
It is not a coincidence that the companies that got the most “Hopper” H100 allocations from Nvidia in 2023 were also the hyperscalers and cloud builders, who in many cases wear both hats and who are as interested in renting out their GPU capacity for others to build AI models as they are in innovating in the development of large language models.
Nvidia is obviously very keen on milking the generative AI wave for every last dollar before competition starts picking away at its near monopoly with respect to accelerated computing for LLMs. We think both this wave and Nvidia’s ability to steer its ship through it are bigger than anyone had expected in the summer of 2022 when OpenAI’s ChatGPT launched as an API and transformed the nature of computing in the datacenter.
But the money pot at the end of the GenAI rainbow doesn’t end with Nvidia. It just keeps multiplying as the capacity on these GPUs are rented out and tens of thousands of enterprises are trying to get GPU clock cycles to train their own models and, it is hoped, transform their businesses. This includes the massive GPU complexes created by Microsoft Azure (150K), Meta Platforms (150K), Amazon Web Services (50K), Google Cloud (50K), Oracle Cloud Infrastructure (50K), Tencent (50K), Baidu (30K), and Alibaba (25K), which are ranked there by their Nvidia H100 allocations according to data from Omdia, but it also incudes pure GPU cloud players like CoreWeave (40K) and Lambda (20K). And then two wild cards, ByteDance (20K) and Tesla (15K), which are their own thing and which are doing their own LLMs.
For the purposes of this analysis, CoreWeave and Lambda (formerly known as Lambda Labs), are the interesting ones because they are making a lot of noise about GPU allocations and how they are raising venture capital. They also have Wall Street hoping for two big initial public offerings either this year or next.
We understand all the buzz, but we doubt Wall Street has done the math all the way through on this. We leave it to you to reckon if the valuations on these pre-IPO companies make any sense. We think the entirety of the world’s stock markets are overvalued based on the fundamentals, and have been increasingly so over the decades. But we don’t let that cloud our analysis, because value is a relative, not an absolute, metric. Anyone with a 401(k) needs this hot air to be real. (Wait, that includes us, too.)
Let’s have some fun. We have been saving this fascinating chart, which was buried in the same October 2023 financial report that included Nvidia’s roadmap and which we edited to make it more accurate, for a good occasion. It explains how the economics of this GPU racket works, at least from the point of view of Nvidia’s top brass:

The left pie chart is easy enough to understand. If you want to be a GPU cloud player, start with $1 billion. With that, you can buy AI servers with an aggregate of 16,000 H100s for what looks like $400 million, and you spend another $100 million for Nvidia’s InfiniBand networking to link them all together. You spend another $500 million to build a datacenter and operate, power, and cool it over those four years. Nvidia did not depreciate the cost of the datacenter or the iron inside of it, but you obviously do that.
We don’t know where Nvidia came up with that GPU compute price, but at somewhere around $400,000 a pop minimum for a configured GPU server that is a clone of the eight-way DGX H100 from Nvidia, that’s 2,000 servers and that is a cost of $800 million – not $400 million. We do not think the hyperscalers and cloud builders are getting a 50 percent discount given the exorbitant demand for H100s.
Now, you move to the right side. Nvidia says that the rental opportunity at $4 per GPU-hour over the course of four years is around $2.5 billion. We have to do a certain amount of witchcraft to get that number to work out, which we will explain.
First, if you just take 16,000 GPUs and multiply by $4 per hour over four years (at 365.25 days per year and 24 hours in a day), then you get a rental revenue stream of $2.24 billion. Not $2.5 billion. The pie chart on the right seems to imply that by using the more expensive InfiniBand networking rather than Ethernet, you can increase the utilization of the GPUs by 15 percent, which is worth $350 million over four years and increase the throughput of the GPU cluster by 25 percent, which is worth $600 million. If you assume that aggregate 43.8 percent performance improvement means you only need 11,130 H100 GPUs instead of 16,000, and you multiply out the cost at $4 per GPU-hour over four years over 11,130 GPUs, then you get $2.51 billion in rental income if you add $950 million in value to the revenue stream from the GPUs. (We are not saying that is what Nvidia did, but maybe?)
Ah, but wait, we know from analyzing p5 GPU instance pricing from Amazon Web Services, which we did in detail last July, that the on-demand instance price for an eight-way H100 system instance was $98.32 per hour, or $12.29 per GPU-hour. We estimated the one year reserved instance cost $57.63 per hour, or $7.20 per GPU-hour, and we know that the published price for the three year reserved instance is $43.16, or $5.40 per GPU-hour.
We think the GPU rent doesn’t change because of the performance improvement or the utilization improvement that comes with using InfiniBand. (We know AWS is not using InfiniBand for these p5 instances, but rather its own EFAv2 implementation of 400 Gb/sec Ethernet.) So here is the deal: If you have 16,000 GPUs, and you have a blended average of on-demand (50 percent), one year (30 percent), and three year (20 percent) instances, then that works out to $5.27 billion in GPU rental income over four years with an average cost of $9.40 per hour for the H100 GPUs. The increased efficiency of using InfiniBand means a cloud could get more customers through those GPUs faster, but it doesn’t change the per hour rental costs. It just means customers finish quicker and more customers can use it, but there are only 35,064 hours in a year with 365.25 days across those four years.
So here is how we would edit the chart that Nvidia put together, assuming a more accurate price for H100 GPUs and an upgrade to 800 Gb/sec InfiniBand and more accurate pricing on a mix of p5 instance terms on AWS:
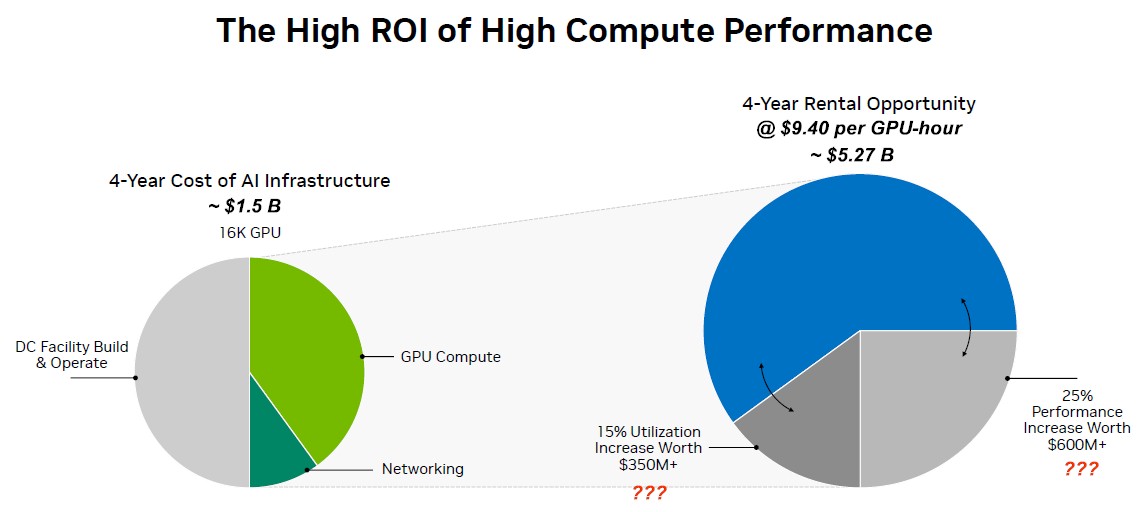
Here is what you need to know, Wall Street: You put $800 of investment in for Nvidia GPUs, another $700 for a datacenter and networking, and you get $5,270 in revenue back out again if you have a reasonable mix of on-demand and reserved instance customers.
We do not think the numbers will be all that different across the AWS, Microsoft Azure, and Google Cloud infrastructure, and we doubt in the final analysis that they will be much lower on the GPU price (and therefore revenue) from the likes of CoreWeave or Lambda so long as GPUs are scarce.
Some food for thought: It is always cheaper to rent a smaller number of GPUs for a long time than a larger number of GPUs for a short time, and this has to be juxtaposed against the GPU memory capacity and the GPU memory bandwidth needs of any given size of LLM. Customers might need a large number of GPUs for the memory, not the compute, but they are charged for the compute anyway.
It is with all of this in mind that we consider recent investments in CoreWeave and Lambda.
CoreWeave, which was a bitcoin mining company founded in the New York City suburb of Roseland, New Jersey and which has pivoted to AI processing, announced today that it had received $1.1 billion in Series C financing from Coatue with participation from Magnetar (which led the Series B funding round) as well as Altimeter Capital, Fidelity Management, and Lykos Global Management. That Series B round in December 2023 came to $642 million, which followed a Series A round that raked in $420 million in April 2023. In August last year, CoreWeave also got $2.3 billion in debt financing from Magnetar and Blackstone. This funding is what has allowed CoreWeave to go from three datacenters to fourteen datacenters in the past year. That is $2.16 billion in venture funding and $2.3 billion in loans for a total of $4.46 billion. That sounds like a lot until you realize that this represents the cost for datacenters and GPU systems that have around 47,600 GPUs in total. That used to sound like a lot.
But here’s the fun bit. If you run that number of GPUs through our comparison above, you get $15.68 billion in rental income over four years. So, $4.46 billion in, and $15.68 billion back as revenue.
Assuming that CoreWeave is good enough to get the same 65 percent to 70 percent operating income out of its infrastructure as we think AWS can with its GPU instances over the years, and then pay for sales, marketing, and other stuff, this might be a pretty good business to invest in. And what seems clear is that when it comes to GPU allocations, the size and the speed of the organization matters a lot to Nvidia, which wants to get GPU cycles into the hands of people as quickly as possible to spread the Jensen Way far and wide.
CoreWeave figured out it can be a niche player, but that it has to go big to compete with the hyperscalers and largest cloud builders, which have much larger GPU fleets and will continue to do so. You have to judge for yourself if the tripling of CoreWeave’s valuation by the venture capitalists, which has tripled since its last funding round to $19 billion with the current round, makes sense. There is another equation: $4.46 billion in, $19 billion or more IPO out. CoreWeave founders get rich, and everyone has a different way to catch the Nvidia Wave.
Lambda is going to have to play catchup here. Last December, Lambda got a $320 million infusion, and has raised a total of $932.2 million in funding across pre-seed, seed, venture rounds, and debt financing between 2017 and 2023. Lambda started out as a cloud serving AI workloads, shifted to become an AI system maker, and is now focusing more on being a GPU cloud.
Once again: Both CoreWeave and Lambda are saying they can provide GPU access for less money than the big clouds, but that only hurts their cause if you think about it. With GPU capacity scarce, they should try to charge as much as AWS until they can’t, or the price of AWS minus all of the value that comes from SageMaker and Bedrock. You don’t see AMD giving away its MI300 GPUs, after all; it is charging around the same per unit of compute and unit of memory as what Nvidia is charging for H100s and H200s. And there is no reason for clouds to give away their GPU capacity for less than AWS sells it – at least not yet. When there is a glut of GPU capacity, that will be a different story – and when the HPC centers of the world will be able to swoop in and get a lot of science done on the cheap. Perhaps.


AWS Goes Wide And Deep With Graviton3 Server Chip
It is always an exciting time when there is a new compute engine coming into the market, and interest is particularly keen with any new Arm server chip entry. At this point, Amazon Web Services is by far the biggest consumer of Arm-based server processors in the world, with its …

The World Will Eat $2 Trillion In AI Servers, AI Will Eat The World Right Back
Every time Lisa Su, chief executive officer at AMD, announces a new Instinct GPU accelerator, the addressable market for AI acceleration in the datacenter seems to expand. But, we observe, the growth rate in the AI datacenter accelerator forecast has slowed even as the ramp rate for AMD and Nvidia …
China Launches The Inevitable Indigenous GPU
It was absolutely inevitable that China would try to create its own GPU compute engines. It was never a given that it would succeed in only three years. But with the launch of the BR series of products from Biren Technology, there is finally a credible homegrown GPU controlled by …
Extremely good analysis! I wish I had done it!
Since the supplies of GPUs are limited, could renting time be similar to buying scalped tickets to a Taylor Swift concert? I see two possible outcomes: GPUs rapidly become more available at lower cost; Swift forbids scalping tickets.
That’s part of it. But the fun bit is Nvidia has, at worst, something like 85 percent operating margins on its datacenter GPUs and then the cloud builders can still extract 65 percent to 70 percent operating margins on top of that by selling them as a service. Look at all that margin! And there are Taylor Swift effects driving this at both the Nvidia and the cloud levels for sure. If the competitors could get supply and make their devices so cheaply — there is a reason why the B100 is not very different packaging wise from the H100 and the H100 is not very different from the A100 really except some modest cranks — they would be putting competitive pressure on Nvidia. But the market is expanding so fast that Nvidia feels no pressure. Like Intel in CPUs in 2018 through 2020, even as AMD brought increasing heat. But since 2021, has Intel ever been feeling it.
So when all this comes crashing down, which it will, we can expect GPU rental costs to fall by a factor of four right? Or even more? And those revenue numbers seem optimistic to me… who really needs this much GPU time for AI? Now for HPC and science… sure!
This is a reasonable set of assumptions as far as I can see. Or, the hyper just goes on for three years….
1.21 GigaWatts:: Enough power for?: A circa 2025 data center full of Nvidia B100’s || Energize a flux capacitor // Dr Brown conundrum. Yeah that data center wants continuous power. Hmmm.
Every single analysis I have seen focuses on supply and assumes there is an ROI for people spending money in training and other AI activities. No letex extrapolate this funny marh to the expected 50b of nvdiia GPU system sales and add another 10b for TPU, AMD MI series etc. Based on your math, somehow this 60b of GPUs will generate $420b of revenue (since 800m of H100s are projected to generate $5B+). Do you see the absurdity? Total revenue from the applications layer (openai, anthropic, Microsoft office copilot) etc is less than $10b and even if it doubles every year for the next 3 years it will be at $80b far short of the $400b needed to even support the current level of capex…
Oh, I see the absurdity alright. But Google and Meta — and AWS and Microsoft to a lesser extent — are using this iron to drive ad revenues or search revenues already. Google search has had AI behind it for many years, for instance. Microsoft is the most hopeful of them all, clearly. Some of these GPUs — maybe half of the H100s — are being used to drive the quest for AGI, which is more like HPC for its own sake and is something closer to R&D. The idea, I think, is replacing $1 trillion or so in annual people costs with $500 billion in AI system costs that is amortized over, what?, five years? That is 10X savings. Until you realize now there is $1 trillion in spending that will go missing, with obvious network effects rippling through the economies of the world. And the answer? More AI! And so on, and so on. So yeah, I see the absurdity of it all, Alex.