited sense for applications that are focused mainly on I/O operations. With so many Python programmers in the world now, maybe this would be a good thing, and not just for AI. But apparently, just like what was good for GM was good for America in the glory days after World War II, maybe what is good for AI is good for IT.

Trying To Do More Real HPC In An Increasingly AI World
If you are in the traditional HPC community, it is not hard to be of two minds about the rise of AI and the mainstreaming of generative AI. At the very least, the GenAI tsunami makes it easier to argue for hardware budgets even though it is extremely difficult to …
The AI Datacenter Is Ravenous For 102.4 Tb/sec Ethernet Switch ASICs
While it has always been true that flatter networks and faster networks are possible with every speed bump on the Ethernet roadmap, the scale of networks has kept growing fast enough that the switch ASIC makers and the switch makers have been able to make it up in volume and …

Groq Says It Can Deploy 1 Million AI Inference Chips In Two Years
If you are looking for an alternative to Nvidia GPUs for AI inference – and who isn’t these days with generative AI being the hottest thing since a volcanic eruption – then you might want to give Groq a call. It is ramping up production on its Language Processing Units, …
I remember the very same reasons why Julia programming language was created…
Julia is a an entirely different language. What we have here is a drop-in replacement.
Besides Mojo, there is Cython, Codon, LPython, more? in this vein already.
And we must not forget Pypy, GraalPython, etc. which don’t have such spectacular benchmark results, but they don’t need a compilation step, which is nice for interactive work.
Being a python superset, Mojo should be easier to adopt than a whole new language like Julia.
They’re going to make their money off their Inference Engine; Mojo’s the lead into it.
Also, unlike Julia, Mojo is a full-fledged systems programming language, and if their numbers are to be believed, I’ll be an early adopter; really tired of maintaining C/C++ and CUDA code.
Indeed! But Mojo’s pudding is more of a TurboPython (Python + MLIR for heterogeneous accelerators) and so, its flavor should be less alien to the tastebuds of C-averse youths and PHBs, much unlike Julia’s brussel sprouts!
It’s interesting the SIMD-based Mojo Mandlebrot benchmark runs seven times faster than the scalar C++ code. Since AVX512 can compute eight double-precision floats at the same time, this suggests how well the newer hardware is working. From a software point of view z = z.squared_add(c) seems neither a convenient nor general function to have built in to a programming language. Even so, a fast JIT compiled language with a syntax suitable for an interactive REPL is definitely useful for experimenting with AI, statistics and numerical methods.
At the moment Julia serves this role for me. Moreover, there is already a large library of scientific algorithms available for Julia. I also prefer a more Matlab syntax over Python when performing matrix and vector calculation.
Matlab syntax (and GNU Octave) is great for implementing the main loop of the error-backpropagation training algo for a multi-layer feed-forward ANN of arbitrary size (using matrix-vector ops) — it takes just 15 lines of highly-readable code (approx.)!
Julia’s childs (at: https://discourse.julialang.org/t/julia-mojo-mandelbrot-benchmark/103638/43) are cooking up a storm of souped-up Mandelbrot recipes to compare with Mojo’s vectorized-&-parallelized dish of the same name. The OP has 7.4ms for Julia to Mojo’s 2.1ms and other’s results vary with seasonings (down to at least 0.9ms) … to be taken with pinches of salt. 8^d
I loved the intro, because as I’ve noticed before, we went somewhat similar paths. I too started with BASIC on TRS-80 in an Ohio technical college and progressed to Fortran and Cobol within a quarter.
BASIC had a lasting influence not because of the programming style, but on how much waiting I’d tolerate between writing and executing code: basically (pun intended) none and the only proper programming language which could deliver near that at the time of 0.001GHz 8-Bit CPUs was Pascal, first USCD-P but quickly Turbo-Pascal on my first and last Apple, a ][ running CP/M on a Z-80 with an 80-column card for a “professional” look much like a 3270.
For two decades I could not imagine owning a computer that didn’t have a compiler on it, it was pretty much every language Borland ever published, including a short stunt at Prolog but with Unix came a definite shift towards C with a bit of Fortran mandated by contracts.
For my thesis I used GCC 1.34 to cross-compile on SPARC SunOS machines for Motorola 680[3|4]0 and wrote Unix emulators to port X11R4 on a TMS 34020/Motorola combo with a true color visual and a message passing OS much like Mach4 or QNX, which tied into compiler generator courses I’d done at TU Berlin.
Raising kids had me go into much more pragmatic things like Lotus Notes with its wild mix of an ML class formula language and a variant of Basic, but then my career shifted mostly into operations and then technical architecture and at one point I found myself running PCs without a compiler, wondering how I’d ever express code now, beyond Excel formulas, which again I loved for their functional paradigm and fitness even in HPC, much less for the fact that they had localized keywords.
My self-esteem as officially a computer scientist still rests on the ability to write code, but I find myself rather helpless in trying to choose a (programming) language to pursue.
Java was cool, until they started putting evidently critical annotations in comments: that’s like two people talking to you at once, especially when you’re just trying to understand code from reading it. HPC annotations are even worse and for me the key to my programmer’s heart has always been code readability, or the ability to learn a language simply from reading lots of good quality code and then perhaps also the textbook… essentially the same approach that I used to learn my four human languages.
Perhaps the effort of keeping those four colloquial is also limiting my brain cycles when it comes to programming languages, so I’m definitely not aiming for more than one (is this a Dunbar’s number corollary?). Python is an obvious choice, given that my current work is building infra for ML researchers, but infra sometimes reaches into device drivers and kernel or hypervisor code as well—which seemed to suggest a bit of Rust. Don’t know if the Mojo guys can add a sprinkle of rust to their… mojo, it might not hurt stability after all.
Thanks for the pointer and the entertainment, I’ll have a look at their Mojo!
“Mojo guys can add a sprinkle of rust”
You can compile Rust code as a C like library, and use Python C Foreign Function Interface to call Rust functions.
More details on Rust side are here: https://doc.rust-lang.org/nomicon/ffi.html#calling-rust-code-from-c and for Python side here: https://cffi.readthedocs.io/en/latest/
“magnificent programming language genealogy tree from Wikipedia”
Tim, this chart was created using an open source application that was developed in the past by Ma Bell, also known as AT&T, called graphviz (https://graphviz.org/gallery/).
Neat! It looked a bit retro. But the magnificent part was the tree, or rather trees, not the graphics. Which were kinda, how shall I say, low rez?
35000x. That’s the most egregious cherry picking I have seen in decades.
Here’s a nice walk through of how they accomplish the speedup using a matrix multiply example:
https://docs.modular.com/mojo/notebooks/Matmul.html
In this example, they run base python matrix mult code as Mojo code and get a 4.5x speedup.
Then they add types, SIMD/vectorization, and then parallelization, a cache locality optimization, and finally a loop unrolling and get an over 70,000x improvement over standard Python code.
I think there’s a few takeaways here… the first is that the vanilla python code not only “just worked” but there was a > 4x speedup when using Mojo. Presumably due to the compilation. The second takeaway is if you need to really squeeze out additional performance, there are several knobs that can be turned to get some pretty extraordinary improvements over vanilla python code.
Interesting link! I like that the code (eg. with autotune) seems rather hardware-agnostic (I guess that’s provided Mojo has the needed HW-specific libraries available). The largest bit of speedup (400x) comes when they introduce static typing (eg. C-like) to replace Python’s dynamic typing (eg. LISP-like) — making Mojo that lovechild of C++ and Python as headlined in this TNP article.
Compilation by itself (with dynamic typing; maybe Cython could do it) gives 4.5x speedup, then vectorization, parallelization, and tiling, together, give a 40x speedup (total speedup = 4.5 x 400 x 40 = 70,000). I suspect though that using some sort of SciPy/NumPy/pyBLAS BLAS and LAPACK libraries with Python would also speed it up quite a bit over the generic nested-loops of matmul.
Either way, it seems that the coder still needs to know what he/she’s doing to get good performance (no free gastronomy!).
Like T. Hogberg (above), I quite liked the intro, especially the cool genealogy plot that induces a bit of nostalgia, and provides a frame for discussing PL evolutions. I would have put Haskell as descending from CAML/Ocaml functional-style, inspired by some Scheme conciseness, and Prolog declarative pattern-matchingness, with monads lurking in (disguised as either nomads, or dromedaries, to the mildly dyslexic) — but I’m no genealogist.
Feels odd to think I’ve been at this for forty years (1983+), through assembly, basic, pascal, fortran, lisp, scheme, prolog, smalltalk, c, forth, javascript, verilog, and the higher-level maple and matlab. The puzzle-solving abilities of Haskell intrigues me for a next language to approach (not just the curry!).
I also wonder if the LLVM IR, the MLIR, Webassembly, asm.js, the JVM, and other typed virtual ISAs, VMs, and bytecode interpreters, might one day converge to produce a common target for HW implementation — something like RISC-VI, RISC-VJ, or even CISC-VM++?
Indeed! The ML (Meta Language) family of languages (Standard ML, SML/NJ, CAML, Poplog, …) are formally verifiable ancestors of both Haskell and Python, mostly on holiday from the genealogy plot, except for Miranda, admirably keeping watch on the constellation (esp. the 7th planet, whose name shall not be written, because: giggles!).