

No one knows for sure how pervasive deep learning and artificial intelligence are in the aggregate across all of the datacenters in the world, but what we do know is that the use of these techniques is growing and could represent a big chunk of the processing that gets done every millisecond of every day.
We spend a lot of time thinking about such things, and as Nvidia was getting ready to launch its new Tesla P4 and P40 GPU accelerator cards, we asked Ian Buck, vice president of accelerated computing at Nvidia just how much computing could be devoted to the broad category of deep learning and AI. In essence, what Buck said is that data will move from just being stored to always being processed in some fashion, and this has implications for the Tesla business that Nvidia is building out and others are competing against with other technologies.
“I don’t have a numerical answer for you, but I think that with every piece of data that companies collect and operate with, they are going to want to do computing on,” Buck tells The Next Platform. “I will say that each piece of data will require a gigaflops of computation over the long term. AI is transforming the way people are building datacenters. In the past, companies used MapReduce styles of operation, at best, but there you are not compute limited, you are just I/O limited – it is all about the disk and networking that you have got and you do a MapReduce. Now, each element of data that companies were doing MapReduce on is going to need a gigaflops of computation. That is my CEO math on that, and that is how I think about it and that is what we see trending. The trend is obviously going to take a while – enterprises have to figure out how to use AI, and we have to get access to deep learning into all of these companies, either through cloud services or in-house.”
Call it Buck’s Law, then: Every bit of data created will require a gigaflops of compute over its lifetime. And the heavy thing about that thought is just how many zettabytes are being created and passed around the world.
With that as a backdrop, it is no wonder that Nvidia has created specialized versions of its Tesla GPU accelerators for both the training of the neural networks that are the preferred method of deep learning these days for all kinds of workloads (identifying images, video, speech, and text and converting information from one format to the other are the major jobs thus far, along with recommendation engines and email spam filtering, but others will come) and for running trained models against new data, which is called inference. These training and inference jobs are not only different from other kinds of modeling and simulation used in the HPC community where Tesla got its start a decade ago as a compute engine; they are also unique from each other and require different features and software to run optimally.
As readers of The Next Platform know, deep learning is an inherently statistical kind of data processing and as it turns out, having more data trumps having precision in that data when it comes to identifying objects in photos or videos or converting from one language to another, just to call out two use cases of this technique. Deep learning researchers pushed the envelope at first by using 32-bit data and single precision floating point operations, which allowed them to cram twice as much data into the frame buffer memory of GPUs and get effectively twice as much memory bandwidth out of the devices, and thanks to the algorithms created with the neural network training code, having more data that is less precise yield better results than having half as much data that was more precise. With the “Pascal” Tesla GP100 GPUs, Nvidia added half precision FP16 instructions, basically allowing the GPU to be quad-pumped with 16-bit data and doubling up the dataset size and effective memory bandwidth again. This has been a boon for the performance of machine learning training, as has been the integration of HBM memory on the GPU package and the addition of NVLink for tightly coupling multiple Tesla compute engines to each other.
As it turns out, the performance of the inference side of the machine learning stack can be pushed even further, and AI researchers have been perfecting ways of using 8-bit integer processing for the inference engines that chew on new data as it comes in. So the Pascal GPU variants that are aimed at machine learning – specifically the Tesla P4 and Tesla P40 – have support for INT8 data types and processing. This format is supported in the GP102 and GP104 graphics processors created by Nvidia (which are used in GeForce GPU cards as well as in the Tesla compute engines) but it is not supported in the GP100 GPU that is at the heart of the Tesla P100 accelerators that are aimed at simulation, modeling, and deep learning training workloads.

The GP104 GPU used in the Tesla P4 accelerator is implemented in a 16 nanometer FinFET process from Taiwan Semiconductor Manufacturing Corp, and has 7.2 billion transistors, more than double that of the “Maxwell” GM206 GPU used in the prior generation Tesla M4 card aimed at inference workloads. Nvidia used the process shrink to crank up the number of CUDA cores on the device by a factor of 2.5X. The base clock speed on the CUDA cores in the Tesla P4 is actually a bit lower at 810 MHz, but the GPUBoost speed is almost the same at 1.06 GHz, and Buck says that at 75 watts the thermals are so low that the Tesla P4 can pretty much run in boost mode continuously crank out the cycles. Like the M4 it replaces, the P4 does not have very much in the way of double precision floating point performance – about 170 gigaflops, but at single precision the GP104 GPU delivers 32X the performance across its 20 streaming multiprocessors, or SMs, which works out to 5.44 teraflops.
The Tesla P4 accelerator is a half height, half length PCI-Express 3.0 server card. It has 8 GB of GDDR5 memory, which runs at a slightly faster clock speed than the memory used in the Tesla M4, and with twice as much memory, the aggregate bandwidth on the P4 device is 2.2X higher than on the M4. With the new INT8 support, the Tesla P4’s new IDP2A and IDP4A instructions chew on 2-element and 4-element vector dot product computations with 32-bit integer accumulation, and the P4 unit is capable of cranking through 21.8 tera-operations per second. The M4 did not support the INT8 format, but the upshot is that when it comes to inference, all of these features allow for the P4 to do about 4X as much work as the M4 and about the same cost. What that cost is, we are not sure because we cannot find anyone who is selling them, but we estimate it will be around $2,100.
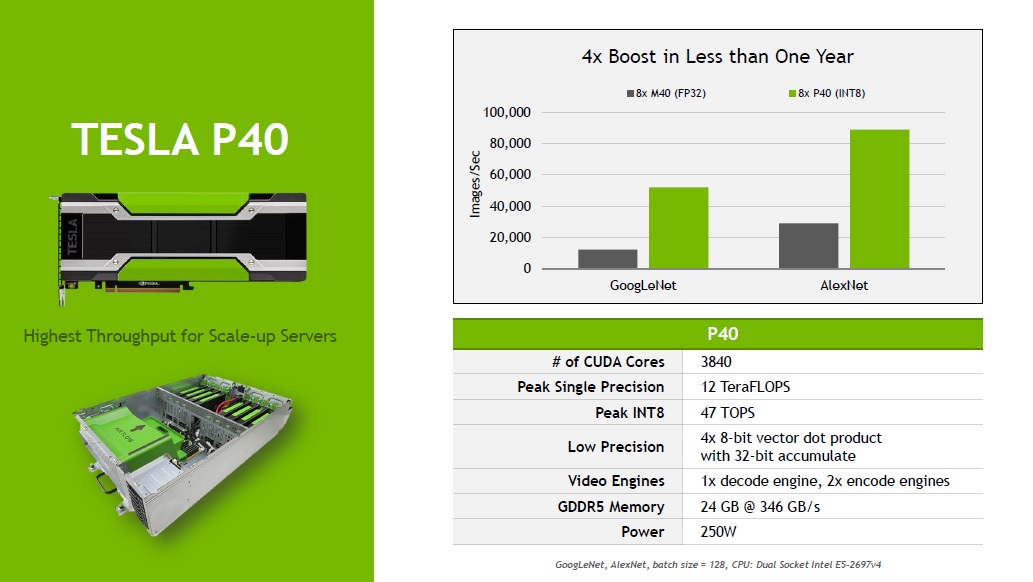
The GP102 GPU that goes into the fatter Tesla P40 accelerator card uses the same 16 nanometer processes and also supports the new INT8 instructions that can be used to make inferences run at lot faster. The GP102 has 30 SMs etched in its whopping 12 billion transistors for a total of 3,840 CUDA cores. These cores run at a base clock speed of 1.3 GHz and can GPUBoost to 1.53 GHz. The CUDA cores deliver 11.76 teraflops at single precision peak with GPUBoost being sustained, but only 367 gigaflops at double precision. The INT8 instructions in the CUDA cores allow for the Tesla P40 to handle 47 tera-operations per second for inference jobs. The P40 has 24 GB of GDDR5 memory, which runs at 3.6 GHz and which delivers a total of 346 GB/sec of aggregate bandwidth.
Depending on the inference workload, the P40 can deliver somewhere between 4X and 5X the throughput of the M40, and at about the same price as the M40, too. The Tesla P40 is a full length, full height card and it will fit into the same 250 watt server slots that the M40 did.
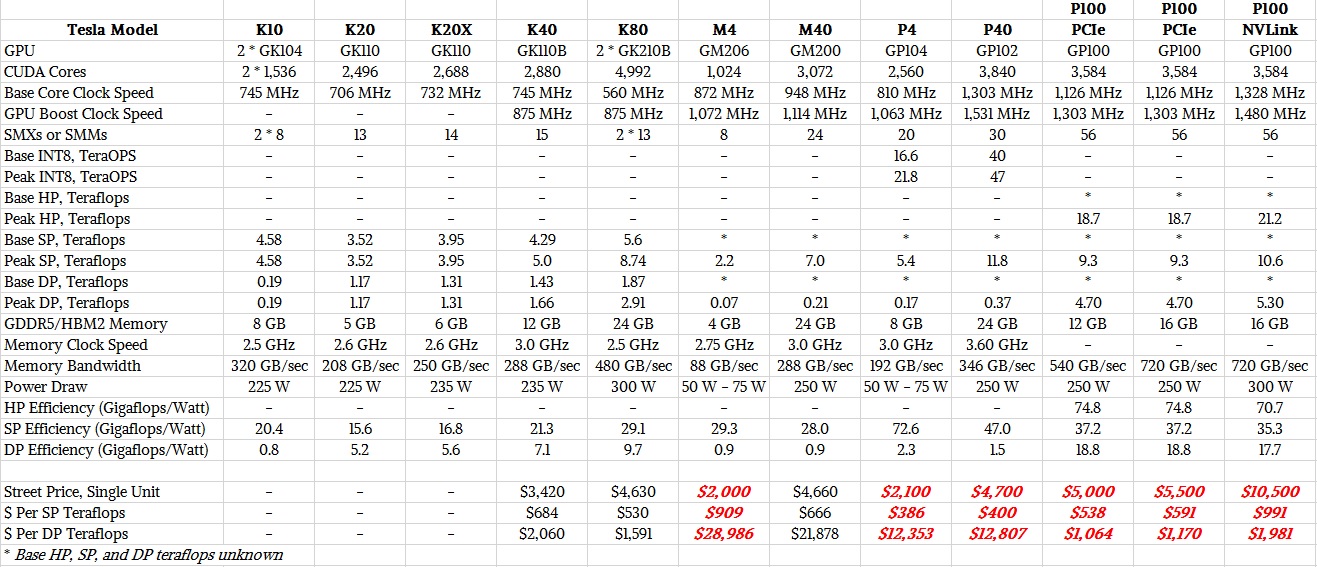
Last year, when the Tesla M4 and M40 accelerators were launched and half precision FP16 support was not yet available in any of Nvidia’s GPUs, the product positioning was that the M4 was the Tesla accelerator aimed at inference workloads and the M40 was aimed at training. (Facebook has 41 petaflops of aggregate M40 accelerators in its clusters for machine learning, by the way.) With the Pascal generation, the GP100 GPUs have 16-bit FP16 half precision floating point support, which doubles up the dataset size and effective memory bandwidth compared to single precision floating point, and therefore helps to roughly double the performance of neural network training. Neither the old Tesla M40 nor the new Tesla P40 support FP16 data formats and processing, so they are not being pitched for neural network training over the Tesla P100 cards. The P4, which also does not support FP16, is being aimed only at neural net inference jobs, just like the M4.
The Tesla P40 will be available in October, and the Tesla P4 will follow in November. Dell, Hewlett Packard Enterprise, Inspur, Inventec, Lenovo, Quanta Computer, and Wistron are all prepping to put the accelerators in their machines.


TACC Fires Up “Vista” Bridge To Future “Horizon” Supercomputer
The Texas Advanced Computing Center at the University of Austin is the flagship datacenter for supercomputing for the US National Science Foundation, and so what TACC does – and doesn’t do – is a kind of bellwether for academic supercomputing. So it is noteworthy that TACC is installing its first …
Cisco Guns For InfiniBand With Silicon One G200
It was a fortuitous coincidence that Nvidia was already working on massively parallel GPU compute engines for doing calculations in HPC simulations and models when the machine learning tipping point happened, and similarly, it was fortunate for InfiniBand that it had the advantage of high bandwidth, low latency, and remote …
What To Do When You Can’t Get Nvidia H100 GPUs
In a world where allocations of “Hopper” H100 GPUs coming out of Nvidia’s factories are going out well into 2024, and the allocations for the impending “Antares” MI300X and MI300A GPUs are probably long since spoken for, anyone trying to build a GPU cluster to power a large language model …
It’s pretty amazing / surprising that not even FPGA:s are keeping up efficiency wise.
It kind of makes me wonder if Altera has a crap implementation? Maybe they’re using their hardened FP32 blocks to do inferencing at high precision?
Nvidias hardware & software stack is just unstoppable right now but I expect that ASICS and FPGA:s should be able to catch up eventually.
Why is it suprise? FPGA reconfigurable facric is big, slow and power demanding. Don’t take me wrong, they are good for prototyping or fast time-to-market application (signal procesing, networking, etc.) but in data procesing and HPC applications they can’t compete againts perfectly tuned GPU or ASIC.
GPUs are just perfectly tuned machines. They have lots of cores, great sheduling logic, easy to saturate memory bw… In FPGA you have only bunch of DSPs and hardened FIFOs (transceivers). So most of work you have to do yourself. And don’d believe that achieving decent memory bw in FPGA is easy. 😉
It is old known tradeof. Universality of CPU or raw performance of GPU. Difference is thet here FPGA must pay for reconfigurability so much.
And i don’t think, that Altera has bad implementation. Actually, there are companies (for example Microsoft) which put so much effort to push their implementations to the limit of FPGAs.
And actually, it is better to use DSP blocks in FPGAs. You don’t waste reconfigurable logic (LUTs) to implement this functions, they are usually faster than reconfigurable logic and also, there are 16×16 or 18×19 or 27×18 DSP blocks (depends on vendor and family) but they are ussualy much smaller than 32×32.
We will see, if new 14nm FPGAs from Intel will be game changer here. Release is expected by end of the year, so we will se.
Ah sounds like I’ve been having the wrong idea about FPGA:s. I’ve often ran into FPGA people who are touting how efficient they are, but now that powerful mobile GPU:s are entering the embedded compute segment, they are, to my surprise taking the efficiency Crown in many applications.
I Always figured FPGA==HARDWARE == best possible solution , but seems reality isn’t really that simple.
Would love to chat more with you about your experiences:
jimmy@fri.nu
Well you have to give nVidia credit how they market an el-cheapo cutdown architecture and sell if for big $$$ is just amazing.
If it’s that many times better than the competition of course they can.
Well that’s only one side of the coin, if people in the decision making are so blind to fall for it, then it’s their own fault.
if its better they’re not really falling for anything, by definition 🙂