

For very sound technical and economic reasons, processors of all kinds have been overprovisioned on compute and underprovisioned on memory bandwidth – and sometimes memory capacity depending on the device and depending on the workload – for decades.
Web infrastructure workloads and some relatively simple analytics and database workloads can do fine on modern CPUs with a dozen or so DDR memory channels, but for HPC simulation and modeling and AI training and inference, even the most advanced GPUs are literally starving for memory bandwidth and memory capacity to actually drive up the utilization on the vector and matrix engines that are already there on the silicon. These GPUs spend a lot of time waiting for data, scratching themselves.
So the answer is obvious: Put more memory on these chips! But, alas, the HBM memory on advanced compute engines costs more than the chips themselves, so there has been a lot of resistance to adding more. Particularly when adding more memory can double the performance and now you need half as many devices to get the memory footprint for a given HPC or AI application to run at a desired level. Double the memory, halve the revenue is not a playbook to get a bonus from the boardroom. Unless, of course, your market demand is 3X or 4X the supply you can field and you have competition that is going to beat you to that punch.
Eventually, sense prevails, which is why Intel added a variant of the “Sapphire Rapids” Xeon SP chips with 64 GB of HBM2e memory, with only a little more than 1 GB per core but with just over 1 TB/sec of aggregate memory bandwidth. For workloads that can fit into that relatively tiny memory footprint and that are more bandwidth starved than capacity starved – which describes plenty of HPC applications –just switching to HBM2e can increase the performance by 1.8X to 1.9X. Which made the HBM variant of Sapphire Rapids one of the more interesting – and useful – parts of the product launch back in January and which hopefully will mean that Intel does HBM variants of future “Granite Rapids” chips even though it is enamored with the Multiplexer Combined Ranks (MCR) DDR5 memory it helped create and that is definitely part of the Granite Rapids architecture.
With the new “Hopper” H200 GPU accelerator announced by Nvidia at the SC23 supercomputing conference in Denver this week, and with AMD getting set to launch its “Antares” family of GPU accelerators for the datacenter on December 6 – with the Instinct MI300X sporting 192 GB of HBM3 capacity and the hybrid CPU-GPU MI300A having 128 GB of HBM3 memory – it was obvious that Nvidia had to do something, and at the very least needed to add more memory to the Hopper GPU.
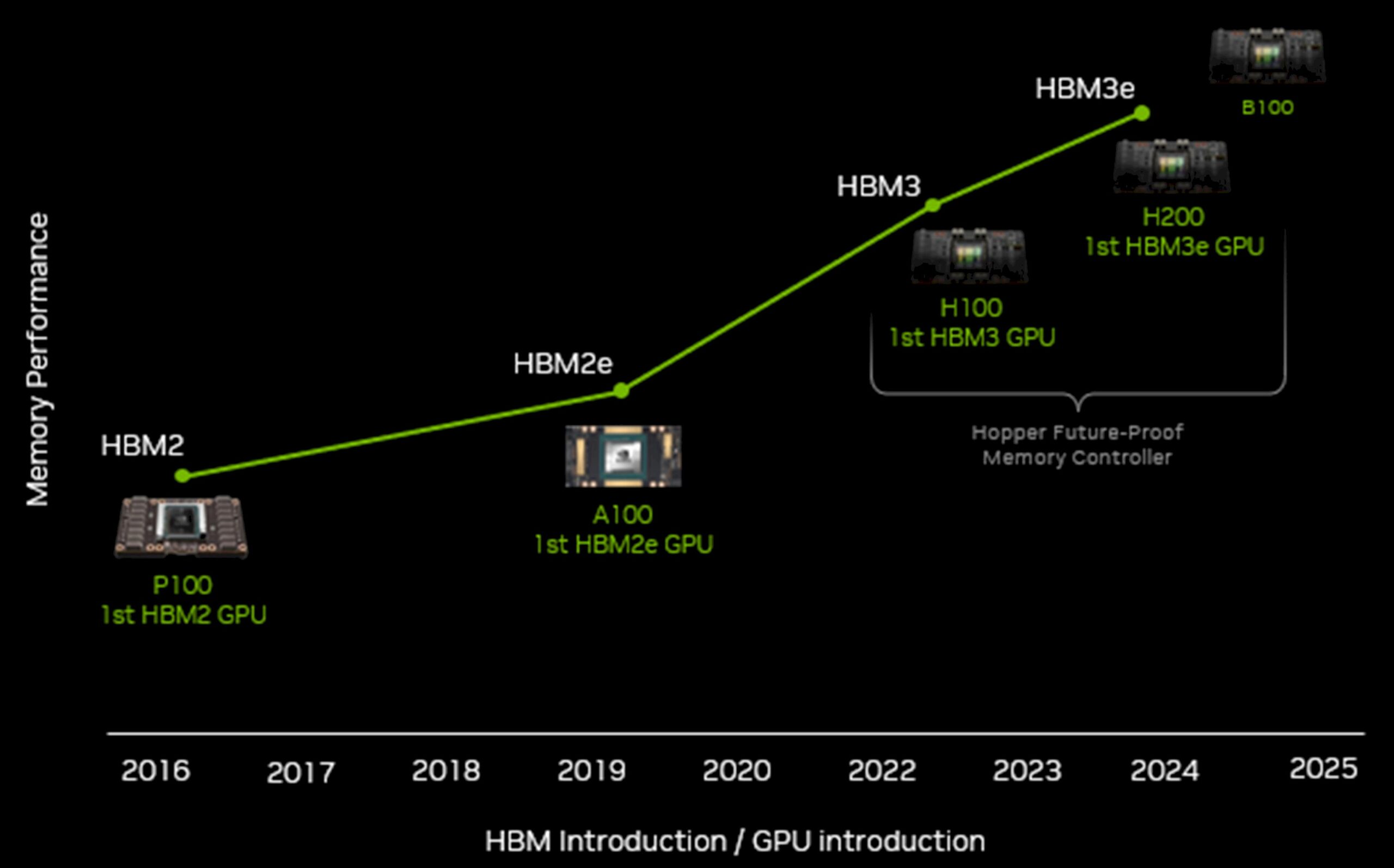
When Nvidia dropped a roadmap Easter egg into a financial presentation a month ago, we all knew that the GH200 GPU and the H200 GPU accelerator were going to be launched as a stop-gap before the launch of the “Blackwell” GB100 GPU and B100 GPU accelerator expected sometime next year. Everyone figured the H200 package would have more memory, but we thought Nvidia should take the time to boost the performance of the GPU motor itself. As it turns out, by adding more HBM memory and by moving to faster HBM3e memory at that, Nvidia can get exactly the same kind of performance boost on the existing Hopper GPU design without having to add more CUDA cores or overclock the GPU.
Which just goes to show us all that none of these compute engines have anything close to a balanced design. A cynic would say all the compute engine makers know this and are playing us. Someone with a kinder disposition would say they are all doing the best they can given the high cost of HBM. Consider us somewhere in the middle. At the prices that Nvidia is charging for GPUs, it should have hundreds of gigabytes of the fastest damned memory that can be had. Period. And while we are at it, all accelerators should have 3D V-Cache and HBM and DDR memory. Full stop.
Anyone who has shelled out big bucks for a Hopper H100 accelerator in the past year is going to have some pretty serious buyer’s remorse starting today. Unless, of course, Nvidia charges one and a half to twice as much for the Hopper with the fattish 141 GB HBM3e memory as it does for ones with 80 GB or 96 GB of somewhat skinnyish HBM3 memory. To make the numbers work out, Nvidia almost has to do that to keep customers from getting testy.

The H200 is only available in the SXM5 socket thus far, as far as we can tell, and has the same exact peak performance stats for vector and matrix math as the Hopper H100 accelerator that was announced in March 2022 and that started shipping time last year and was ramping fully earlier this year. The difference is that the H100 had 80 GB and then 96 GB of HBM3 memory delivering 3.35 TB/sec and 3.9 TB/sec of bandwidth, respectively, out of the initial devices, while the H200 has 141 GB of faster HBM3e memory that has 4.8 TB/sec of aggregate bandwidth. That is a 1.76X increase in memory capacity over the Hopper baseline and a 1.43X increase in memory bandwidth over the Hopper baseline – all within the same 700 watt power envelope. AMD’s Antares MI300X will deliver 5.2 TB/sec of bandwidth against 192 GB of HBM3 capacity, and quite possibly more peak floating point power but possibly just more effective floating point power.
The throttling of performance because of the high cost of integrating HBM memory onto compute engines is alarming here at the end of Moore’s Law, and Nvidia gave us some numbers so we can see it just like Intel did with the Sapphire Rapids Xeon Max CPU.
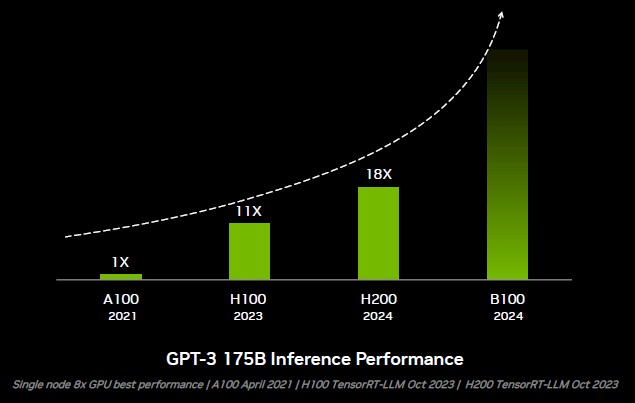
Whatever is happening with the future Blackwell B100 GPU accelerator, it looks to our eye like we can expect a lot more inference performance, and we strongly suspect this will be a breakthrough in memory, not compute, as the chart below suggests that was meant to illustrate the performance jump on GPT-3 175 billion parameter inference oomph:
So, all of you who buy Nvidia Hopper G200’s from here into maybe next summer, you will get some buyer’s remorse, too. (This is the nature of the ever-evolving datacenter.)
Thanks to the Transformer Engine, a drop in floating point precision, and faster HBM3 memory, the original H100 that started ramping fully this year had 11X the performance running inference against the GPT-3 175B model. With the H200’s fatter and faster HBM3e memory – and no changes to other hardware and no changes to the code – that performance compared to the A100 running inference went up to 18X. That is a 1.64X increase in performance from H100 to H200, all driven by memory capacity and bandwidth.
Imagine what might happen if the device had 512 GB of HBM memory and maybe 10 TB/sec of bandwidth? What would you pay for a fully utilizable GPU? It might actually be worth $60,000 or even $90,000 a pop, given what we are all apparently willing to pay – call it $30,000, more or less – for one that runs significantly less computationally efficiently than it is capable of.
Remember: We are not singling out Nvidia here, any more than we did Intel last year or AMD for not putting HBM memory on its “Genoa” Epyc CPUs, as we have said it should have done for at least some of the SKUs. For most HPC and AI workloads, memory capacity and memory bandwidth – or both – are the bottlenecks to realizing real-world performance, to ascending those peaks of floating point oomph. Compute engine makers keep throwing more cores at a problem that needs a reworking of the memory hierarchy, or at the very least a hell of a lot more and faster memory. Customers will pay for it with the kinds of results that Intel and now Nvidia are showing.
Here’s a thought: Maybe the HBM memory makers should do more to get the cost down on stacked memory and advance the HBM roadmap a bit more quickly seeing as though this is a very big problem that is costing the industry huge amounts of money and resulting in massive inefficiencies. Maybe compute engine makers should align tightly to that very aggressive HBM roadmap and not to some other factor like annual launches in the spring or the availability of some chip manufacturing process. We need more aggression and more co-design here. Put another way: H100 should have always had what is being called HBM3e. Because clearly that is the only way to get its true value of the device.
Here is a broader set of AI inference workloads, showing the relative performance of the H100 to the H200:
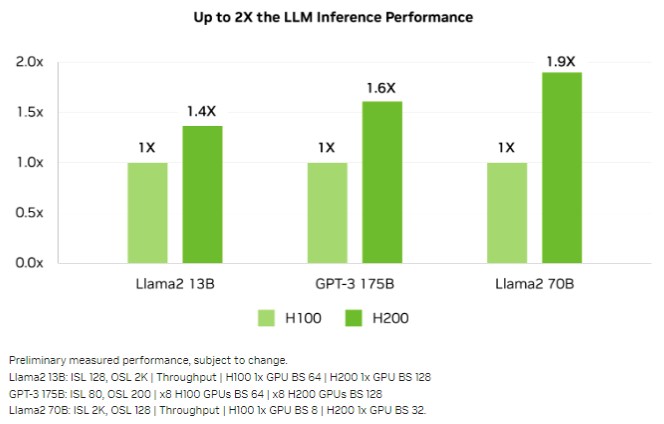
The performance increase from that extra and faster memory depends on the workload, and will be lumpy. As you can see, the smaller LLaMA2 13B model does not see the same kind of boost as the LLaMA2 70B model, which has 5.4X as many parameters to juggle as it tries to statistically guesstimate the next token to barf out as it pours a prompt through its parameters.
Obviously, of you can do twice as much inferring in the same power envelope, you can cut energy consumption and the total cost of ownership by 50 percent, which seems to imply that Nvidia is not going to charge a premium for H200 GPUs.
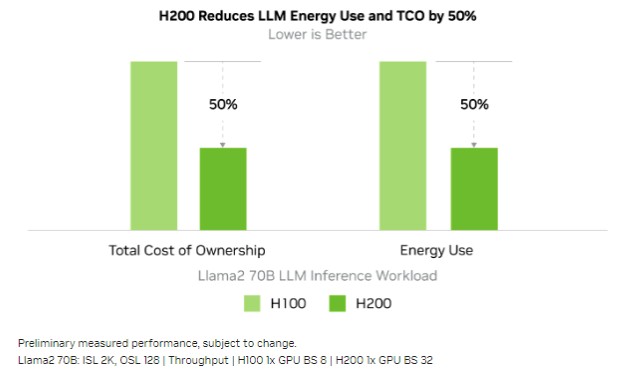
So hooray! GPUs all around! This is chart above is documentation you can take to a sales call, people. And if Nvidia really is not going to charge much of a premium for the H200 compared to the H100, that is the right thing to do for a lot of reasons.
For the HPC crowd, the comparison of X86 CPUs to GPUs is old news, but on the left hand side of the chart below we see a pair of Sapphire Rapids Xeon SP-8480s compared to a quad of H200 GPUs running the MILC Lattice quantum chromodynamics application. That performance increase per device is really only 55X, since there are twice as many GPUs as CPUs.
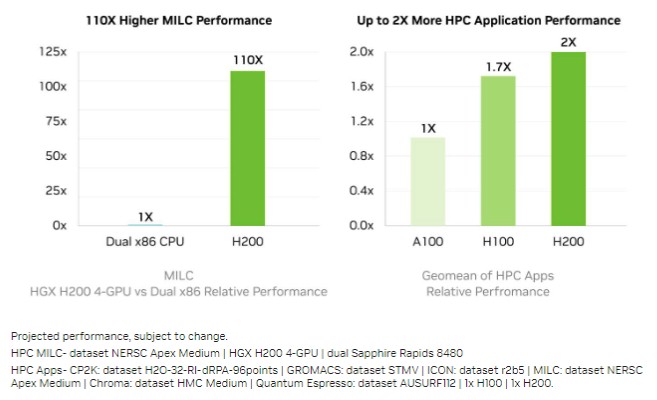
On the right side of that chart above is the performance of the A100, the H100, and the H200 on a mix of six different HPC workloads, and as you can see, the extra memory and extra bandwidth does help, but not as much as with the AI inference workloads shown above. The relative performance boost from H100 to H200 on these six workloads – CP2K, GROMACS, ICON, MILC, Chroma, and Quantum Espresso – works out to only an 18 percent increase. Which is not only disappointing but which is also an explanation as to why GPU compute engine makers were not rushing to add so much HBM in the first place.
We strongly suspect that HPC application developers know how to work in smaller memory footprints for a given amount of compute and have workloads and middleware – like the very excellent MPI protocol – that are designed to make the most of very little. AI workloads have massive elephant flows on their networks, and they are inherently spending a lot of time waiting for one set of GPUs to catch up to the others to synchronize processing and data exchange.
But this is also true: If you gave HPC shops more HBM memory and a lot more bandwidth, we are certain the HPC crowd would tune for that and push performance just as hard as the AI crowd, driven by the hyperscalers and a bazillion startups – OK, 15,000 but it is a big number – is doing. The HPC community is also comprised of some of the smartest people on Earth, ya know.
Last thing: The H200 GPU accelerator and the Grace-Hopper superchips that will be made from this updated Hopper GPU with fatter and faster memory will not be available until the middle of next year. Which is exactly what our revised Nvidia roadmap said and which is also why we don’t think the Blackwell B100 accelerators will ship until late 2024 even if they are the star of the GTC 2024 conference next March. No matter which one you might want for your system, you better put your orders in now or you ain’t gonna get any.




Great write up as usual TPM, keep ’em honest!
“H100 should have always had what is being called HBM3e. Because clearly that is the only way to get its true value of the device.”
Having spent a bit of time in GPU land back in the day when they were primarily display controllers, part of the problem here is the balancing act between Memory suppliers and GPU vendors. There is this tightrope walk of how much boutique memory performance can you get and how much do you want, but in order to get it you’re going to have to commit to it upfront, betting on the come. Each side holds back a little and those little compromises add up. It was the same crap 25 years ago when there literally was VRAM, Video Ram, that could be dialed up and optimized a little tighter and a little tighter but it was going to cost you. Everyone is financially engineering their businesses, and so yes, it feels like the sweet spot solution is being held back. Micron, Hynix, Samsung are all just doing what memory guys have always done. If HBM had the same volumes as main memory you would see a vastly different landscape.
So, I want HBM memory in my phone and PC! Let’s solve this problem!
It’ll be interesting to see how these H100 (and H200, GH200, B100 …) systems perform on HPCG, which demands a bit more concentration in the execution of memory-access kung-fu (beyond bandwidth and capacity). Today’s (Nov. 13) Top500 for example, has HPCG #10 AOBA-S NEC Type-30A Vector Engines doing 1.1 PF/s at 1.4 MW, or 0.8 PF/MJ, while Frontier (MI250x, #2) does 0.6 PF/MJ, Fugaku (A64FX, #1) is at 0.5 PF/MJ, Leonardo (A100, #4) gives 0.4 PF/MJ, and #11 Crossroads (Xeon 9480) pushes 0.2 PF/MJ. If Hoppers and/or their updates push past NEC Vector Motors on HPCG then that’ll be quite something to write home about I think!