
If you want to break into datacenter compute in a sustainable way, it takes the patience of a glacier. And not just any glacier, but one that predates the Industrial Revolution. The reason is that IT shops are a conservative lot, and change comes slowly, even when they seem to be asking for it to move faster.
People were building servers out of X86 chips long before that was, technically speaking, a good idea. And the drive was that other architectures were so much more expensive than a PC flipped on its side and crammed into a metal pizza box. But eventually, the X86 chip was embiggened with server-class features for reliability and scalability – and it still took from the formal launch of the Pentium Pro in 1993 until the Xeon E5500 launch in 2009 for X86 servers to match the revenue stream from all other non-X86 servers – about $5 billion per quarter, X86 versus non-X86. Since then, non-X86 server revenues, according to IDC, have gradually and steadily shrank, but have stabilized in part thanks to the AWS buildout of servers based on its own Graviton2 Arm-based processors and partially to the relatively stability of IBM’s System z mainframes and Power Systems servers. The X86 revenue stream, however, has grown by a factor of 4X or so and wiggles up and down around $20 billion a quarter, give or take. There is almost an order of magnitude gap in the flows of those revenue streams. Take a look:
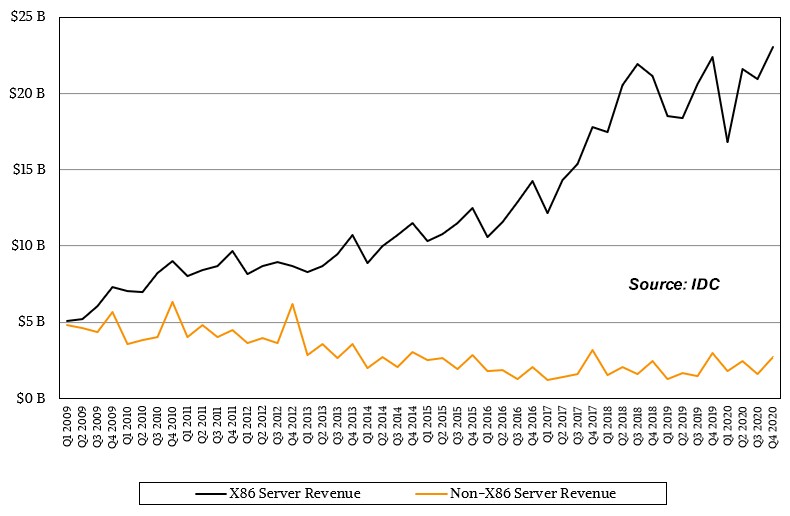
Even if the hyperscalers can do whatever they want because they own their software stacks, they are maniacs about TCO and only make changes to their infrastructure type when they have to. And those hyperscalers that have cloud computing units – which means all of them excepting Facebook – have to balance the compute enterprises will pay for now – which means largely X86 instances – as opposed to instances they might be able to port to in the future.
As we reported last week, Arm itself has some pretty impressive “Zeus” Neoverse V1 and “Perseus” Neoverse N2 designs that others will use as the foundations of their chips (including Amazon Web Services and Ampere Computing. But there are others who are joining the fray, and this is starting to feel like a party again.
The hyperscalers and the HPC centers are leading the way, as usual.
Let’s start by thinking about the big public clouds and why they might embrace Arm server chips.
We would guess that the profit margin on server capacity on servers using homegrown Arm server chips is a bit higher at the instance level, but we have no idea what the cost is to deliver a Graviton2 chip. But if you are going to create Arm processors for consumer devices and Nitro SmartNICs, then adding in Trainium and Inferentia chips for machine learning training and inference, respectively, and Graviton for raw compute starts to make sense. New applications that are relatively isolated, like HPC and AI for a lot of companies, can go on new chip architectures fairly easily, and AWS and its cloud peers can charge a premium for legacy X86 support – as we have discussed. In effect, the move to an Arm architecture can be paid for by those applications that cannot be initially and easily moved off an X86 architecture. And the gap will be wider or thinner depending on the profit pressure that Intel and to a lesser extent AMD are under. They will have to decide between market share and profits – the same position that Intel put Dell, Hewlett Packard Enterprise, Lenovo, Cisco Systems, and others in in the OEM server racket over the past decade when Intel kept most of the profits for itself.
Both wish that Arm Holdings and its licensing partners would just shut up. But AWS and Microsoft and Tencent and probably a few others are not going to shut up. Nvidia sure as hell is not going to shut up, even if it doesn’t succeed in acquiring Arm for $40 billion, because Nvidia has its “Grace” server CPUs coming onto the datacenter battlefield and it absolutely is going to engage against AMD and Intel and IBM for HPC and AI compute. Nvidia is focusing its Grace Arm server CPU on high-end serial work done in concert with parallel work on a hybrid CPU-GPU system for AI and HPC applications, but you can bet others will want to use it for more generic workloads, regardless of what Nvidia has intended, if the specs and prices are right.
This time around, Arm designs have HPC and hyperscale variants and features, and this is different from the first and second waves of Arm server chip attempts in 2011 and 2016.
In Japan, Fujitsu has already engaged with its A64FX Arm chips, outrigged with heavy SVE vector engines, offers a way to stand toe-to-toe with hybrid CPU-GPU clusters in the HPC arena, and SiPearl in Europe is creating its “Rhea” Arm CPU based on Neoverse V1 cores and offering four channels of HBM2E stacked memory or four to six channels of DDR5 memory to be matched with its RISC-V parallel accelerators. And South Korea’s Electronics and Telecommunications Institute (ETRI) is creating its K-AB21 Arm processor, also based on the Neoverse V1 cores, also supporting a mix of DDR5 and HBM2E memory, and also paired with custom parallel accelerators.

Chris Bergey, general manager of the infrastructure line of business at Arm, said in a Tech Day presentation last week that there is another national HPC center – in this case the Center for Development of Advanced Computing, which is part of the Ministry of Electronics and Information Technology in India, is a brand new licensee of the Neoverse V1 cores and will be designing a custom processor for the Indian exascale supercomputing effort. (You can’t be a nuclear power without one. . . . ) The details of the Indian chip design have not been divulged, but we expect that it will look a lot like Rhea and K-AB21, given the needs for lots of bandwidth and lots of memory capacity – and that all three organizations are willing to try this even if it does cause a more difficult programming model than the CPU only, HBM2 memory only approach of Fujitsu’s A64FX chip.
Some who have programmed “Knights Landing” processors, which had a mix of fast/skinny and slow/fat memories on a single compute element, say the Fujitsu approach is cleaner and easier, and adding an offload accelerator to the mix with its own high bandwidth memory and a need for cache coherence, will make it even more complex. But, it could work. We await the machines and their performance benchmarks on real workloads. None of that will take away from the fact that Arm cores have been chosen for the serial motors, which themselves have vector engines. The Indian effort said nothing about offload to an accelerator as far as we know, so this could simplify things somewhat.
The hyperscalers and cloud builders are increasingly taking a shining to Arm, as we noted above, and Bergey gave us a little more insight into what some of them are up to. We already wrote about Oracle taking a $40 million stake in Ampere Computing and rolling out two-socket servers based on the 80-core “Quicksilver” Altra processors, which are based on Neoverse N1 cores. Quicksilver instances will be available on the Oracle Cloud in the first half of 2021, according to Bergey. Earlier this year, Ampere Computing had been hinting there would be more design wins, and now we see that Tencent and Baidu are in the mix, and without saying whose chips they are using, we strongly suspect that the Arm server chips they are using are coming from Ampere Computing.

As you can see in the chart above, Tencent says the Arm chip that it has tested has 28 percent better performance – by which we presume it means throughput on thread-friendly work Java application services and databases – and 2X better performance per watt. These are big numbers.
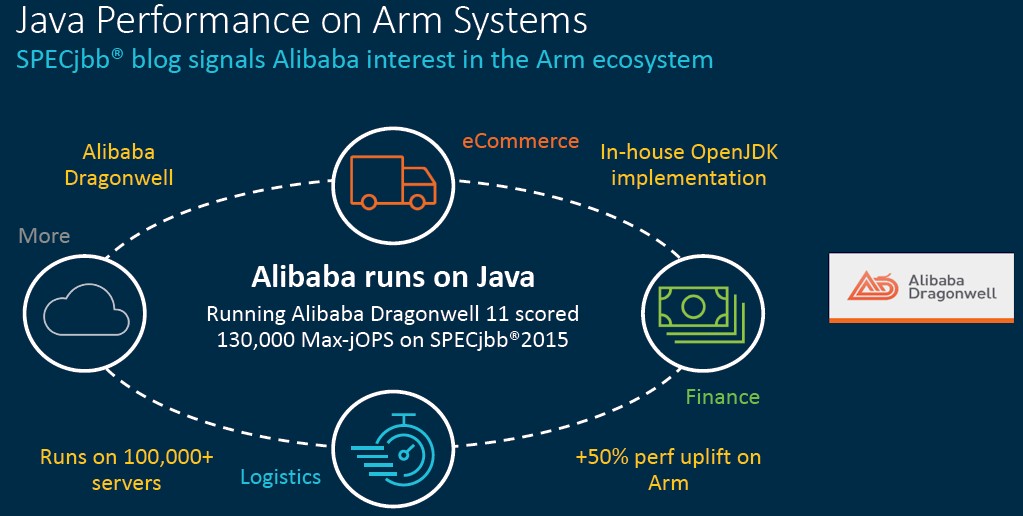
Alibaba, which runs its Dragonwell Java application server on over 100,000 servers and which has over 1 billion lines of Java code, had similarly nice things to say about Arm processors – and again we strongly suspect that Alibaba was using the Quicksilver chips from Ampere Computing – running Java. Take a gander:
But it is this chart that really captures the attention and the imagination, which shows the ramp of Graviton2 instances within AWS, from data gathered by Liftr Insights:
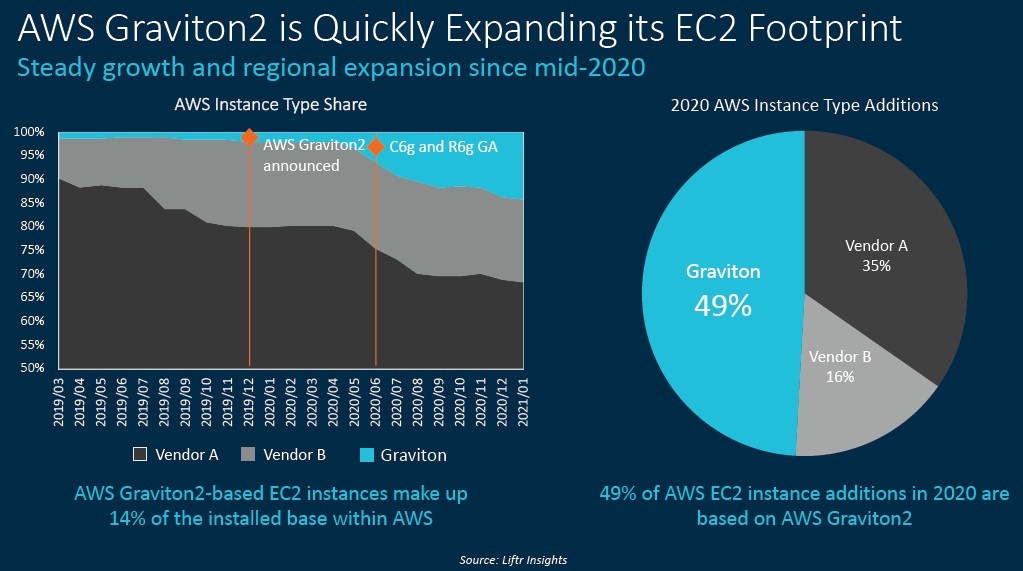
Bergey said that Graviton and Graviton2 instances are available in 70 of 77 availability zones in the AWS cloud, which is not too shabby for a product that has only been in the field for a short time.
You have to read the chart above very carefully. This is not an installed base count of compute capacity by core count or virtual machine count, which would be very useful indeed, but rather a count of all the instance types available from all of the AWS regions and their availability zones by instance type and location. To use an analogy, this is a menu of options, but not a count of how many dishes, by type, were sold. We would love to see the real installed base data — what people are actually eating — but we think that the instance type count is a leading indicator for the installed base count. If you see the menu shrink for beef, pork, or chicken, then you know which one is coming off the menu and which one is going to have more dishes and presumably drive more revenues.
All of this data is a leading indicator of sorts for the prospects of an Arm-ed insurrection in the datacenter. No one is foolish enough to put percent of server shipment stakes in the ground in 2021, as Arm Holdings did in 2011 and 2015 and 2016. But we think it will be non-zero and significant this time around.


Server Spending Holds Up Despite Every Damned Thing
Our increasingly networked and compute-intensive lives are driving the server business, and despite the cornucopia of fear, uncertainty, and doubt that spans the globe, the appetite for compute as expressed in shiny racks of servers or metal pizza boxes or an occasional tower sitting in a closet or under a …

Server Sales Boom In China, Bleed Air Elsewhere
The server market is a multi-cylinder engine, with eight major hyperscalers and cloud builders all doing their thing almost independently of each other and of the economic conditions at large and the rest of the market being more subject to the waxing and waning of the economic tides. In that …
The Beginning Of The Bottom For Intel’s Datacenter Business
Intel can talk all it wants about how it beat its own expectations or those of Wall Street, but the fact remains that the first quarter of 2023 was downright ugly for the chip designer and maker. You can’t polish it, and you can’t roll it in glitter. But Intel …
Why isn’t Apple mentioned in your article? I think Apple will be the number one player in ARM servers.