

One size definitely does not fit all workloads and one budget when it comes to server processors. Which is why we have seen a proliferation of SKUs, even among the companies that are trying to keep their product lines down to a manageable number. While it is nice to keep things simple, it is also nice to chase the niches with specific SKUs, and that is what AMD is doing increasingly with its “Rome” Epyc 7002 series processors.
The second generation of Epyc processors, code-named after that Italian capital, was launched in August last year, and we did a deep dive into the architecture a week later here. The original Rome lineup had 14 variants aimed at single-socket and two-socket machines and five more that were aimed specifically at single-socket machines with special lower pricing to put the squeeze on the belly of Intel’s two-socket Xeon SP Gold market. In September last year, AMD rolled out the Epyc 7H12, a chip aimed at HPC workloads that pushed up the clock speed and the watts on the 64-core top-bin part and, we think, also cost significantly more per unit of work because HPC customers in the technical and financial industries will pay a premium for high performance if it suits their workloads. In February of this year, AMD added a new version of the 64-core and 32-core Rome chips, the Epyc 7662 and the Epyc 7532, which we detailed here. The 64-core Epyc 7662 ran a little hotter than the comparable initial Rome SKUs with the same core counts and clock speeds, and therefore AMD lowered the price a little to give better bang for the buck. The 32-core Epyc 7532 ran slower than other 32-core parts in the same 200 watt envelope with full 256 MB L3 cache, and AMD made the price/performance of the chip reflect this with a price somewhere between the biggest and smallest of the 32-core Rome parts.
Today, AMD is rolling out three more Rome variants, which have higher clocks and larger L3 caches, and therefore have relatively high wattages and which have fewer cores as a consequence. You can see the three new chips, called the Epyc 7F72, 7F52, and 7F32, in black bold italics below:
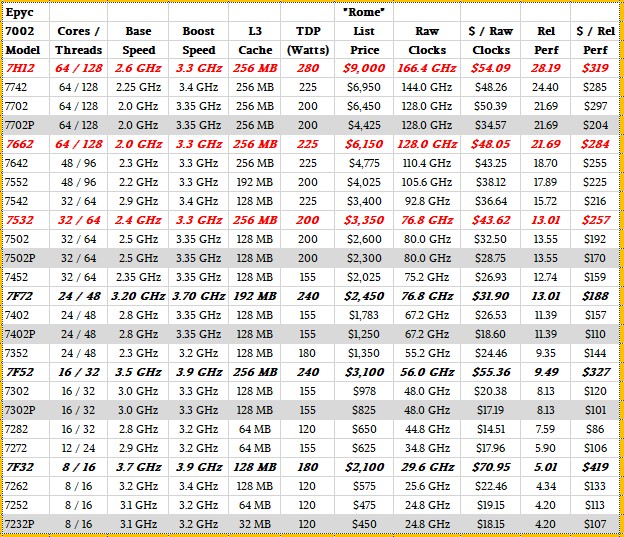
The prior additions to the Rome chips outlined above are shown in red bold italics.
The F in these three product lines is short-hand for frequency, and that means high frequency, and as such these three SKUs are aimed at workloads that need faster threads more than they need more threads. Single-threaded performance always comes at a premium, and so does the extra L3 cache that is on two of the three chips that are coming out today. Customers will not only pay with higher CPU prices, but also higher wattages, which in turn limits peripherals in the server and also has its own extra cost from the electricity and cooling bills.
Let’s take a deeper look at these three new chips.
Dan McNamara, senior vice president and general manager of the Server Business Unit at AMD, did his first rollout in his new job, having recently joined from rival Intel, where he was senior vice president and general manager of the Network and Custom Logic Group within the Data Center Group at the chip giant. Before joining Intel, McNamara held various leadership positions at FPGA maker Altera, which Intel acquired for $16.7 billion in June 2015.

Almost by definition, the Rome Epyc product line that we see is the one aimed at OEMs, who buy raw server parts like CPUs and in turn sell machinery to large enterprises, government and academic institutions, and various service provides and telecommunications companies that do not attain the very high scale of one of the hyperscalers or large public cloud builders. These latter two groups – and companies such as Google, Microsoft, Amazon Web Services, Alibaba, and Tencent really belong to both camps – design their own machines with the help of and have them manufactured by their ODM partners and they can get custom SKUs and custom pricing from any server chip maker. They are, in effect, an OEM with only a handful of very large customers, and these customers can call their own tune within the limits of a CPU design and the volume economics of chip manufacturing.
The deluge of data and the desire to make use of it better is top of mind with enterprises these days, and there is the normal upgrade cycle for Microsoft’s Windows Server and VMware’s vSphere server virtualization stacks that is driving new system sales, too. Linux, in one form or another, underpins most modern HPC, AI, and data analytics workloads and is a default for at least half of the servers that go into the enterprise. (That last observation is ours, not McNamara’s.)
There are three key workloads that these new Rome Epyc processors are aimed at, according to McNamara. The first is commercial HPC applications, but ones where the customers who buy clusters to run traditional HPC or machine learning/data analytics workloads could not or will not pay the Cadillac premium of the Epyc 7H12 processor launched last year. While that was a very high performance chip, that performance came at a price, and it is far cheaper to buy two 32 core parts at the same clock speed or a pair of faster 24-core parts than to buy one Epyc 7H12. (There are customers who need absolute peak performance per unit of server chassis, and they will happily pay that premium. And they do.) Here is how McNamara stacked up the new Epyc chips against their “Cascade Lake” alternatives in the traditional HPC space:

The other workload these new F series Rome Epyc chips are aimed at is hyperconverged infrastructure, where virtual compute and virtual SAN storage reside on the same server virtualization substrate. VMware’s vSAN is the dominant one in the enterprise today, with HCI pioneer Nutanix getting the lion’s share of the other (and nearly equal) portion of the market. The HCI space has really come down to a two horse race with some interesting challengers. AMD worked hard to get VMware’s vSAN software ported and tuned for the first generation “Naples” Epyc chips and even got AMD to shift to per-socket rather than per core pricing for vSAN, which was to the advantage of AMD over Intel. (But it didn’t hold, and VMware shift back to a kind of quasi per-socket price based on 32-core chunks of capacity in February of this year.) In the third quarter, Hewlett Packard Enterprise will certify the Nutanix HCI stack to run on the ProLiant DX series of Epyc servers, and that will begin leveling the playing field between vSAN and Nutanix when it comes to HCI. Dell and other server OEMs will very likely follow HPE’s move with support for Nutanix on their own Epyc systems. Having more cores generally allows an Epyc server to host more VMs per node than does a Xeon XP server for a given core count and performance level.
And finally, these SKUs are aimed at traditional relational database management systems and the online transaction processing workloads that they typically run. While relational databases can easily scale out their transaction processing across many threads, there are still many batch-style operations that need to be done where having faster threads is better than having more but slower threads. The 24-core and 16-core parts let customers split the difference and get CPUs with fat L3 caches, which also help database performance.
Here is how McNamara positioned the database advantage using Microsoft’s SQL Server 2017 as the example:

It is a bit weird to use one set of processors fore the transaction per minute measure and another set of processors for the bang for the buck comparison on OLTP workloads. We would love to see a system-level benchmark on a wide array of OLTP workloads that shows the price/performance differences of fully configured systems. The CPU definitely helps, but other elements of the system might overwhelm that, such as the cost of the memory and flash (if the latter is used). It all comes down cases and real testing.
Here is how AMD is stacking up the three new chips against their predecessors in the Rome Epyc line and in the most equivalent “Cascade Lake” or “Cascade Lake-R” Xeon SP processors from Intel:

The Cascade Lake CPUs debuted in April 2019, and the Cascade Lake-R rejiggering was a reaction to the Rome Epycs that saw Intel add more cores and cache and clocks to better compete with AMD. (But still not close the performance or price/performance gap.)
AMD is once again flipping ratios on the data (as it did with the prior updates to the Rome Epyc chips), showing relative performance per dollar instead of relative cost per unit of performance. Yes, after decades of thinking about it one way, this really hurts and it is weird. But what is obvious is that at least in the comparisons that AMD thinks are representative, it can show a performance advantage against Intel’s latest Xeon SP chips in the belly of the enterprise market where customers do in fact buy middle bin parts in the Gold series. (AMD is estimating its SPECrate2017 integer performance, and we all know how that drives people crazy with the estimates. There is no reason to not get real benchmarks from real servers ahead of launch, and both Intel and AMD fail to do this and leave us with estimates that are not audited.)
One of the things that AMD is also stressing with this launch is that the Rome Epyc architecture is more balanced than the Cascade Lake and Cascade Lake-R Xeon SP processors from Intel when you look at more than the cores but also the memory capacity, memory speed, memory bandwidth, and L3 cache per core. Again, here are the estimated performance figures for the Epyc 7F52 against the Xeon SP-6242 Gold and the Xeon SP-6242R Gold processors:

There are two other things to note. First, IBM is the first public cloud to get the new 24-core Epyc 7F72 chip into instances on the public cloud, and Big Blue plans to have them available on the IBM Cloud in two-socket configurations spanning a maximum of 48 cores in an instance sometime in the second quarter. AMD is also happy that Supermicro is bringing the first blade server to market – in the SuperBlade family – in the second quarter as well. AMD expects to have over 140 different physical server platforms available from OEMs and over 150 unique instance types available on public clouds by the end of the year. This is a pretty good ramp, all things considered.


GPU Engines Are So Strategic China Will Have To Use Its Own
China is the world’s second largest economy, it has the world’s largest population, and it is only a matter of time before has a world-class technology ecosystem spanning the smallest transistors to the largest hyperscale and HPC systems. It simply has enough money, and enough time, and enough smart people, …
HPC In 2020: Compute Engine Diversity Gets Real
The choice of processors available for high performance computing has been on growing for a number of years. There are no less than three major types of CPUs available for HPC duty, including X86, Arm, and Power architectures with more than a half dozen credible suppliers in total, along with …

Great Accelerations: Just How Much Will We Spend On GenAI Again?
Ever since the launch of the “Antares” MI300X and MI300A compute engines by AMD back in early December, we have been mulling over the spending forecasts for AI spending in general and for infrastructure and accelerators more specifically. With the generative AI marketing rocketing upwards on what looks like escape …
I’d like for AMD to take a crack at the 1P graphics workstation market with these and the higher clocks help, L3 cache size is nice as well. And before anyone goes with Threadripper(TR) that TR/MB platform does have some ECC(limited) memory support but does not have support for RDIMMs or memory capacities above 256GB, and only 4 memory channels on TR and less PCIe 4.0 lanes as well compared to the Epyc/Rome and the SP3 MB platform.
Epyc/Rome is the real professional branding and feature sets so why the lack of AMD in the Graphics Workstation market. That and still not much in the Mini Desktop and all in one Desktop markets as well for AMD’s Ryzen. AMD’s doing fine in the home system PC Builder market and looks to be taking on Intel fine for mainstream laptops with its 4000(Zen-2) series APUs, and Zen-3 for the desktop 4000 series parts are coming in September 2020 most likely.
Something is up with the OEM All In One Desktop and Mini Desktop markets, including those mini desktop bare bones offerings where AMD is 3 generations into Ryzen and not much market penetration to show on those OEM market offerings.