

When it comes to machine learning, a lot of the attention in the past six years has focused on the training of neural networks and how the GPU accelerator radically improved the accuracy of networks, thanks to its large memory bandwidth and parallel compute capacity relative to CPUs. Now, the nascent machine learning industry – and it most surely is an industry – is becoming more balanced and has an increasing focus on inference, the act of using those trained models on new data to do something useful with it.
Nvidia is no stranger to inference, of course, even if it has created the dominant platform on which machine learning training is done today. If you train a neural network, you have to run new data against it so there is always inference going on.
Nvidia’s first real pass at an inference engine based on GPUs was the Tesla M4, based on the “Maxwell” GM106 GPU, sporting mostly single precision floating point math, and its companion, the Tesla M40, based on the GM204 GPU aimed at machine learning training but not having any double precision oomph to speak of, either. These two devices came out in November 2015, when neural nets were far less complicated. The Tesla M4 could do 2.2 teraflops at single precision and came in versions with 50 watt or 75 watt thermal envelopes. The Tesla M4 had 1,024 CUDA cores and 8 GB of GDDR5 frame buffer memory that delivered 88 GB/sec of memory bandwidth. That was a lot less memory than a Xeon CPU, but as much memory bandwidth as a typical two-socket Xeon system could deliver at the time and enough parallel compute to beat that X86 system, too, on inference work. But the Xeon servers were already in datacenters, and companies largely kept inference on them.
Two years ago, when Nvidia launched the Tesla P4 and P40 accelerators aimed mostly at machine learning inference, it put a stake in the ground and made a more earnest foray into this part of the market, and at that time we coined something called Buck’s Law, which posited that every bit of data created in the world would require a gigaflops of compute over its lifetime. That ratio was meant to be illustrative, not precise, and it came from Ian Buck, vice president and general manager of the Tesla datacenter business unit at Nvidia. That statement includes all kinds of workloads and is not limited to machine learning training and inference. Nvidia has done a remarkable job architecting its Tesla hardware and CUDA software for GPU compute to take on HPC and AI workloads, and is expanding into other areas such as GPU accelerated databases, just to name a big one, along with the traditional virtual desktop and virtual workstation segments that are also powered in part by GPUs. The point is, there is a lot of chewing on data. It doesn’t just sit there, at least not at the companies that want to stay in business in the 21st century.
Inference engines are being embedded in all kinds of things because machine learning is now part of the application stack. This all started with the hyperscalers, who had enough data to make machine learning work and because of GPUs because they had enough memory bandwidth and parallel compute to make the machine learning training algorithms work. Facebook has over 1 billion videos viewed per day, driven by machine learning recommendation engines and search engines, and there are over 1 billion searches driven by speech recognition per day across Google and Bing. Page views and searches drive over 1 trillion advertising impressions per day. (Thank you for contributing some by reading this story. Nicole and I appreciate you.) Microsoft is one of the hyperscalers that has gone public admitting that it is using GPUs to accelerate visual search on its Bing search engine.
The Tesla P4 accelerators from two years ago took GPU inferencing up a notch, with 2,560 cores in that same 50 watt and 75 watt envelope, delivering 5.5 teraflops at single precision and 22 teraops using a new INT8 eight-bit integer format that the machine learning industry had cooked up. The Tesla P4 had 8 GB of GDDR5 memory and delivered more than twice the memory bandwidth to balance the more than twice the compute at 192 GB/sec.
The Tesla P4 accelerator was a decent device for inference, and it has been adopted for a number of workloads. Buck was not at liberty to talk about actual revenues for the inference business in general, or the Tesla P4 in particular, but he did share with The Next Platform a breakdown of revenues by inference job type:
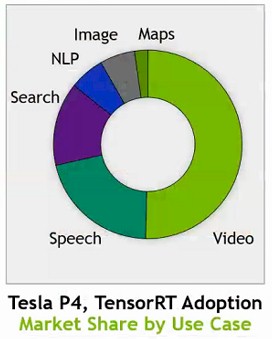
At the moment, video recognition inferencing is driving half the business, and speech processing is about a quarter. Search is a big piece, too. This pie chart will no doubt change over time. Buck did add that the Tesla inference revenue stream has become “a material part of the business.”
The Tesla T4 accelerator, announced today at the GPU Technical Conference in Japan, is shifting GPU inference up another gear. Nvidia has to do this if it wants to capture more of this part of the market before others move in on this rich turf.
Follow The Inference Money
The machine learning software stack is changing fast. Chip makers – and there are a lot of them chasing the inference opportunity – have to turn on a dime to try to capture that opportunity, which Buck says represents a $20 billion market over the next five years. (Presumably that means five years from now, machine learning inference will drive $20 billion in infrastructure sales, not just chip sales relating to infrastructure.) The point is, two years ago, as Intel has contended, 95 percent of machine learning inference was done on X86 servers, not with accelerators or other kinds of processors, and was just another job running on plain vanilla machines. But the vast amount of data that needs to be inferred so it can be labeled and used to provide a service is requiring that systems – whether they are in our smartphones, on the edge of the network, or in datacenters that run the applications we use – do inference much more efficiently. FPGAs are in on the act here, too, and so are a number of specialized ASICs – Graphcore is the big one, and Wave Computing is doing interesting things, too. Brainchip is a taking a slightly different tack with a spiking neural network approach.
The Tesla T4 is based on the “Turing” GPU architecture, which was unveiled earlier this summer for GeForce RTX and Quadro RTX cards that do dynamic ray tracing enhanced by machine learning algorithms. Like the “Volta” GV100 GPUs aimed at HPC and machine learning training, the Turing GT104 GPUs used in the Tesla T4 accelerators are etched by Taiwan Semiconductor Manufacturing Corp using its 12 nanometer manufacturing processes. It has a whopping 13.6 billion transistors, and that is close to the 15.3 billion transistors in the Pascal GP100 GPU but still a bit behind the 21.1 billion transistors in the GV100 GPUs. Here is a die shot on the GT104 GPU:

The GT104 chip has dedicated RT cores to perform ray tracing, which are not interesting when it comes to inference, even if the converse – the inference engines are useful for ray tracing – is true. The chip on the Tesla T4 card has 2,560 CUDA cores, which have 32-bit single precision and 16-bit half precision floating point math units (FP32 and FP16) as well as 8-bit and 4-bit integer math units (INT8 and INT4). The FP64 math units on the Volta GV100 are not in the Turing architecture, but if you really wanted to do machine learning training on this card and it did not have a framework that required FP64, then Buck says it would work – but that is not the design point of this device, which has limited memory capacity and bandwidth. To be specific, the Tesla T4 card has 16 GB of GDDR6 frame buffer memory for compute, and delivers 320 GB/sec of memory bandwidth into and out of it. The GT104 GPU also has 320 Tensor Cores, which can be used to do the funky matrix math sometimes used in machine learning codes. (The Tensor Cores handle 4x4x4 matrices with FP16 input and FP32 output, all in a single go.)
This is a lot less stuff than is crammed into the Volta GV100 GPU, which in the etching has 5,376 32-bit integer cores, 5,376 32-bit floating point cores, 2,688 64-bit cores, 672 Tensor Cores, and 336 texture units across 84 streaming multiprocessors (SMs). In the production GV100s, only 80 of the 84 SMs are activated, which helps more chips get out the door as TSMC ramps its 12 nanometer processes. (It would be very hard to get a perfect chip with all 84 SMs working.) The GT104 GPU is different in that it is supporting the INT8 and INT4 formats tensor core units, which has the effect of doubling or quadrupling the amount of data (albeit at a lower resolution) in the GPU memory compared and effectively doubling or quadrupling the processing throughput of the integer units. Here is how the peak relative performance of the Tesla P4 and T4 accelerators stack up on inference work, depending on the bitness of the data and the processing:
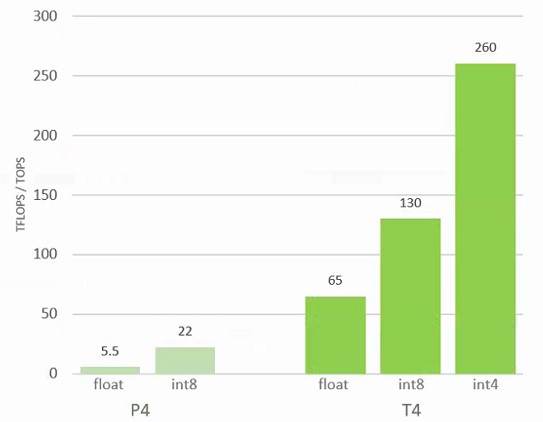
“We have taken the Volta Tensor Core and evolved it in the Turing chip specifically for inferencing,” Buck tells The Next Platform. “The base performance in FP16 can be doubled if it moves to INT8, and we have software optimized to take advantage of that. You can double it again by moving to INT4. We have some researchers who have published work that even with only four bits they can maintain high accuracy with extreme small, efficient, and fast models. You could even go to INT1, but that is pretty advanced stuff and still a research topic.”
Forgive us, but INT2 and INT1 sound like some pretty fuzzy data. But then again, look at how people remember the world. Maybe not.
With machine learning being embedded in the stack, and human beings being impatient, latency is what matters most, and adding GPUs to the inferencing stack, Nvidia contends, can radically reduce the time it takes to infer in its many guides to drive modern applications. Microsoft saw a 60X reduction in latency on visual search by moving to GPUs to accelerate the video recognition algorithms compared to the CPU-only methods it had used previously. Startup Valossa, which does live video analysis to try to infer the mood that people are in, saw a 12X faster inference rate. SAP, which has software to do brand impact analysis that looks for company logos in media, showing how long they were on screen, how big they were, and so on, moved to GPUs for inference and saw a factor of 40X higher performance.
The issue is not just latency on one inferencing workload, either. Many workloads have many different frameworks to support and many styles of inference using models from different neural networks that need to be done.
To illustrate the point, Buck pulled out the example of a voice search driven from a smartphone back to a hyperscale search engine, and how painful this is to do on a CPU. In this case, you have to run automatic speech recognition, and this one used the DeepSpeech2 neural network from Baidu. This takes about 1,000 milliseconds to process the sentence “Where is the best ramen shop nearby?” Next, the application has to understand the context of the search request, and that takes natural language processing; Nvidia chose the GNMT neural network from Google, and that took a mere 35 milliseconds to process. Then the output of the GNMT has to be passed to a recommendation engine, in this case Deep Recommender was chosen, and that took 800 milliseconds to run. The output from the recommender system is now passed to a text to speech generator, in this case Wavenet from DeepMind (now part of Google), and this took another 159 milliseconds. Add it all up, and that is 1,994 milliseconds. Call it two seconds – and in a world that after 200 milliseconds, people get impatient and go to another site.
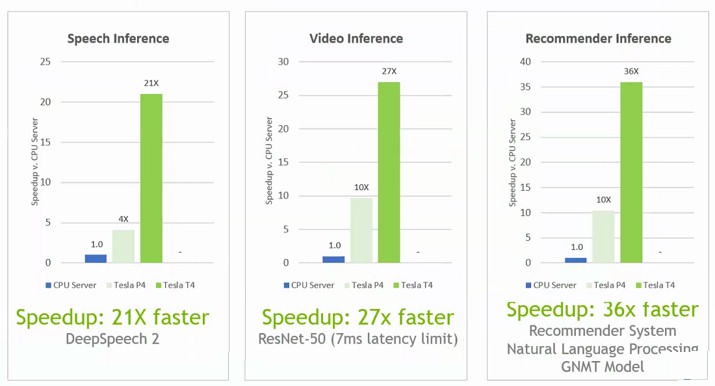
Inference needs to be faster if it is to be effective, and it needs to be cheaper if it is to be pervasive on GPUs. Here is how Nvidia stacks up the Tesla P4 and T4 accelerators against a server using a pair of Intel’s 18-core Xeon SP-6140 Gold processors, which run at 2.3 GHz and which cost about $2,450 a pop. The Tesla T4 smokes the pair of Xeons, and makes the tesla P4 look pretty bad, too. Nvidia doesn’t give out pricing on its Tesla units, but as far as we know, the Tesla P4 costs around $3,000 on the street. So if a Tesla T4 costs around the same amount and does somewhere between 21X and 36X more inferring than a pair of Xeon SP processors that cost $5,000, that is a factor of 35X to 60X improvement in price/performance on the inference engine, Tesla T4 versus a pair of Xeon SPs. Intel has processors with more cores, but their price rises faster than their performance, so that hurts the bang for the buck – it doesn’t help it.
The Tesla T4 will be available in the fourth quarter, and Google has said it will get the devices out on its Cloud Platform public cloud, just as it has done with the prior generation of Tesla P4 accelerators, determined to be the first. It will be fascinating to see how a rack of Tesla T4s stack up to rack of Google TPU 3 accelerators for inferencing work.




Be the first to comment