

There is no question that Intel has reached its peak in the datacenter when it comes to compute. For years now, it has had very little direct competition and only some indirect competition for the few remaining RISC upstarts and the threat of the newbies with their ARM architectures.
The question now, as we ponder the “Skylake” Xeon SP processors and their “Purley” platform that launched in July, is this: Is Intel at a local maximum, with another peak off in the distance, perhaps after a decline or perhaps after steady growth or a flat spot, or is this the actual peak? Actual peaks exist, and they are hard to call. IBM hit its peak with the ES/9000 bi-polar mainframe in 1990, when prices actually went up for mainframe capacity, to a whopping $100,000 per MIPS. Sun Microsystems hit its actual peak in 2001 with its “Cheetah” UltraSparc-III processors, when prices for systems using these chips also rose faster than performance and bang for the buck actually dropped.
These are but two such examples in the enterprise datacenter, but they could turn out to be prophetic with respect to the Xeon platform, particularly with AMD ramping up its Epyc processors, Cavium and Qualcomm fielding credible ARM processors, and IBM getting ready to ramp its Power9 beasts. It is not a coincidence that the mainframe was hit by recession and the Unix and open systems movement back in the late 1980s and early 1990s and IBM reacted as it did, nor is it a coincidence that Sun decided to milk its UltraSparc base when it did in the wake of the dot-com bust.
When IT vendors are nearing their peak, they have come under competitive pressures, have saturated their markets, or run up against a manufacturing cost barrier that they cannot get around and their ability to extract ever-increasing profits drops. Those with captive markets facing intense competition often decide to squeeze their customers and get the money now with the hope of competing better in the future. Wall Street demands it, stock-based compensation demands it. So, the knee-jerk reaction is to charge more for each unit of capacity, and clothe it in rhetoric that the resulting system is inherently – and more subtly – more valuable and therefore worth the premium that is now being charged.
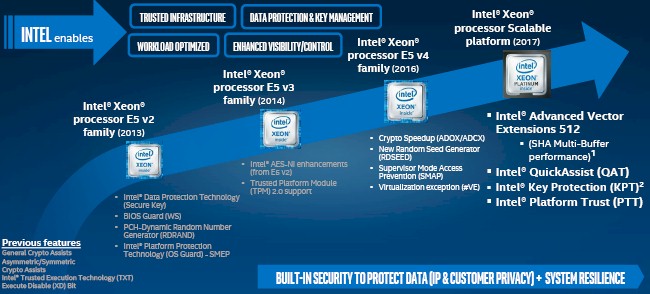
Intel has certainly done a lot of engineering to justify the cost of the Skylake chips and the Purley platform, the feeds and speeds of which we have gone through at their announcement back in July with a deep dive on the architecture in August. At a set of briefings that Intel has given to The Next Platform, the company’s top brass within the Data Center Group outlined how they evolved the Xeon platform over the past several generations, focusing on performance, agility and efficiency, and security as the areas that mattered most to enterprise customers. Intel’s comparisons ranged from the “Ivy Bridge” Xeon E5 v2 processors through the current Skylake Xeon SPs, which are the result of the convergence of the Xeon E5 line for workhorse two-socket and four-socket systems and the Xeon E7 big memory machines that have four or more sockets. We tend to think of the “Nehalem” Xeon 5500 processors as the foundation of the modern Xeon business, since they are so architecturally different from the Xeons that preceded them (and very much resembled the Opteron processors from rival AMD at the time the Nehalem chips were launched in March 2009). But you can only cram so many generations of stuff onto a chart.
Intel’s comparison charts are general and illustrate the features that have been added to the Xeons, and they are interesting in this regard because it reminds us of how much cleverness Intel does etch into its circuits. Advancing processor performance has not been a matter of just shrinking transistors for nearly two decades, and the fact that Intel can squeeze ever-more performance out of a set of transistors is nothing short of stunning. People complain about the slowing of Moore’s Law and Dennard Scaling, but given these constraints, you have to admit Intel – and its rivals – have done pretty well for us and, therefore, for themselves.
We tend to think of performance first, so here is how Lisa Spelman, vice president and general manager of Xeon products and the Data Center Group marketing efforts, put all of the highlights from Ivy Bridge through Skylake

The Nehalem Xeons topped out at four cores, the “Westmere” Xeons at six cores, and the “Sandy Bridge” Xeons, the first E5 and E7 chips, came in at eight cores, just so you have a reference for the time before this chart above starts. The Xeon processor has gotten wider and has been packed for more and more features even as we have hit the clock speed ceiling – to be honest, it is because we have hit that ceiling. If you can’t go up, you have to go out.
The agility and efficiency features that have been added over time look like this:

This chart demonstrates the finer grained virtualization and other advanced RAS features – that’s short for reliability, availability, and scalability – that Intel has added to each new generation of chips. For the longest time, the RAS features were only in the high-end Xeon E7 chips and Intel commanded a premium for these just as it did for NUMA scalability and memory addressability. Intel still does charge a premium for these and other capacities and features, but it is now doing it with different styles of Xeon SP processors – Platinum, Gold, Silver, and Bronze – that all share a common socket. That Socket P is good for customers and for server makers alike, but let’s not get confused. Intel is charging a premium, bigtime, for its most capacious Xeon SP chips. (We will get into just how much in a second.)
Security is becoming more and more of an issue in datacenters, and companies want to have this security be native to the processor and not a bolt on or something that eats up general purpose compute capacity through encryption software. Like other chip makers, Intel has been embedded more and more encryption and hashing functions to the chip as accelerators as the years have gone by, and this in part does justify the price of the processors.
Said another way, in the absence of these features, Xeon prices would have had to been lower than they were at launch; whether or not this justifies a price/performance increase is subject to debate. In the 1980s, 1990s, and 2000s, customers were accustomed to seeing price/performance increases between server generations, but the pace of price drops for compute capacity have not been as great as the performance increases. In some cases, Intel has been able to command a premium for compute, and with the Skylake chips, it is pushing this premium even higher in more specific cases – at least at the list prices it shows for chips that are purchased in 1,000-unit trays. We think the hyperscalers get their chips at 50 percent of list, which just goes to show you how volume affects price.
Doing The Bang For The Buck Math
We want a more precise way to gauge how all of the hundreds of Xeon processors, from Nehalem to Skylake, stack up against each other, and so we cooked up a relative performance metric to do just that. Back in April 2016, in the wake of the “Broadwell” Xeon E5 v4 processor launch, we detailed all of the prior generations of Xeons back to Nehalem using this relative performance metric, and we are not going to add all of that data on those entire chip families to this story. Reference that one for the details on the prior generations.
As Intel’s presentation above aptly demonstrates, with each successive Xeon processor generation, the number of features that the chip supports goes up, sometimes in big jump and sometimes in little steps, but there is always this forward motion of progress where hardware is implemented to do something better or quicker than can be done in software.
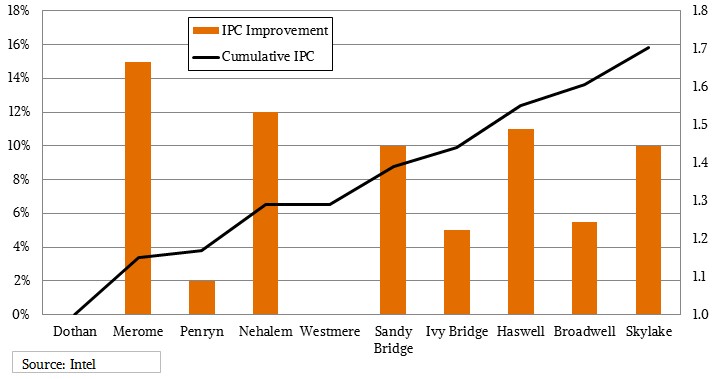
One important aspect of performance has to do with microarchitecture, and how Intel tweaks pipelines, branch predictors, registers, caches, on-die interconnects, and other aspects of the chips to boost the number of instructions per clock (IPC) that it can process in recent generations is impressive, and if you use the “Dothan” Cores used in the Pentium M mobile processors and earlier generations of Xeons back in 2004 as a baseline, then the IPC across the past eight generations has gone up by a factor of 1.7X in the past thirteen years. (This is single thread performance on a single core normalized for clock speed, and reflective of the underlying architecture changes.) Broadwell cores had about a 5.5 percent IPC improvement over the prior “Haswell” Xeon cores, and the “Skylake” Xeon cores delivered a 10 percent improvement in IPC over the Broadwells because this was a microarchitecture “tock” not a processor shrink “tick,” in the Intel parlance.
As we pointed out last year with our Broadwell analysis, the overall throughput of any processor is more or less gated by the aggregate number of cores and the clocks they can cycle. Aggregate clocks is a rough indicator of relative performance within a Xeon family, but is not necessarily good across families. Luckily for us, we know the IPC improvement factors with each core generation, and knowing this we can do a rough reckoning of the relative performance of processors dating back to the Dothan cores if we want to.
The Nehalem Xeons, as we pointed out, are an architectural turning point, so we have measured from there to create our relative performance metric – called Rel Perf in the following tables – that takes into account the aggregate clocks and the improving IPC of each generation. The performance of each Xeon in those seven generations is calculated relative to the performance of the Xeon E5540, the four-core Nehalem part introduced in March 2009 that was the top of the standard performance part of the Xeon line. And the cost per unit of performance, or $ / Rel Perf, is the price of the chip at list price divided by this calculated relative performance. With this simple metric, we can compare the oomph and bang for the buck across the Xeons – albeit in a very rough way. We are working to get the full integer, floating point, and database performance metrics for these Xeon families, which Intel collects. This is just a beginning, not an end. And, as usual, such data as we are presenting is meant to give you a starting point from which to make your own application benchmarking decisions, not purchasing decisions. You should always run your own tests.
For starting reference, let’s remember how skinny the initial Nehalem Xeon product line was and refresh our memory about its basic feeds and speeds:
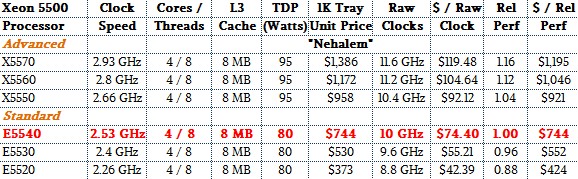
The touchstone Xeon E5540 had four cores running at 2.53 GHz and 8 MB of L3 cache, and we are setting this at a relative performance of 1.00. The faster X5500 variants clocked higher, and customers had to pay a fairly heavy premium for them. The Westmere Xeons from 2010 were a straight-up process shrink with an extra two cores tossed onto the die. With the Sandy Bridge Xeons in 2012, Intel doubled up the cores over the Nehalems to eight and added a slew of new features and functions, something that was made possible by the fact that it delayed the Sandy Bridge launch by almost a year because of a bug in the on-chip SAS drive controller. With this generation, the generic IPC level (which is really an expression of integer, not floating point, performance, went up by 10 percent. Ivy Bridge had a process shrink and some modest IPC gains, Haswell was a bigger IPC jump, and Broadwell was a process shrink again with a modest IPC gain. (You can see our detailed analysis of these IPC bumps here.)
Making comparisons across the Skylake Xeon lineup and with prior generations is somewhat complicated by the fact that this line is the convergence of the Xeon E5 and E7 lines. In a way, this really should be called the Xeon E6.5 line, since if you look at all of the SKUs, there are an awful lot of Platinum and Gold processors that support four or eight processors. There are not nearly as many chips that support just two sockets, and many of them that do have integrated 100 Gb/sec Omni Path fabric controllers on their packages. (Hmmm. Funny that.) Take a look at the Skylake Xeons and their relative performance metrics:
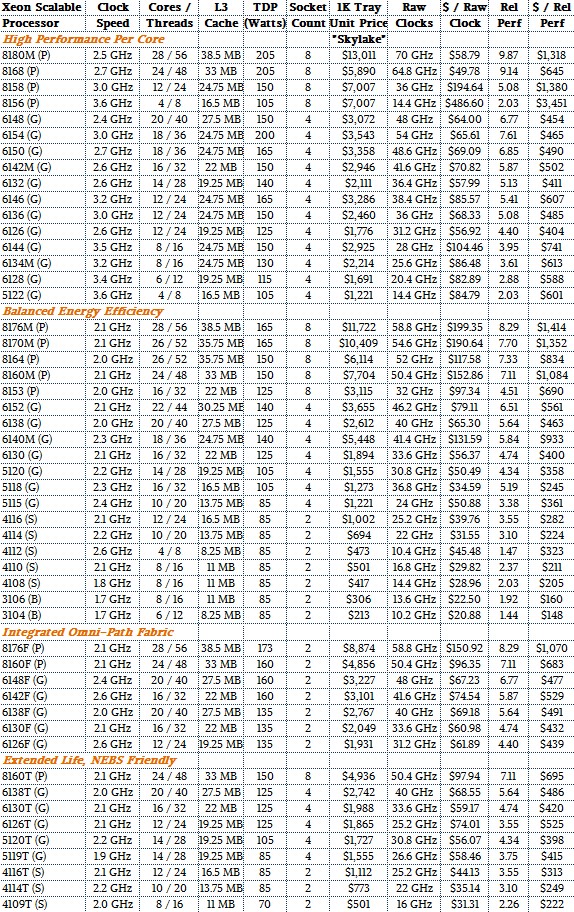
See? There are no versions of the Skylake processors that support two sockets that are in the High Performance Per Core category, as if customers who had two socket servers did not also want high performance. (Maybe Google and Microsoft are going to be buying up four-socket and eight-socket boxes by the millions to drive their search engines?) The Broadwell Xeon E7, which supported four and eight sockets, had 24 cores compared to the Xeon E5, which topped out at 22 cores and, practically and economically speaking, was only affordable with 18 cores or fewer with clock speeds at 2.3 GHz or lower. You had to really want 22 or 24 Broadwell cores, and you had to either be paying an HPC premium (which supercomputing centers are used to) or getting a hyperscale discount (which the biggest web players demand).
The 51 SKUs in the Skylake product line are a lot to take in all at once. There seems to be a little something for everyone, except a SKU that is tuned for single-socket servers. (We think that will change soon enough, particularly if AMD starts getting traction with its Epyc X86 chip line with its strategy of replacing two-socket Xeon servers with single-socket Epycs.) As we did last year with the Broadwell comparisons, this year with the Skylakes we are going to try to make comparisons for three types of CPUs: those with the highest core count, the top bin of the standard partners, and those chips with the four cores of the original Nehalem chips to show what improvements in IPC and architecture along with process mean in terms of performance when the core count is constant.
There are obviously lots of different ways to dice and slice the comparisons, but we are trying to reckon in the bang for the buck is flat, down, or up.
For reference, here is a table showing all of these three comparisons, which will make it easier to think about:
Now you have all of the summary data culled from the seven generations of tables so you can look at it. (The raw data for Skylake is above and for the Nehalem through Broadwell lines is in the story we published last April.)
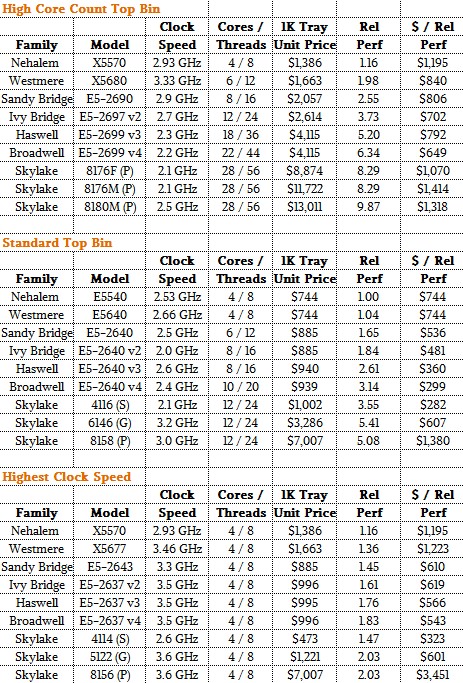
Let’s start with the high core count comparison. Here is a pretty picture that shows the performance and price/performance changes, generation to generation, with the processors with the highest core counts. With Skylake, things get a bit tricky because there are SKUs that stress performance at the expense of energy efficiency and SKUs that try to strike a balance between oomph and power draw.
 The first thing to note is that there is no 28 core version of the Skylake processor that is aimed at two-socket servers that does not also include the Omni-Path fabric ports. The Xeon SP-8176F is the only option. You can get an 8176M, which runs at a mere 2.1 GHz like the 8176F, from the balanced Xeon SP part of the line, or an 8180M, which runs at 2.5 GHz, from the high performance part of the line. But these chips are both made for eight-socket servers and carry a pretty high NUMA tax with them, with prices of $11,722 or $13,011 respectively, compared to $8,874 for the 8176F. Here is the funny bit. That 8176F processor with 28 cores running at 2.1 GHz has 31 percent more relative performance than the E5-2699 v4 Broadwell chip running at 2.2 GHz, but it costs more than twice as much, yielding a bang for the buck that is 65 percent worse. The spread to the two other top bin Skylake parts that scale to eight sockets rather than two is even worse. The Skylake 8180M has 56 percent more performance, but it costs 3.2X as much and the resulting bang for the buck is twice as bad.
The first thing to note is that there is no 28 core version of the Skylake processor that is aimed at two-socket servers that does not also include the Omni-Path fabric ports. The Xeon SP-8176F is the only option. You can get an 8176M, which runs at a mere 2.1 GHz like the 8176F, from the balanced Xeon SP part of the line, or an 8180M, which runs at 2.5 GHz, from the high performance part of the line. But these chips are both made for eight-socket servers and carry a pretty high NUMA tax with them, with prices of $11,722 or $13,011 respectively, compared to $8,874 for the 8176F. Here is the funny bit. That 8176F processor with 28 cores running at 2.1 GHz has 31 percent more relative performance than the E5-2699 v4 Broadwell chip running at 2.2 GHz, but it costs more than twice as much, yielding a bang for the buck that is 65 percent worse. The spread to the two other top bin Skylake parts that scale to eight sockets rather than two is even worse. The Skylake 8180M has 56 percent more performance, but it costs 3.2X as much and the resulting bang for the buck is twice as bad.
If companies are going to buy half as many servers and save big bucks there, this makes sense. But only in terms of operational costs. The cost for compute has not come down. The top bin Haswell Xeon E5-2699 v4 chip with 18 cores had a premium, so this was not unprecedented. But it is nothing at all like the Skylake premium.
We can see why Intel might want to charge a premium for the converged Xeon SP chips with lots of cores and the ability to scale across a lot of sockets, but we have a harder time seeing why the two-socket Xeon SPs with lots of cores do not give better bang for the buck compared to the their Haswell and Broadwell predecessors.
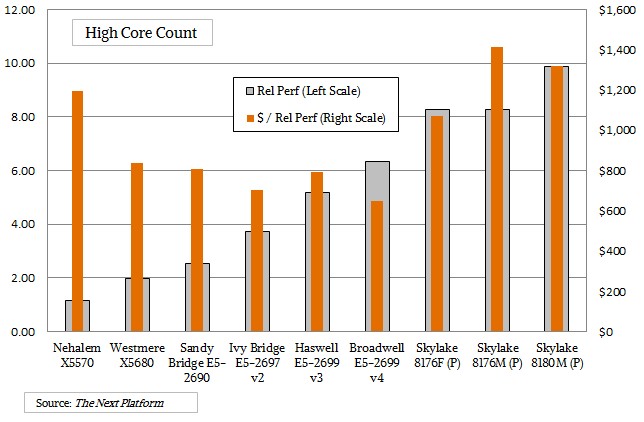
Maybe this issue is just with the high core count chips, which are more expensive to manufacture because, given the large size of their dies, their yields are by necessity lower. So what about the top bin parts in the more standard, balanced for energy efficiency part of the Skylake line? Take a look:
The results here, as you can see, are mixed, and it depends on if you choose a Silver, Gold, or Platinum model. For these comparisons of more standard parts, we had eight-core Ivy Bridge and Haswell parts lined up against ten core Broadwells and twelve core Skylakes. The core counts go up modestly with generations, and generally the clock speeds have fallen a bit even as the overall throughput of the processors, as gauged by our Relative Performance metric, has gone up. Again, with the Skylakes the comparisons get a little harder because there are entry chips, midrange chips, and high end chips with twelve cores, each with different levels of NUMA scalability, UltraPath Interconnect ports, memory addressability, AVX-512 floating point capability, and so on.
In the case of the Xeon SP-4116, which is a Silver level chip (meaning it is geared down compared to the Platinum and Gold chips), the throughput performance is up by 13 percent, but the price only rose by 7 percent to $1,002, so the price/performance actually improved by 6 percent. With the Gold-level SP-6146, the cores are clocked up to a much higher 3.2 GHz, the chip burns a lot hotter at (165 watts compared to 135 watts for the SP-4116), and the performance over the standard top bin Broadwell E5-2640 v4 chip is up 72 percent. But the cost rises by a factor of 3.5X, so it is actually twice as expensive per unit of performance. If you go to the Platinum-level Xeon SP-8158 in the Skylake line, the clocks are geared down a little, the oomph is a little lower, but the resulting chip costs more than seven times as much as the Broadwell chip it sort of replaces, and the bang for the buck actually decreases by a factor of 4.6X. Which is amazing. Bold. Perhaps incredibly foolish, or utterly brilliant. At least in the short term. Or maybe not. Who can be sure?
The market can be, and it will be. In due time.
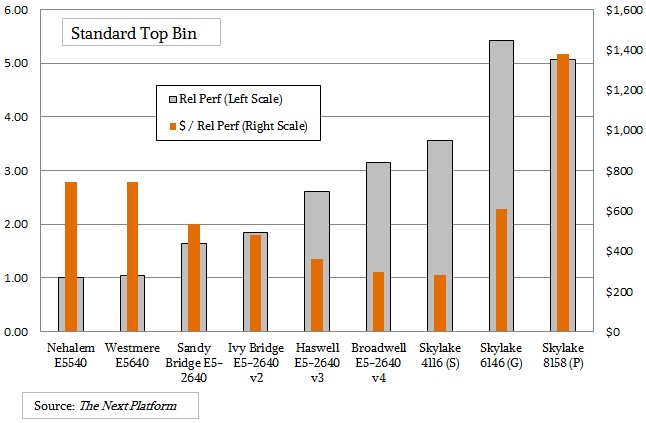
The story for the high clock speed chips in the Skylake line, capped at four cores, is much the same.
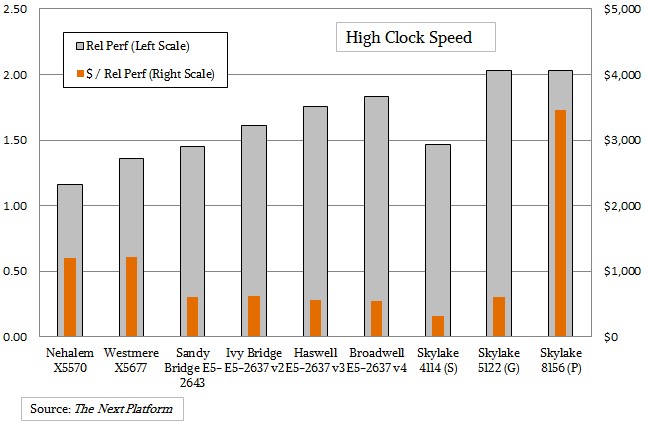 While the low-end Xeon SP-4116 running at 2.6 GHz offers pretty good performance and better bang for the buck than an equivalent Broadwell, it has a very low clock speed compared to the E5-2637 v4 at 3.5 GHz. The Skylake SP-5122, which is a Gold level chip, runs at a slightly faster 3.6 GHz, but the chip costs 2.6X as much and it offers half the bang for the buck. The Skylake SP-8156 is a Platinum chip running at the same 3.6 GHz and offering the same relative performance as the SP-5122 Gold chip, but at $7,007, it costs 7X as much as the Broadwell E5-2637 v4 and has 10X worse bang for the buck. These are the only four-core chips in the line with high clock speeds, so our selection criteria is not arbitrary.
While the low-end Xeon SP-4116 running at 2.6 GHz offers pretty good performance and better bang for the buck than an equivalent Broadwell, it has a very low clock speed compared to the E5-2637 v4 at 3.5 GHz. The Skylake SP-5122, which is a Gold level chip, runs at a slightly faster 3.6 GHz, but the chip costs 2.6X as much and it offers half the bang for the buck. The Skylake SP-8156 is a Platinum chip running at the same 3.6 GHz and offering the same relative performance as the SP-5122 Gold chip, but at $7,007, it costs 7X as much as the Broadwell E5-2637 v4 and has 10X worse bang for the buck. These are the only four-core chips in the line with high clock speeds, so our selection criteria is not arbitrary.
The Platinum Skylake chips offer the fastest 2.67 GHz DDR4 memory, capacities up to 1.5 TB per socket, full AVX-512 floating point, and up to three UPI links for scalability from two to eight sockets. If you just want to build a two-socket server with maybe 512 GB of memory, you are paying a lot of AVX-512 and NUMA tax if you want high core counts with modest speeds or high clock frequencies with four cores compared to the prior Xeon lines. This will be a conundrum for many customers. And this is definitely the behavior of an IT vendor at its peak. Whether this is a local maximum for the Xeons or the last Xeon peak, we shall see.
We realize, of course, that a theoretical relative performance metric on raw processors is not the same as real system level benchmarks on priced machines. This is just the first step in getting our brains wrapped around what Intel is doing with the Skylake Xeons.

Intel Reacts To The Competitive Heat On Its Xeons
Whatever is going on with its competitive positioning against revitalized X86 server chip rival AMD, Intel clearly felt that it could not wait for the launch of its 14 nanometer “Cooper Lake” and 10 nanometer “Ice Lake” Xeon SP processors to address it. And so today the chip maker is …
IBM Power10 Shreds Ice Lake Xeons For Transaction Processing
Here is a simple algebraic equation that describes the relative computing oomph of two different CPU architectures over the past two decades: If Intel an X86 core is X, then an IBM Power core equals 2X. IBM’s Power family of processors and their resulting hardware systems has never been particularly …
The Highly Profitable Chip Making Monopoly Called TSMC
When Taiwan Semiconductor Manufacturing speaks, the datacenter sector of the IT industry listens because, with few exceptions, this foundry etches the compute, networking, and storage engines that power the datacenter. And the rest of the entire IT industry also listens, particularly the smartphone industry and a good portion of the …
“For years now, it has had very little direct competition and only some indirect competition for the few remaining RISC upstarts and the threat of the newbies with their ARM architectures.”
Datacenters? Now let’s talk about server, not datacenters (which is term invented to make Xeons shine).
Intel datacenter group is some $14B per year. SPARC servers (sold as systems, not including cloud) are between $2B and $3B. IBM POWER and z servers (again, excluding cloud) was between $8B and $10B. Plus probably some ARMs already deployed here…
But yes, something near 50% is just little to some competition. 😀
Xeons are nothing but bottlenecks compared to Epyc.
You list the 5118 (G) as 16 cores at $245 / Perf but I see it as a 12 core product…?
With Epyc’s single socket SKU pricing for say the Epyc 7401P with its 24 cores /48 threads at $1075 representing an even better deal on a per-core pricing basis than even AMD’s Threadripper consumer 1950X(16 core/32 thread) SKU at $999, some appear shocked when I first bring up the subject. So the Epyc 7401P offers at only $76 dollars more than the Threadripper 1950X($999) an Epyc single socket server/workstation option with 8 more cores/16 more threads than the consumer Threadripper(16core/thread 32) SKU. That Epyc 7401P’s per core price comes to $44.79(rounded) per core($1075/24) with the Threadripper 1950X’s ($999/16) cost coming in at $62.44(rounded) per core.
And that represents a reversal of market segmentation compared to Intel, with Intel’s Xeon parts costing even more than Intel’s consumer parts on a feature/feature basis but AMD’s Epyc parts are actually a better value on a feature for feature basis than even AMD’s consumer parts and that is fairly mind boggling from some to consider.
The very Idea that the Workstation/Server SKUs from Intel’s are always a much more costly proposition for so many years has led the entire market into not quite being able to digest the fact that AMD’s Epyc workstation/server variants can actually represent a much better feature for feature value compared to any consumer CPU SKUs leaves some folks in a state of denial until I actually do the simple math and post the figures.
There are plenty of reporters at the usual enthusiasts websites so intent on showing the consumer Threadripper “Workstation” value that they have not even stopped to consider the fact that AMD’s Epyc single socket SKUs can and do in fact represent a better feature for feature/core for core deal against even a consumer SKU from AMD, not to mention being a better value than Intel’s consumer or Xeon SKUs, but a Workstation/Server AMD SKU having a better per core value against a consumer AMD SKU is so hard to imagine after so many years of Intel market/pricing domination.
It’s as if there is a collective Intel Market Domination form of Stockholm Syndrome where Intel’s Workstation/Server market domination has been so prevalent it the minds of everyone with some users having been forced to use Intel’s consumer SKUs for server workloads in order to be able to afford any option for compute that some people will not now believe what is so easy to prove. Epyc can and does represent such a great value that no longer will any user who wants a real workstation grade part will have to resort to purchasing a consumer part just to be able to afford any compute for workstation workloads.
Sure the Workstation Motherboards are going to cost more but on a feature for feature basis AMD’s Epyc on even a $550 single socket motherboard price estimate* beats any $399 Threadripper X399 motherboard pricing on a cost per PCIe lane or cost per memory channel provided basis. And some simple math can show that value metric with the respective platform’s motherboard total price divided by the number of PCIe lanes the respective platforms offer, ditto for doing the math for the respective platform’s motherboard’s total price divided the total number of memory channels offered for a little cost/feature metrics. And the Epyc platform offers twice the complement of PCIe lanes than the Threadripper X399 platform and twice the memory channels as the Threadripper platform.
So that’s for the Epyc platform($550 est MB price/128 PCIe lanes) at $4.30(rounded) per PCIe lane.
And for the Threadripper X399 MB ($399/64 PCIe lanes) at 6.24(rounded) per PCIe lane.
Again with the Epyc($550 est MB price/8 memory channels) at $68.75 per memory channel.
And with the Threadripper X399 MB(399/4 memory channels) at $99.75 per memory channel.
So even at a higher average cost estimate the Epyc feature for feature cost is less because Epyc offers twice the PCIe lanes as Threadripper and twice the memory channels, in addition to the example Epyc single socket 7401P that I used to prove my point. There is also the cost of ECC memory to consider but that’s the same across both platforms if the user wishes to use ECC memory, but the other feature/feature values stand on their own.
*Note: Single socket Epyc motherboard pricing is hard to find currently so I took the low end dual socket/2P Epyc MB pricing of $550 dollars as an estimate but even at that Motherboard pricing it does not change the end results on the overall feature/feature value of Epyc over consumer/Threadripper.
Tim,
In the enterprise space, the bang for the buck premium of the high core count processors is at least partially offset by software license savings on products like vSphere that are licensed by socket as opposed to cores.
Fair enough. There are a bunch of things that are priced per core, too. But VMware for sure is a lot less expensive. Ditto for per node pricing on a lot of commercialized open source software. Interestingly, this means Intel will shift some of the software budget to the hardware – a reversal in a trend that we have seen for decades.
That is certainly an interesting way to look at it. I always thought of it as savings through the higher core count breakthroughs are offset by VMware price gauging (raising the per socket price by $1k on the enterprise plus edition)precisely because they forgot to charge on a per core model
There’s also a bit of hardware savings, as with more cores in a processor, one typically doesn’t need additional Ethernet ports, more power supplies, or data center floor space. Rather than the customer getting that all of those savings, Intel would like to get part of that value.
Is it fair to use Platinum CPU’s in this comparison? The Platinum (as you said) is the replacement for the E7 CPUs, which are also very expensive compared to E5.
I’d say that even Gold should be left out since they replaced the E5-46XX, and you are only using E5-26XXs from previous generations, the only problem with that is that the Gold apparently replaced both E5-46XX and high clock and high core count E5-26XXs.
It seems a bit strange that you have to pay a Gold 4 socket “tax” to get high core or high clock even if the use is a 2 socket server. AMD is going to have a field day with 1 and 2 socket Epyc CPUs that have more cores, higher clocks, and much better prices than Xeon Gold.
Well, that is precisely the point. If you want high clocks or high core count, you don’t have a choice. And even if you do something in the middle, you still pay the Platinum tax. I could gin up a more modest comparison, something with no clocks and say only six cores on Haswell, eight cores on Broadwell, and maybe ten cores on Skylake. But I suspect the curves would look the same.