

One of the main tenets of the hyperscalers and cloud builders is that they buy what they can and they only build what they must. And if they are building something from scratch – be it flash controllers using FPGAs a decade and a half ago or custom Arm processors today – then they have to have a pretty damned good reason to do so.
The hyperscalers have a lot more leeway when it comes to building custom infrastructure because they control their own software stacks, top to bottom, and they generally provide their services for free so people can’t complain about levels of service too much. With the cloud builders, they have to create infrastructure that can run a wide variety of applications, generally on X86 iron and generally for either Linux or Windows Server as the operating system. As the cloud builders provide more high level functions and services that abstract away hardware, they can get away with more custom hardware and even do away with the X86 instruction set altogether.
Years ago, Microsoft made no secret about its desire to move at least half of its workloads to Arm-based computing platforms in the Azure cloud, importantly including various kinds of services like Office 365, where end users could care less what the underlying platform is. Microsoft seemed content to let one or two Arm chip suppliers emerge, and seemed to be behind Marvell’s ThunderX line and possibly behind the rise of Ampere Computing’s Altra line of chips, but is rumored to be working on its own devices – possibly for its Azure server fleet but also possibly to control its own destiny in game consoles, which are currently based on custom AMD X86 processors and GPUs and which were based on custom PowerPC chips and GPUs before that. Google has dabbled in Power platforms and knows plenty about the Arm architecture, but has not talked about any custom design efforts.
Amazon Web Services, on the other hand, has two different lines of Arm processors – the Nitro processors for its eponymous SmartNICs or DPUs that got the cloud computing giant into custom processors after its Annapurna Labs acquisition in January 2015, and the Graviton family of server processors that are distinct but related line of processors aimed at CPU compute. The current Graviton2 processors are based on the Neoverse “Ares” N1 cores, the designs of which were specified by Arm Holdings back in February 2019. The chips use the N1 cores and offer about 60 percent better performance per thread than processor designs based on the “Cosmos” Cortex-A72 cores that predate them; some of that is from core count increases enabled by the shrink from 16 nanometer to 7 nanometer processes, some of that is for big changes in the architecture, which we discussed at length here.
We are all eagerly awaiting designed based on the “Perseus” N2 and “Zeus” V1 cores and processor designs, which offer a different mix of integer, floating point, and vector performance but somewhere between 40 percent and 50 percent better single-threaded performance compared to the Ares N1 designs. The Zeus V1 designs were released for 7 nanometer chips last year by Arm Holdings, and Perseus N2 designs are expected sometime this year – we suspect here in March, if history is any guide. Then it takes about a year or so for chips based on these designs to get into the field, maybe less. We strongly suspect that Graviton3 processors based on either V1 or N2 cores (or perhaps both) will appear from AWS at its annual reinvent conference in early December.
But in the meantime, AWS is still rolling out new instances based on the Graviton2, which we detailed here. No one knows for sure what the clock speed is on these chips, but the Neoverse N1 design tops out at 3.5 GHz burning through a lot of watts, and we don’t think AWS is running them very fast at all now that they are in the field. In fact, we might have guessed a bit high at 3.2 GHz when we first wrote about Graviton2 and we think that the chips has a more balanced design and is running at a mere 2.5 GHz to deliver its performance across 64 cores that do not have simultaneous multithreading (SMT) like server CPUs from AMD, Intel, and IBM do. Ampere Computing is also not using SMT because it wants to have more deterministic performance out of its CPUs, and threads can’t always provide this even though they can boost throughput for machines by as much as 20 percent for certain workloads.
With the launch of the Graviton2-based X2gd instances this week, we got to thinking about the price/performance claims AWS has been making between its instances based on Intel’s Xeon SP and Xeon E7 processors and its own based on the Graviton2. When the R6g instances debuted with the Graviton2 processors back in March 2020, AMD said they offered up to 40 percent better price/performance than the R5 instances based on a mix of “Skylake” Xeon SP-8000 or “Cascade Lake” Xeon SP-8000 processors. And with the much fatter memory offered on the X2gd instances coming out this week based on single-socket Graviton2 processors, AWS says that it can deliver 55 percent better bang for the buck compared to the X1 and X1e instances based on Intel’s Xeon E7-8880 processors.
What AWS is not doing, however, is giving EC2 Compute Unit, or ECU, relative performance metrics that allow customers to compare instance types and sizes in terms of their raw compute. And that makes it a hassle to do comparisons – and intentionally so because the architecture of the Graviton2 chip is quite a bit different from that of the Xeon SP or Xeon E7. (The in-band, always-on memory encryption on the Graviton2 is neat and doesn’t affect performance for integer or floating point operations.) But to make those price/performance claims, AWS has to be ginning up an ECU figure – or something that looks like it – for the Graviton2 instances. And so, we worked it backwards on the comparisons that AWS is making between its two specific Graviton2 instances and the Xeon instances it is comparing to. We assumed at AWS was taking the top bins of each instance type to make its comparisons and then scaled the performance down across the sizes of the Graviton2 instances and then calculated the price/performance for each instance based on renting it using an On Demand price for three years.
We realize that this is not how someone would buy such an instance – this is just about getting a price/performance figure that does not run out to six decimal places, which is not a human scale number. Obviously, reserved instances and spot instances still come into play for any AWS instance to reduce the price per hour of using it, but the relative bang for the buck does not change. (We believe that, at least.)
At the moment, the Graviton2 processors are available in a number of different instance types: General Purpose (M6g and M6gd), Compute-Optimized (C6g, C6gn, and C6gd), Memory-Optimized (R6g and R6gd), and Burstable (T4g) instances, plus the new Large Memory (X2gd) instances that debuted this week. These X2gd instances are aimed at the same workloads as the large memory instances AWS created using multiple-socket Xeon E7 instances, which includes in-memory databases and datastores (think Redis and Memcached and possibly Spark and even SAP-HANA) as well as relational databases that like big memory and a reasonably large number of threads to chew on. You are, of course, limited to the open source databases that support the Arm architecture, and we strongly suspect that Microsoft will do a production-grade SQL Server at some point and Oracle, which has more than a passing interest in Arm processors for the same reason as AWS, will probably go there, too. That covers three-fourths of the commercial relational database market. AWS says these fat memory instances, whether they are based on Graviton2 or Xeon E7 processors, are also good for chip design and verification, real-time analytics, caching services, and fat container environments.
The X2gd instances have a single processor with up to 64 virtual CPUs and can address up to 1 TB of memory and two 1.9 TB NVM-Express flash drives. The network bandwidth attached to the instances maxxes out at 25 Gb/sec and the Elastic Block Storage tops out at 19 Gb/sec. The smaller instances are slices of this machine managed by the Nitro DPU, which virtualizes security, network access, and storage access. Here is how these new Graviton2 instances stack up to the fat memory instances based on the Xeon E7s:
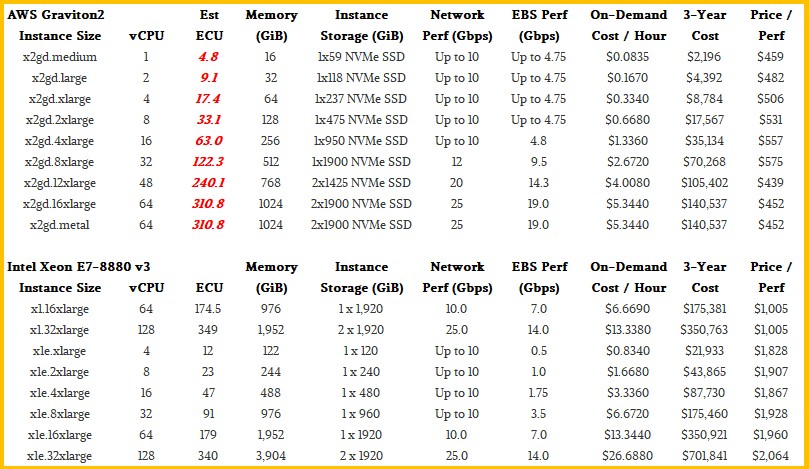
First of all, those Xeon E7-8880 processors, which are the “Haswell” generation of server CPUs from Intel, are now six years old and are very long in the tooth. AWS has long since paid for these and is just minting money as customers use them. These four-socket servers are based on 18-core, 36-thread CPUs, and only a maximum of 128 threads are exposed because, we guess, some of that CPU oomph is used to deal with the hypervisor and virtual switch and storage – things that the Nitro DPUs now handle. That 4 TB memory footprint is just 1 TB per socket, such like the Graviton2 socket tops out at. The Graviton has eight memory channels per socket, and with two DIMMs per channel that works out to 128 GB memory sticks in the server instance. If AWS used fatter memory sticks weighing in at 256 GB each, it could push up to 2 TB of memory in the top bin of the X2gd instance, but this would be very pricey indeed.
To get a bigger memory bandwidth and memory capacity footprint, AWS might have to resort to using the CCIX interconnect that is inherent in the Neoverse designs to offer NUMA configurations. In that case, AWS could build a Graviton3 server with four sockets that had four times as many memory slots and therefore four times the memory bandwidth as well as four times the cores in a single instance. Or, it could get the memory ratios higher, perhaps using 32-core Graviton3 chips in a four-way machine that used 128 GB memory sticks to deliver a total of 4 TB of memory across 128 vCPUs (which in this case is a core since the Graviton chips don’t do threading).
What is funny to us is that the fat memory nodes at AWS are so long in the tooth. AWS does have fatter nodes based on eight-socket “Skylake” Xeon SP-8176M processors or a follow-on “Cascade Lake” version deliver up to 224 cores and 448 vCPUs with anywhere from 6 TB to 24 TB of main memory. These are aimed at SAP HANA and are very pricey indeed.
The R6g instances, which AWS has compared to the R5 Xeon SP instances in the past, is perhaps a better comparison for mainstream workloads. Take a look:
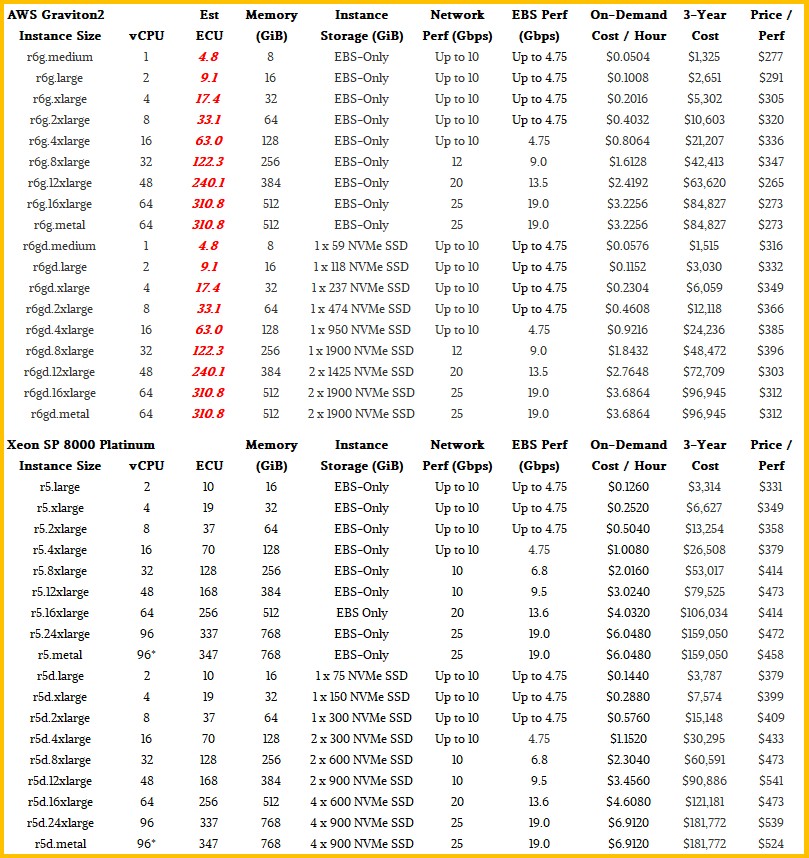
This table gives the performance of R6g configurations that meet that 40 percent better price/performance that AWS has been talking about versus the R5 instances. Not every comparison yields a 40 percent better bang for the buck. So, for instance, if you compared the r6g.large instance which has two vCPUs and 16 GB of memory to the r5.large instance with the same two vCPUs and 16 GB of memory, the Graviton2 setup only yields 12.3 percent more bang for the buck, and the 32 vCPU setups with 256 GB of memory offer only 16.3 percent more value for the dollar. So AWS is providing more value to customers who take bigger and bigger slices of the machine, which makes sense. You want to keep the machines as busy as possible and get the payback sooner.
As far as we can tell, the relative performance is the same whether the instances use EBS or have local NVM-Express storage (as long as you compare similar storage configurations).
What we don’t know is how much the Graviton2 chip costs for AWS to develop and have manufactured, and for all we know, the fully burdened cost for a 64-core Graviton2 is actually higher than what it has already paid Intel for an equivalent 64-thread “Ice Lake” server chip. But having control of the features within and cadence of server CPUs is important to AWS, and that is worth something, too. So is bragging rights about being the dominant Arm server chip maker and system seller. So is being able to leverage Graviton2 to get better pricing out of Intel and AMD for their X86 server CPUs. All of these are benefits that offset the costs of having the Graviton program in the first place.
Given the nature of cloud computing today, the percent of applications that can – and will – move to Arm architectures now and in the future, the advent of serverless computing and high level functions, and the increasing high level software services that AWS supplies – database services, storage services, etc – it is not unreasonable to think that in the near term – say over the next few years – Arm-based machines could account for 25 percent of the AWS server fleet. And if AMD and Intel don’t get deeper into a price war on the X86 front and try to carve up their portions, even more of the AWS fleet could move – and move more quickly – to Arm CPUs. AWS is already making a Nitro Arm CPU for every server, after all. It ain’t no big D for a bunch of single-socket instances to be pushed out into the fleet to do whatever database and storage and AI and even HPC workloads where a CPU is necessary. Add NUMA extensions with Graviton3 and even more of the market is addressable.
In the end, the only X86 processors out there on EC2 could be those supporting an aging base of legacy Windows and Linux applications that are not ported to Arm. And that, too, will make AWS huge piles of money because you can charge prices from the past on applications stuck in the past. That’s the way it has always been, and that is not going to change.


Ampere’s IPO Filing Signals More Arm Cash And More Arm Scrutiny
There is a likelihood that we could see both British chip designer Arm Holdings and one of its server-focused startup adherents, Ampere Computing, go public this year, as indicated by recent rumors of the first and news from Ampere itself this morning that it has confidentially filed for an initial …
Gigabyte Spins Off Server Division To Chase Datacenter Business
Gigabyte Technology’s enterprise server division has been spun off under a new logo: Giga Computing. While perhaps best known for its enthusiast, workstation, and gaming motherboard and graphics products, Gigabyte is no stranger to the server and datacenter arena. Alongside consumer-focused boards, Gigabyte also operates as an original design manufacturer …
Money Changes Everything For SiPearl
If you think designing a new CPU from scratch is hard, you ought to try raising money to do it. Even when there is a political and economic will to do so, as is the case with the European Processor Initiative, it has still taken longer for Silicon Pearl, the …
“No one knows for sure what the clock speed is on these chips”
Huh? It’s been known to be 2.5GHz for quite a while now. Not particularly difficult to measure yourself, even.
You don’t even have to guess, AWS publishes it for every instance types, there’s even an API for that:
aws ec2 describe-instance-types | jq ‘.InstanceTypes[] | {InstanceType: .InstanceType, ClockSpeed: .ProcessorInfo.SustainedClockSpeedInGhz}’
The Ampere Computing processor family is called Altra, not Alta.