

No matter what, and without any excuses about Moore’s Law slowing down, those buying compute, storage, and networking expect at least one thing in any generational leap in a device: That the cost per unit of capacity goes down. And for the hyperscalers who run massive applications, they look at the cost per unit of performance per watt and they need it to go down.
Period. Full stop.
And when either doesn’t happen, it is either through monopolistic greed or technological barriers (sometimes self-inflicted). Or, sometimes these happen at the same time when the supply of alternatives to any given chip is limited. Competition makes it far more likely that it will happen. Even if you buy Intel CPUs, send AMD some roses or Belgian chocolates.
It is with this in mind that we contemplate the relative performance and pricing across the Xeon and Xeon SP server CPU lines from Intel from the “Nehalem” Xeon E5500 processors launched in 2009 to the just-launched “Sapphire Rapids” fourth-generation Xeon SPs.
The Nehalem Xeons were significant in that they adopted many of the chip design and features promoted by AMD in its Opteron line of server processors, which rose to ascendancy when Intel was of two minds about CPU compute in the datacenter. It wanted to keep the Xeons at 32-bit and moved 64-bit memory and processing workloads to the Itanium architecture. The market did not want this, and so AMD created the Opteron line and in a very short few years ate a more than a quarter of the server market within three years. The Nehalems coincided with AMD making bad design choices with the Opterons and with the beginning of the Great Recession, and the server market shifted quickly back to Intel.
A frustrated and demoralized AMD eventually left the server battlefield, but regrouped five years later to rebuild trust with the market with its Epyc designs. Fortunately for AMD, it was taking on server compute again just as Intel was having great difficulties with its 10 nanometer and then 7 nanometer manufacturing processes, which made a mess of Intel’s server roadmaps and gave AMD yet another opportunity to take about a quarter of the server market – albeit over a considerably longer six years because of perfectly understandable trust issues with AMD.
The market is over those trust issues at this point, or perhaps more accurately both AMD and Intel have caused enough heartburn with server buyers over the past two decades that they know they need to have two suppliers of X86 engines because when there is only one, all of the bargaining power is on the vendor side of the table.
To fully understand where the new Sapphire Rapids Xeons are at, we need to first measure Xeons and Xeon SPs against each other and within the technical and economic constraints that Intel is operating within. As we are fond of pointing out, even if Intel did not ship a single Sapphire Rapids chip this year, AMD can only have its foundry and packaging partners make so many chips each year. That number is growing, but AMD, like just about every other chip maker, is limited by the supply of chip packaging substrates. These substrates are the portions of the chip package that take the tiny wires of the literal chips in the package and amplify the bump pitches so they can link out to the socket or motherboard. AMD can make more Epyc chiplet components than it can turn into Epyc packages thanks to substrate shortages. But as AMD’s top brass told us recently, this is changing for the better.
As we said during our initial take on the Sapphire Rapids processors and their SKU stack last week, Intel has a certain share of the X86 server market as design wins thanks to the architecture update with the fourth generation Xeon SPs – particularly with network, edge, storage, HPC, and big memory NUMA workloads – but a much larger share comes from supply wins – meaning Intel can ship an X86 chip with a certain raw performance after AMD sells out. Depending on the customer and Intel’s list prices for Sapphire Rapids CPUs, Intel might have to discount a bit. Or not. Neither AMD nor Intel want to try too hard to compete with homegrown Arm processors from Amazon Web Services and Alibaba or the Ampere Computing Altra and Altra Max Arm server CPU lines used by other hyperscalers and cloud builders. We think that both will be perfectly happy to have the X86 architecture command a premium, and given the vast base of Windows Server applications that, for the most part, can only run on X86 iron and other code (even running on Linux) that is tuned for X86 and that would be a hassle to tune for Arm.
The point is: Intel knows it will have a very large share of supply wins and it knows it will have to discount like crazy to have supply wins at the hyperscalers and cloud builders. And frankly, a lot of those discounts already happened in Intel’s Q3 2022, which we reported on back in October, and its Q4 2022, which we do not know how bad it will be as yet. We don’t expect much in the way of operating income for Intel’s datacenter business when it reports Q4 2022 on January 26 for this very reason.
How The Sapphire Rapids CPUs Stack Up To Ice Lake Xeon SPs
The official Xeon and Xeon SP product lines – meaning not including custom parts sold to HPC centers, hyperscalers, cloud builders, and sometimes OEMs – have been getting more complex over the past fourteen years. And because of this, it gets harder and harder to make comparisons over a long period of time.
Intel keeps it simple and always compares the new generation with the previous one. (We will be a bit more historical than this for obvious reasons.) Here is how Intel reckons the performance of the Sapphire Rapids Xeon SPs against their predecessor Ice Lakes, using a top bin part comparison:
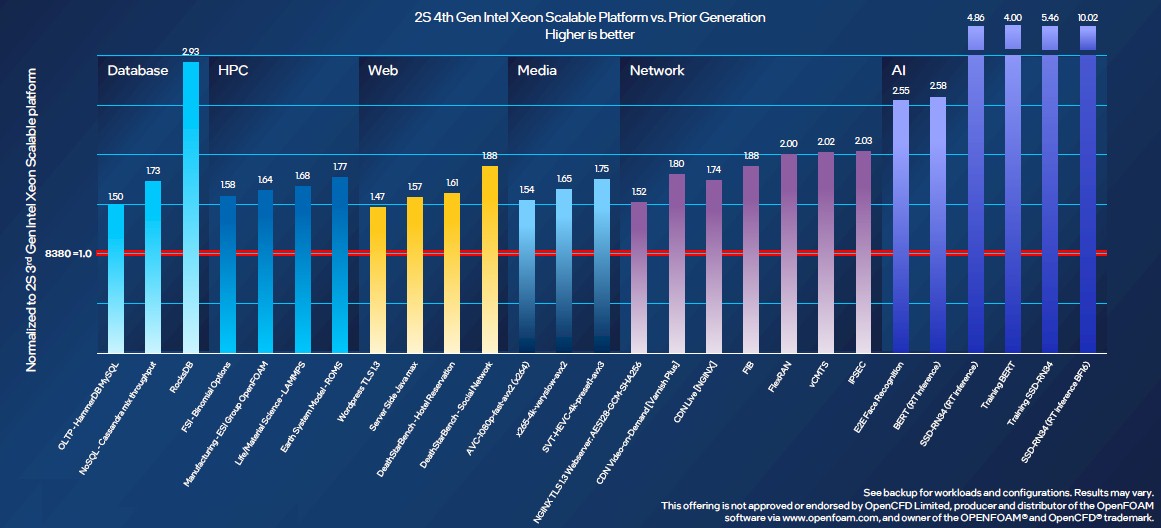
The AI inference performance, thanks to those shiny new AMX matrix math units in the “Golden Cove” cores using in the Sapphire Rapids chips, are showing very large performance gains. But across a wide variety of workloads, a two-socket server based on a pair of 60-core Sapphire Rapids Xeon SP-8490H Platinum running at 1.9 GHz will deliver somewhere between 1.5X and 2X more performance over a two-socket machine based on the 40-core Ice Lake Xeon SP-8380 Platinum running at 2.3 GHz. There is 15 percent more IPC, and the rest is driven by core counts, larger and faster memory, and sometimes on-package accelerators.
During its in-depth pre-briefings, Intel offered performance comparisons with set service level agreements (SLAs) on different kinds of workloads and then calculated the relative performance increase on two-socket machines using the same top bin parts in the Sapphire Rapids and Ice Lake generations. Check it out:
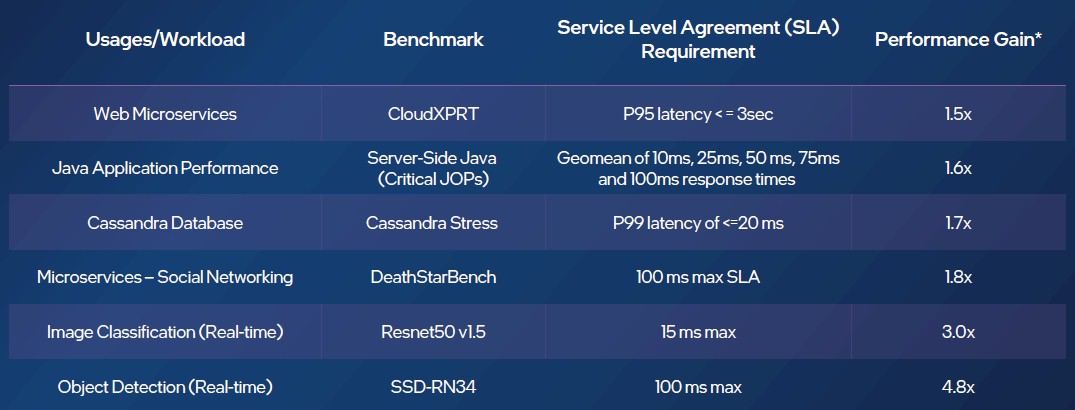
The interesting bit here is not how the performance compares between the two Xeon SP generations – they are essentially the same 1.5X to 2X we said above excepting AI inference work – but the SLA settings for each workload.
The following chart from Intel shows the performance and performance per watt increases for various workloads, which is not a chart we have seen before and which is absolutely honest about the fact that increasing performance is a heck of a lot easier than increasing energy efficiency and shows that Intel sacrificed energy efficiency to drive performance with Sapphire Rapids:
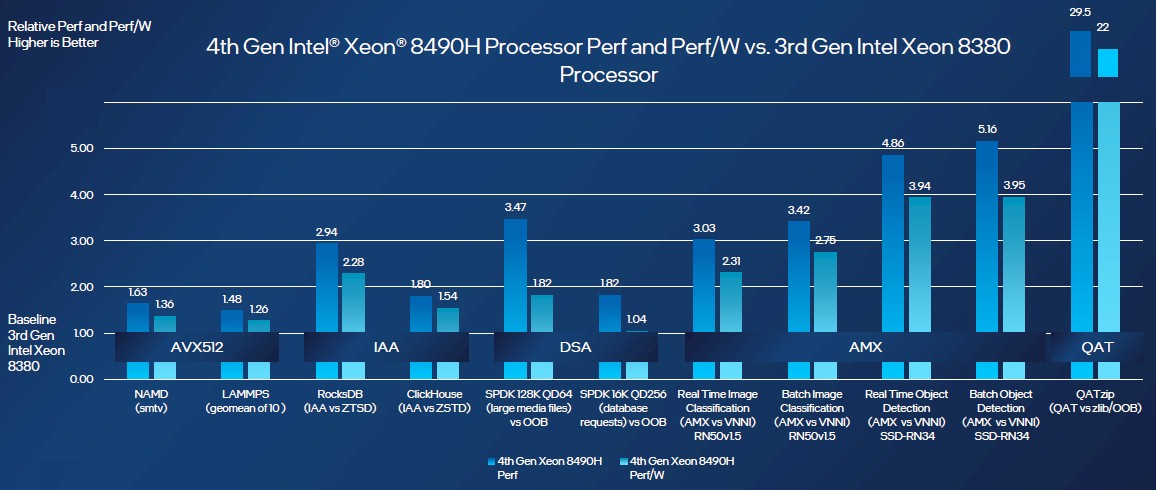
This is what happens when you are stuck at a 10 nanometer process, as Intel 7 is. Intel really needed at least a real 7 nanometer process (what is now called Intel 4) to drive down energy consumption with Sapphire Rapids, but the yields are so bad that it is moving to Intel 3 (5 nanometer) process for the next-generation “Granite Rapids” due in 2024.
But the problem is affecting all compute engines, and there is no question that all CPUs, GPUs, FPGAs, discrete AI engines, and switch ASICs will keep pushing up thermal limits to drive performance. This was certainly the case with the “Genoa” Epyc 9004 chips launched by AMD in November 2022.
By the way, if you look at the entire Sapphire Rapids SKU stack, there is one XCC configuration that has four 16-core chiplets and one monolithic MCC die that has 34 cores on it. There is no Sapphire Rapids chip that has all of the cores active. There is one XCC with 60 cores, two with 56 cores, four with 52 cores, five with 48 cores, and on down from there. For the MCC die, there are six that have 32 cores (which is a pretty high yield), one with 28 cores, six with 24 cores, and on down from there. The higher the active core count, the cost of the chip gets higher and therefore the cost of the compute engine goes faster than the compute capacity does.
From Nehalem To Sapphire Rapids — And Beyond
Which brings us to our own analysis.
In our generational comparisons, we have done our best to show how different parts of the Xeon and Xeon SP lines have changed over time in terms of relative performance, price/performance, performance per watt, and cost per performance per watt. If you did a similar analysis, you might pick different ways of comparing, and you might not have picked three different SKUs for each type of CPU we are looking at when we analyzed the 14 nanometer 2017 “Skylake” generation through the current 2023 Sapphire Rapids generation. We concede that there are many ways to look at this. But we think this gives a sense of how hard it is to boost performance – either single threaded or throughput oriented – while keeping the watts and costs under control. Given the Intel architecture as a starting point, the restrictions on Intel foundry processes, and the increasing competitive pressure, it would be hard to figure out how Intel could have extracted more money out of the server market than it has. But its success in being profitable during its technological downturn has sown the seeds of its successful competition.
You always end up paying the piper in the long run, and the interest compounds. And in the long run, a whole bunch of people at Intel made that Pat Gelsinger’s problem. We believe in redemption for Intel as much as we ever believed it for AMD, and not just because it is good for server buyers. This is just the way it is, and with proper investment and focus Intel can build a foundry business that rivals the amazingly profitable Taiwan Semiconductor Manufacturing Co and use profits from that business to underwrite its PC and server CPU businesses. TSMC has a much stronger monopoly on the making of smartphone, non-Intel PC, and non-Intel compute engine processors than Intel ever had during the heyday of its Data Center Group.
In our analysis, we look at three categories of chips: those with high core counts focused on throughput, those standard parts with a moderate mix of cores and clocks, and those with high clock speeds and relatively low core counts (because of thermal limits) focused on more single-threaded workloads.
In all cases we are using our own relative performance metrics, which is gauged relative to the Nehalem Xeon E5540, which was a four-core, eight thread X86 CPU that ran at 2.53 GHz, consumed 80 watts, and cost $744. We calculate relative performance by multiplying the number of cores times the clock speed times the relative improvement in instructions per clock (IPC), and set this processor at the 1.00 level and reckon all of the other 337 official Xeon and Xeon SP SKUs launched between 2009 and 2023.
Let’s start with high core count comparisons:
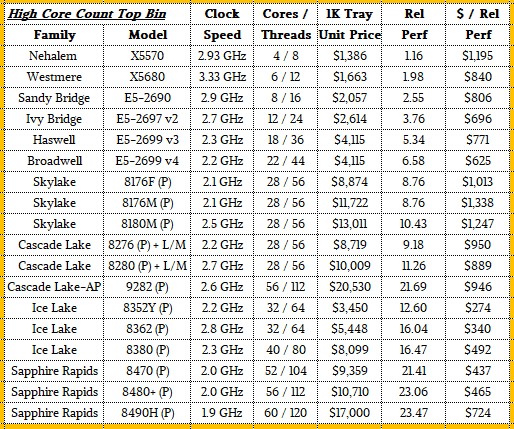
In each case, we want you to have the raw data so you can see the clock speeds and prices and the relative performance and relative value that we have calculates. We will also present the data visually do you can see the trends:
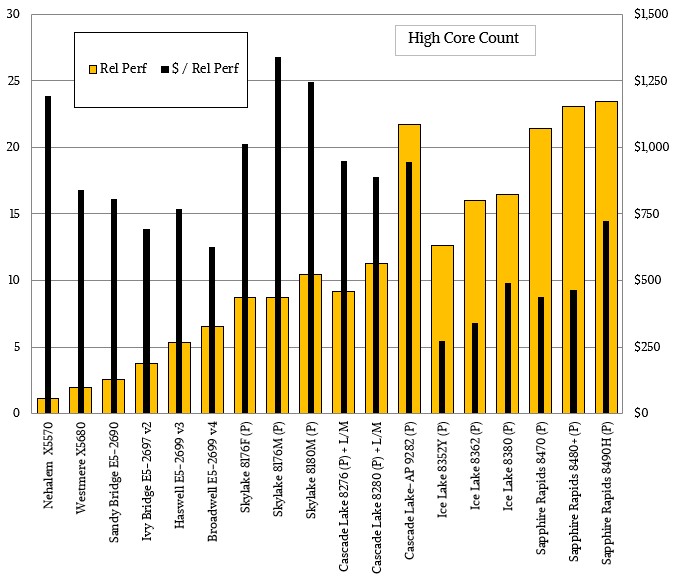
What is immediately obvious, and what we pointed out back in September 2017 with the Skylake Xeon SP launch, is that in the absence of any real competition in the datacenter, Intel charged a huge premium for Skylake processors, and particularly so with chips with a lot of cores. As competitive pressure from AMD started that year and increased a lot on 2019, Intel revamped with the “Cascade Lake” generation and boosted performance per chip a little and had to resort to a dual-chip module to field anything that could “compete” against the 64-core AMD “Rome” Epyc 7002s. As AMD gained steam, it did a “Cascade Lake-R”
By the time the Ice Lake Xeon SPs came in April 2021, Intel boosted the performance a bit by boosting core counts from 28 to 40 and jacking up IPC with the “Sunny Cove” cores by 20 percent, and out of necessity it slashed prices for these CPUs, which were restricted to to-socket machinery. The pricing on high core count Ice Lake chips was about as low as it should have been if Intel had been following the historical trends from the Nehalem through the Broadwell generations.
And here we are in the Sapphire Rapids generation, and for high-core count processors, what is Intel doing? Charging a hefty premium for its most capacious CPUs. This may seem counter intuitive, but this time around, unlike with the Skylake Xeon SP CPUs, Intel is only charging that premium for high core count parts. (And for HPC parts that have HBM memory, which we are going to analyze separately.) This premium is not there for standard Sapphire Rapids parts nor for variants that have high clock speeds.
Performance is not everything. Power consumption and overall value (taking into account power consumption and performance) are also considerations – particularly for hyperscalers and sometimes cloud builders. So we cooked up this comparison that brings all of this together:

Our relative performance metrics have too few significant digits, so to get human scale numbers, we arbitrarily multiplied our performance figures by 1,000 and then calculated performance per watt and cost per performance per watt.
If you compare the Nehalem X5570 against the average of the three Sapphire Rapids chips shown, then performance has increased by a factor of more than 20X, but the price/performance has only improved by a factor of 2.2X. Watts have gone up by a factor of 3.7X, and that means performance per watt has been diluted to only a factor of 5.3X. And if you do the math all the way out, then cost per performance per watt over those fourteen years has been decreased by a factor of 1.67X. In other words, it is 67 percent more expensive per watt to buy a unit of performance on high core count Sapphire Rapids Xeon SP than it was on the equivalent Nehalem Xeon. That’s an average of the three chips shown. If you take the Sapphire Rapids chips individually, the 60-core part is more than twice as expensive per unit of work per watt, while the other two are only 35 percent and 49 percent more expensive per unit of work per watt.
That multichip packaging of the Sapphire Rapids Xeon SP is making it very costly, it looks like. And Intel has to charge a premium for it. Or at least try. And Intel also wants to charge a premium for NUMA scalability that AMD does not offer and that only IBM with its Power Systems and System z mainframes does – and at a very large premium.
Now, if we move to more mainstream, standard X86 server chips, the situation for Sapphire Rapids improves considerably.
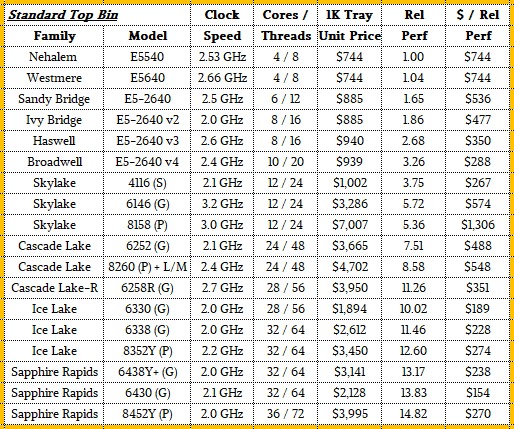
The lower core chips have a higher yield and also a lower cost, and because they have similar clock speeds as the heavily-cored parts, they offer better bang for the buck.
Here is the price/performance chart to go with the table above:
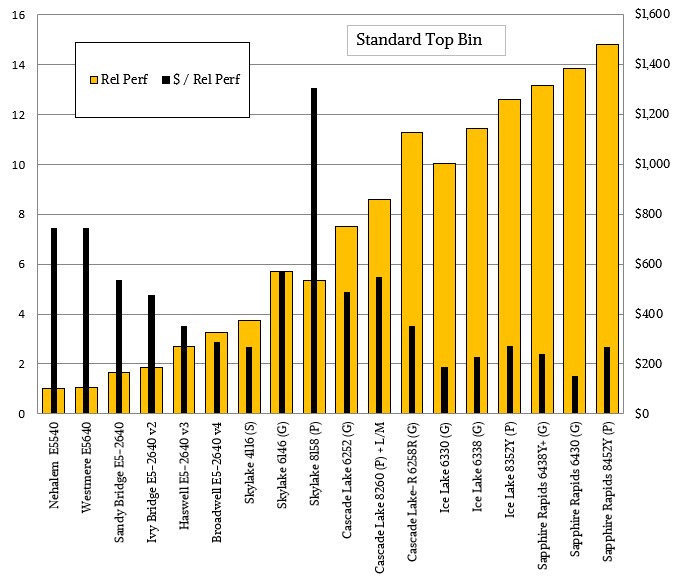
As you can see, the Sapphire Rapids chips offer about the same value as the Ice Lake chips – on average it is a little bit lower for the chips shown.
The wattages on these classes of chips are also lower, in general, and that makes for a much flatter cost per unit of performance per watt over time. In fact, on average, Sapphire Rapids mainstream parts are offering the same thermoeconomic oomph – we need a better term than “cost per performance per watt” – as the Nehalems did back in 2009.
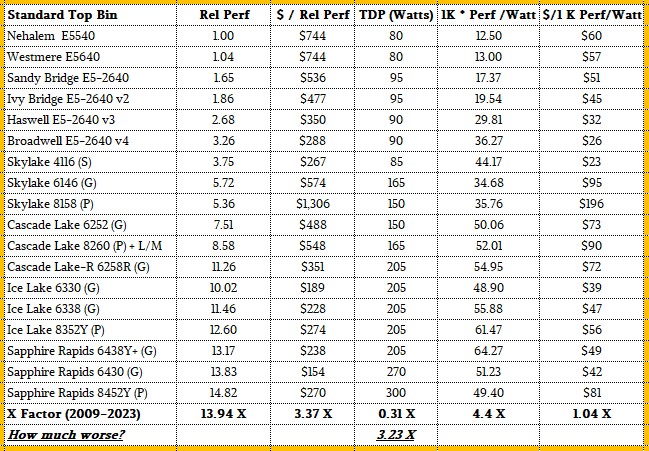
It would be better if it was a lot lower, but the hyperscalers can make some of that up by getting larger and larger discounts. Or moving to a different vendor or architecture that is using a smaller transistor than Intel can deliver right now.
That brings us to our third comparison: Processors with high clock speeds and relatively few cores.
In days gone by, Intel always had a chip with four or eight cores, but that is just not technically very useful anymore, so eight cores has been the minimum with the Ice Lake and Sapphire Rapids chips.
As you can see, clock speeds for chips with low core counts have held up pretty well over time, but have not radically increased:
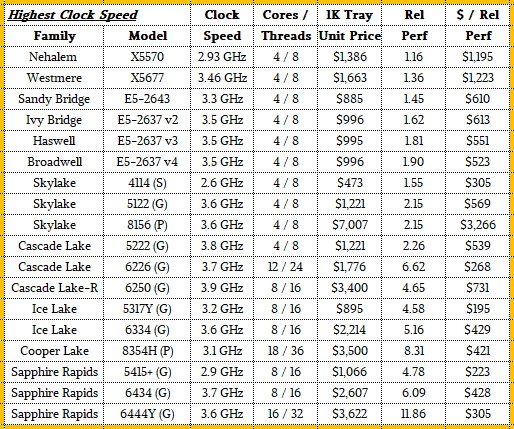
Being able to double or triple the cores, more than double the IPC, and grow clocks 16 percent is about all you can expect as Intel moved from 45 nanometer processes with Nehalem to 10 nanometer processes with Sapphire Rapids – particularly with Dennard scaling (the ability to shrink transistors and increase their clocks proportionately without increasing thermal dissipation) slowing in 2008 and stopping around 2013.
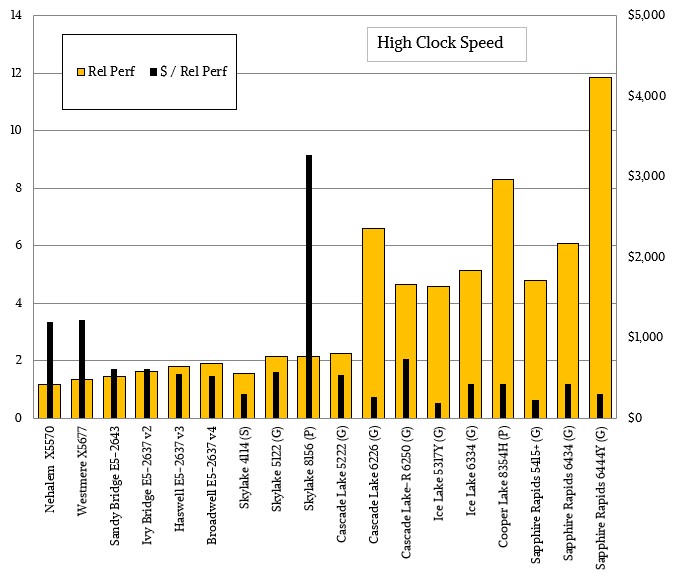
With the exception of the Skylake Xeon SP-8156 Platinum, the cost per performance of the high clock speed Xeon and Xeon SPs has been remarkably stable:
And their thermoeconomic oomph has improved, however jumpily, over time, too:
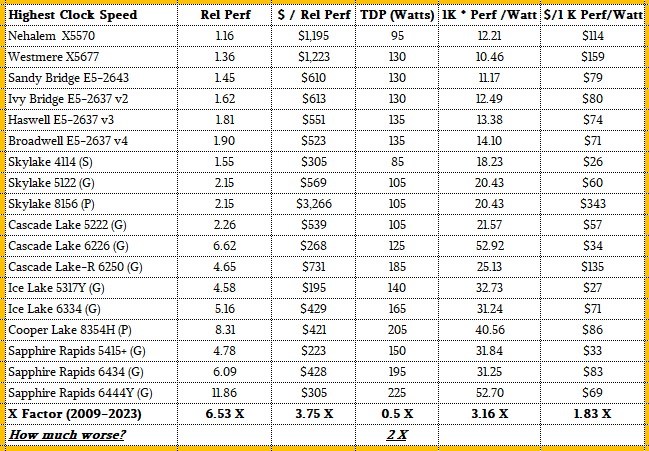
Intel needs to get onto 5 nanometer processes for its Xeon SPs as soon as it can and push to get parity with AMD around 3 nanometers, but it will probably take until 2 nanometers to do this. TSMC seems to be on track with its plans for 3 nanometer chip production in 2023 and 2 nanometer processes in volume in 2025.
Up next, we will do a deep architecture dive on the Sapphire Rapids Xeon SPs and then look at the competitive situation between the Intel and AMD X86 server chips, and take a stab at trying to figure out how both compare to Arm server chips. We also want to look at the HPC, network, edge, and NUMA big memory applications where Intel is in a better competitive position.




All I want is a workstation with one of these beasts…
This is most true for ARM. A lot of workloads get deployed on x86 because they were developed and tested on x86. The lack of high-performance ARM Linux workstations limits ARM adoption for a lot of companies.
I understand. And by the way, I thank you for all you do for The Next Platform.
ADLink has an Ampere workstation: https://www.adlinktech.com/products/Computer_on_Modules/COM-HPC-Server-Carrier-and-Starter-Kit/Ampere_Altra_Developer_Platform?lang=en. Since we designed Ampere Altra and Altra Max for server platforms, there are many more rack mounted servers that are likely overkill and louder than what you’re looking for, but we have a few other things in the works that might be up your alley. Let me know if I can help.
If inflation was not already factored in to the dollar numbers, it would be interesting to see those charts normalized to 2009 dollars. Not insignificant over 13+ years. There’s a 26.3% difference to 2021 and 36% for 2022.
I have inflation adjusted numbers in the past, particularly for server revenue data that spanned 25 years. It tips the curves up on the left and down on the right, and the further you go back, the more it tips up on the left.
another author who won’t accept Intel’s renaming of its process nodes to match the naming used by its competitors for similar density nodes.
I generally stop reading as soon as I see this, and make a mental note to not visit the site again for anything substantive.