
There are a lot of things that compute engine makers have to do if they want to compete in the datacenter, but perhaps the most important thing is to be consistent. The devices they make have to consistently push the technological envelope, and that have to be delivered in volume to the market when promised and at regular intervals.
With the new H100 line of GPU accelerators, based on the “Hopper” GH100 datacenter GPU, Nvidia is once again pushing the architectural envelope, and we presume that it has the capacity from foundry partner Taiwan Semiconductor Manufacturing Corp when the Hopper accelerators start shipping in the third quarter of 2022. The cadence is more or less at two years between datacenter GPUs, and that is what the market will accept for such complex devices. (When it comes to CPUs, the hyperscalers and cloud builders want an annual cadence, which is somewhat rougher to accomplish.)
Given the tightness of semiconductor manufacturing due to supply chain issues and the huge demand for GPU compute from the AI crowd, we suspect that there will be more demand than supply, and that means a very aggressive pricing situation that will benefit Nvidia.
We suspect also that Nvidia will be selling its existing “Ampere” A100 GPU accelerators for quite some time – witness the fact that Meta Platform’s Research SuperComputer, which is being built in phases between now and the fall mostly to support Facebook AI applications, is based on existing DGX A100 systems that employ Ampere A100 accelerators. That would be 2,000 DGX A100s with a total of 4,000 AMD Eypc 7003 CPUs and 16,000 GA100 GPUs. You can surely bet that Facebook would like to have Hopper GPUs instead, even if Nvidia does not support the Open Compute Open Accelerator Module interface and form factor alternative to Nvidia’s SXM interface and form factor. Presumably those companies that have a tight partnership with Nvidia – meaning those hyperscalers that also have cloud capacity for sale to the corporations of the world, with Amazon, Google, and Microsoft dominating but Alibaba, Baidu, and Tencent also being important – are going to be at the front of the line for the new Hopper GPUs.

We will be doing a deep dive on the architecture and economics of the Hopper GPU accelerators as more information becomes available, but here is what we can tell you now. The Hopper GPU has over 80 billion transistors and is implemented in a custom 4N 4 nanometer chip making process from TSMC, which a pretty significant shrink from the N7 7 nanometer processes used in the Ampere GA100 GPUs. That process shrink is being used to boost the number of streaming multiprocessors on the unit, which adds floating point and integer capacity. According to Paresh Kharya, senior director of accelerated computing at Nvidia, the devices also have a new FP8 eight-bit floating point format that can be used for machine learning training, radically improving the size and throughput of neural network that can be created. There is also a new Tensor Core unit that has the capability of dynamically changing its bit-ness for different parts of what are called transformer models to boost their performance in particular.
“The challenge always with mixed precision is to intelligently manage the precision for performance while maintaining the accuracy,” explains Kharya. “Transformer Engine does precisely this with custom, Nvidia-tuned heuristics to dynamically choose between the 8-bit and 16-bit calculations and automatically handle the recasting and scaling that is required between the 16-bit and 8-bit calculations in each layer to deliver dramatic speed ups without the loss of accuracy. With Transformer Engine training of transformer models can be reduced from weeks down to days.”
These new fourth-generation Tensor Cores, therefore, are highly tuned to the BERT language translation model and the Megatron Turing conversational AI model, which are in turn used in applications such as SuperGLUE Leaderboard for language interpretation, Alphafold2 for protein structure prediction, Segformer for semantic segmentation, OpenAI CLIP for creating images from natural language and visa versa, Google ViT for computer vision, and Decision Transformer for reinforcement learning.
The combination of this Transformer Engine inside the Tensor Cores as well as the use of FP8 data formats (in conjunction with FP16 and TF32 formats still needed for AI training, as well as the occasional FP64 for that matter), the performance of these transformer models has increased by a factor of 6X over what the Ampere A100 can do.
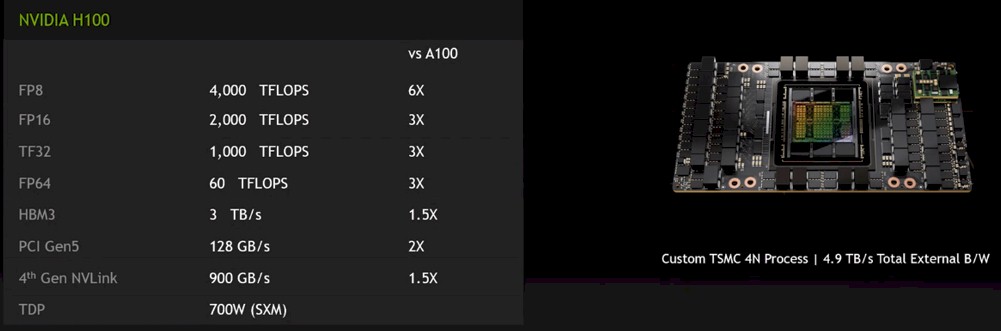
The new H100 accelerator is being tricked out with several new technologies and some expanded ones to create a more powerful system for doing AI training. Hopper is the first compute engine to come to market that will deploy HBM3 memory, driving up to 3 TB/sec of memory bandwidth. The Hopper GPUs will also support host links using PCI-Express 5.0 as well as the 7X faster NVLink 4.0 interfaces that are used to link the GPUs to each other using memory atomics in a shared memory format akin to the NUMA links used in big iron NUMA servers based on CPUs.
And, next year with the “Grace” Arm server CPU that Nvidia is developing and will deliver in the first half of 2023, the Grace and Hopper GPUs will be linked to each other over NVLink 4.0 ports, tightly coupled and sharing memory coherently, and there will even be a Grace-Grace “superchip” that has a total of 144 cores and 1 TB of memory but will, according to Kharya, burn only 500 watts including those banks of low-powered DDR5 memory and yet deliver 1 TB/sec of memory bandwidth across those CPUs – twice that of a standard X86 CPU today.
Nvidia is also creating a switch fabric that breaks outside of the DGX server chassis, a leaf/spine memory area network that can be used to link up to 32 DGX H100 servers with a total of 256 GH100 GPUs into a single pod, and Quantum-2 InfiniBand switch fabrics that allow for many pods to be linked together into a parallel cluster that delivers massive scalability.

Nvidia will be building a follow-on to its existing “Selene” supercomputer based on all of this technology, to be called “Eos” and expected to be delivered in the next few months, according to Jensen Huang, Nvidia’s co-founder and chief executive officer. This machine will weigh in at 275 petaflops at FP64 precision and 18 exaflops at FP8 precision, presumably with sparsity support doubling the raw metrics for both of these precisions.
Because many servers today do not have PCI-Express 5.0 slots available, Nvidia has cooked up a variant of the PCI-Express 5.0 Hopper CNX card that includes the Hopper GPU and a ConnectX-7 adapter card that plugs into a PCI-Express port but lets the GPUs talk to each other over 400 Gb/sec InfiniBand or 400 Gb/sec Ethernet networks using GPUDirect drivers over RDMA and RoCE. This is smart. And in fact, it is a GPU SmartNIC.
We will be covering all of these technologies in much more detail, so stay tuned.

A Tale Of Two Nvidia Eos Supercomputers
Note: This story augments and corrects information that originally appeared in Half Eos’d: Even Nvidia Can’t Get Enough H100s For Its Supercomputers, which was published on February 15. So, as it turns out, there are two supercomputers named Eos, and even the people in the press relations department at Nvidia, …
Opening Up The Future “Venado” Grace-Hopper Supercomputer At Los Alamos
There are many interpretations of the word venado, which means deer or stag in Spanish, and this week it gets another one: A supercomputer based on future Nvidia CPU and GPU compute engines, and quite possibly if Los Alamos National Laboratory can convince Hewlett Packard Enterprise to support InfiniBand interconnects …

VMware Embraces Nvidia GPUs, DPUs To Drive Enterprise AI
AI is too hard for most enterprises to adopt, just like HPC was and continues to be. The search for “easy AI” – solutions that will reduce the costs and complexities associated with AI and fuel wider use by mainstream organizations – has included the development of myriad open source …
“We suspect also that Nvidia will be selling its existing “Ampere” A100 GPU accelerators for quite some time”.
Continuing fabrication of prior generation GPU and CPU architectures now appears the mass market production trend relying on the depreciating understood design process. Makes best of a ‘stacking’ device manufacturing environment into the physical brick wall searching for runway in an accelerating space escalating in cost. Back generation introduces incremental subsystem and compliment component options to deliver new rungs of utility and price performance; superior bus, interconnect and memory options for example, that stratify a mix of established product rungs under every next core processing generation. Builds a cross generation opposed to purely a by generation product stack. Advantage goes to the system developer over component developer releasing value propositions from a combination of cross generation options on system application need fit to use. Extends the useful life of components across process generations albeit stratifies core suppliers but for the system community breath’s useful life into product cycles extending range for development, sales and reinvestment.
Mike Bruzzone, Camp Marketing