

More than a decade ago, executives at Arm Ltd saw the energy costs in datacenters soaring and sensed an opportunity to extend the low-power architecture of its eponymous systems-on-a-chip that has dominated the mobile phone markets from the get-go and took over the embedded device market from PowerPC into enterprise servers.
The idea was to create lower powered, cheaper, and more malleable alternatives to Intel Xeon and AMD Epyc CPUs.
It took years of developing the architecture, disappointments as some early vendors of Arm server processors collapsed or walked away from their plans, and immense effort to grow the software ecosystem, but the company now has a solid foothold in on-premises systems and in cloud datacenters
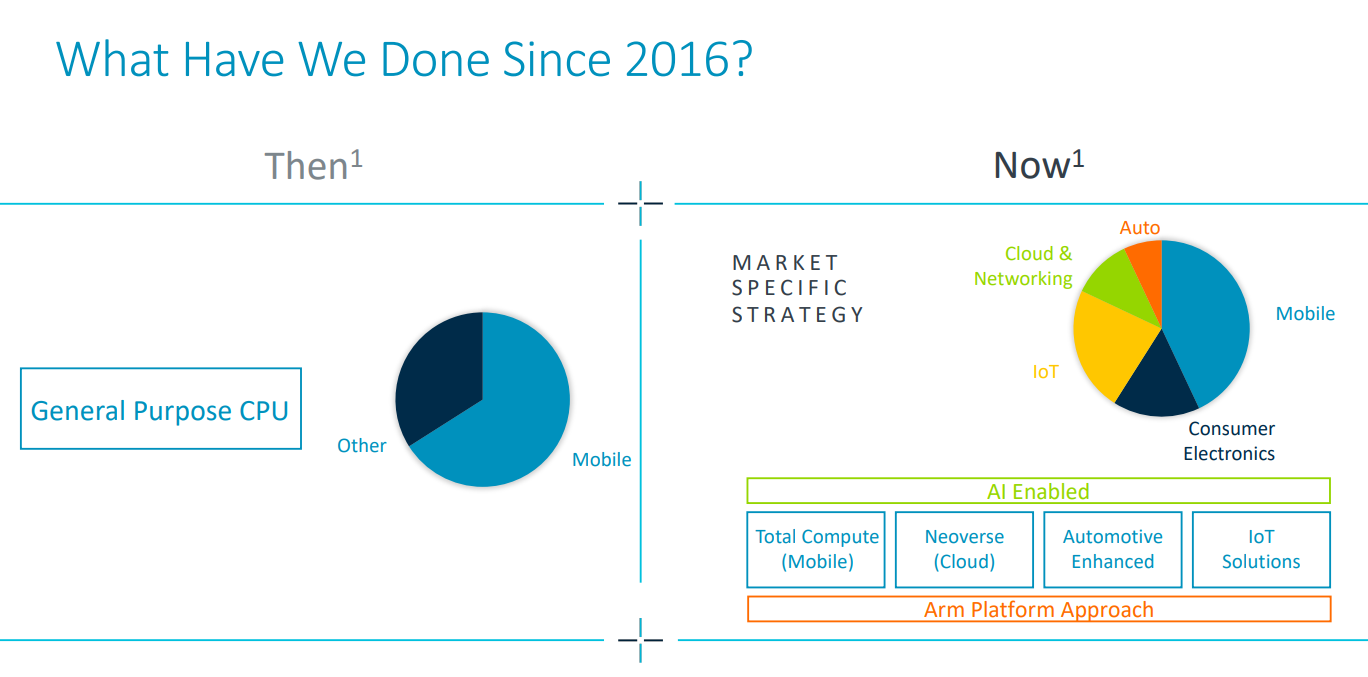
In its latest quarterly earnings filing in February, Arm boasted of its platform approach to markets, noting that in 2016, at least two-thirds of its revenue came from general-purpose CPUs in the mobile space. Now with platforms aimed at multiple markets, including cloud and networking systems. It has also made a mark in HPC, with Fujitsu’s A64FX processors – which power “Fugaku,” the fourth-fastest supercomputer on the most recently Top500 list – based on the Armv8.2-A architecture.
Arm chief executive officer Rene Haas sees a similar opportunity now with the rise of AI. Models now consume huge amounts of power and that will only increase in the future, Haas tells The Next Platform.
“I spend a lot of time talking to CEOs of these companies and this power issue has just been top of mind for everyone relative to finding different ways to address it because the benefits of everything that we think AI can bring are fairly immense,” Haas says. “To get more and more intelligence, better models, better predictiveness, adding in context, learning, etc., the need for compute is just going up and up and up, which then obviously drives power needs. It feels like it has just accelerated – pun intended – over the last number of months, with everything we’re seeing with generative AI and, and, particularly, with all these complex workloads.”
Arm – which with parent company SoftBank is part of the recent $110 million joint US-Japan plan to fund AI research, contributing $25 million to the plan – will play a central role in keeping reins on both the power consumption and associated costs, Haas says. Arm already has shown that its architecture can datacenters 15 percent more energy efficient. These types of savings can also translate to AI workloads, he says.
Haas notes that modern datacenters now consume about 460 terawatt hours of electricity per year, with that figure likely tripling by 2030. He has said that datacenters now consume about 4 percent of the world’s power requirements. Left unchecked, that could rise to as much as 25 percent.
That also will come at a cost. In Stanford University’s latest AI Index report, researchers wrote about the “exponential increase in cost of training these giant models,” noting that Google’s Gemini Ultra cost about $191 million worth of compute to train and OpenAI’s GPT-4 cost an estimated $78 million. By comparison, “the original Transformer model, which introduced the architecture that underpins virtually every modern LLM, cost around $900.”
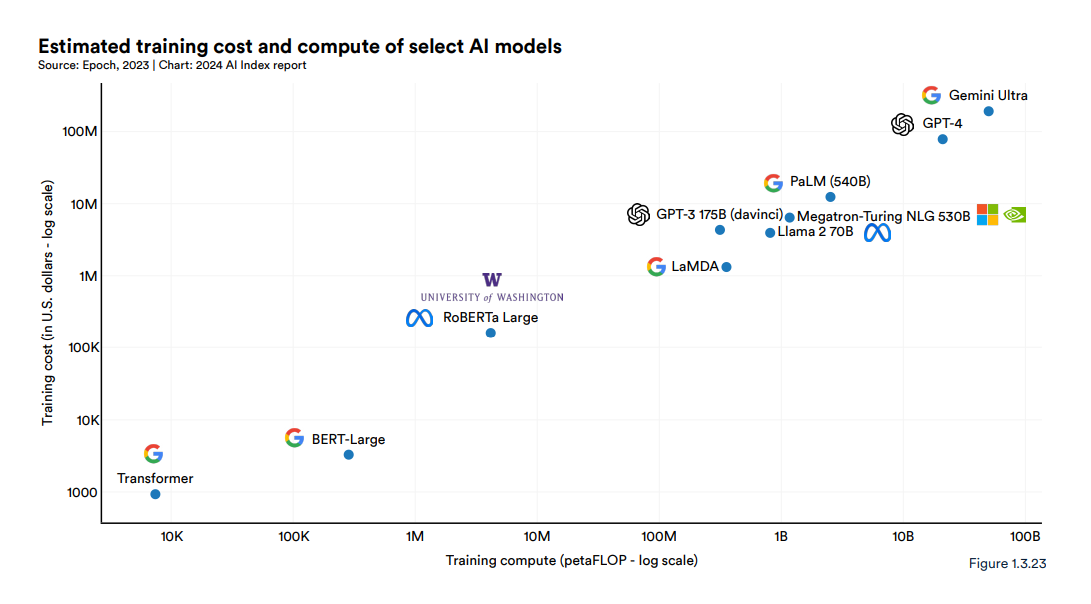
Those costs will only grow, Haas says. The push to by AI companies like OpenAI and Google to reach artificial general intelligence (AGI) – the point where AI systems can reason, think, learn, and perform as well as or better than humans – will call for bigger and more complex models that need to be fed with more data, which will drive up the amount of power consumed.
“I think about just how sophisticated GPT-3 is versus GPT-4, which requires ten times the data, much larger size, longer tokens, etc. Yet it is still is quite limited in terms of its ability to do amazing things in terms of thinking, context, and judgement,” he says. “The models need to evolve and, on some level, need to get much more sophisticated in terms of the data sets. You can’t really do that unless you train more and more and more. It’s virtuous cycle. To get smarter and to advance it off the models and to do more research, you just have to run more and more training runs. In the in the next number of years, the amount of compute required to advance this training is going to be pretty prolific and it doesn’t feel like there’s any big fundamental change around the corner relative to how you how you run the models is there.”
In recent weeks, Arm, Intel, and Nvidia have rolled out new platforms aimed at addressing the growing AI power demands, including the pressure to do more of the model training and inferencing at the edge, where the data is increasingly being generated and stored. Arm this month unveiled the Ethos-U85 neural processing unit (NPU), promising four times the performance and 20 percent better power efficiency than its predecessor.

The same day, Intel unveiled its Gaudi 3 AI accelerator and Xeon 6 CPUs, with CEO Pat Gelsinger arguing that the chips’ capabilities and the vendor’s open-systems approach will drive AI workloads Intel’s way. Haas is not so sure, saying that “it might be hard for Intel and AMD to do their thing because they’re just building the standard products and the big idea of plugging in an Nvidia H100 accelerator connecting into an Intel or AMD CPU.”
The need for greater datacenter efficiency also is fueling the trend toward custom chips, Haas says, noting that most are being built with Arm’s Neoverse architecture. Those include Amazon’s Graviton processors, Google Cloud’s Axion, Microsoft Azure’s Cobalt, and Oracle Cloud’s Ampere, all of which not only drive better performance and efficiency but also the integration needed for AI workloads.
“Now you can essentially build an AI custom implementation for the datacenter and configure it almost in any fashion you want to get a huge level of performance out of it,” he says. “That is the opportunity for us going forward, these custom chips.”
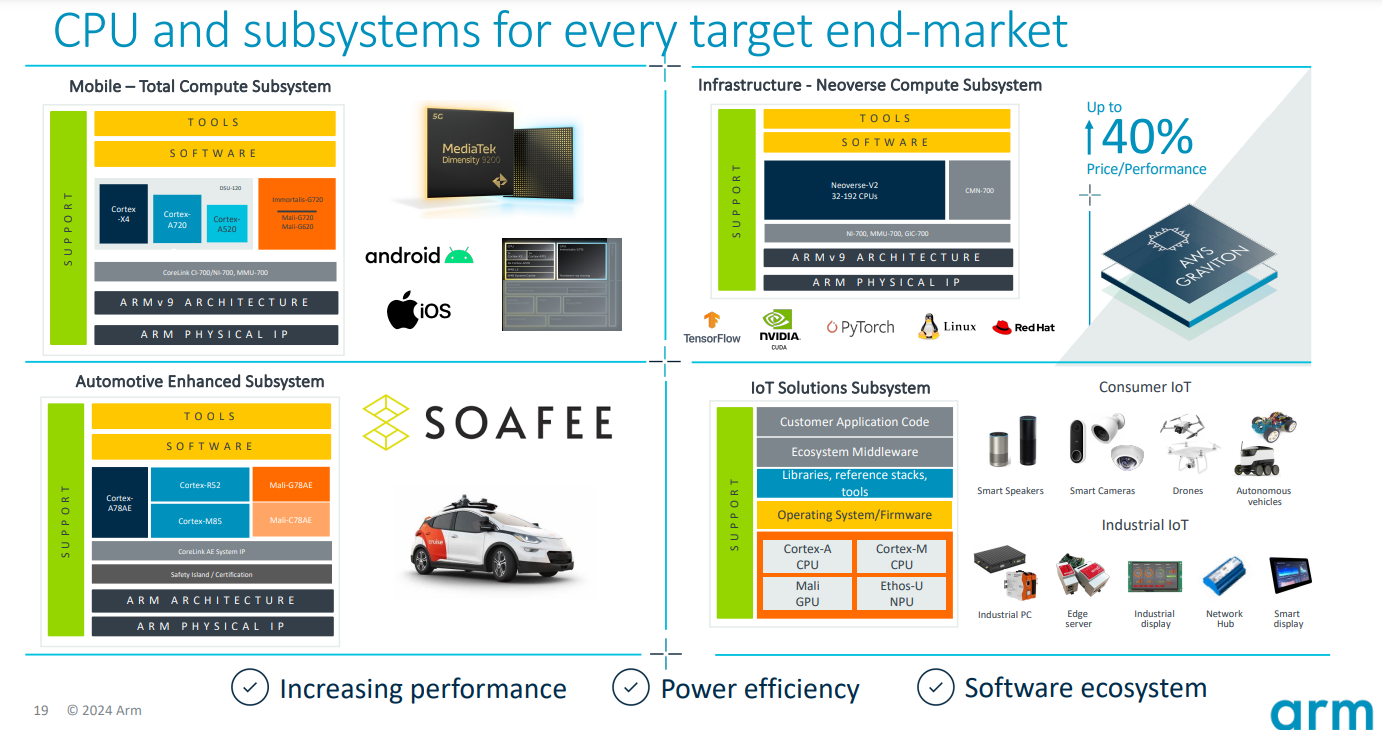
He points to Nvidia’s AI-focused Grace Blackwell GB200 accelerators, which were introduced last month and include two Nvidia B200 Tensor Core GPUs connected to an Arm-based Grace CPU by a 900 GB/s NVLink interconnect.
“To some extent, Grace-Blackwell is a custom chip, because their previous H1 100s basically plugged into a rack and spoked to an X86 processor,” Haas says. “Now Grace-Blackwell is highly integrated into something that uses Arm. Arm is going to be central to much of this because the level of integration that Arm enables and the fact that you can do customization that will really allow for the most efficient type of workloads to be optimized. I’ll use Grace-Blackwell as an example. In that architecture, by using a CPU and GPU over NVLink, you start to address some of the key issues around memory bandwidth, because ultimately, these giant models need huge, huge amounts of access to memory to be able to run inference.”
He says system-level design optimizations made possible by Arm’s architecture helps reduce power consumption by 25X and improve performance-per-GPU by 30X over the H100 GPUs in LLMs. Such customization will be necessary in the AI era, where the pace of innovation and adoption is only accelerating.
“To some extent, one of the challenges that we have in the industry in general is that while these foundation models are getting smarter, smarter, smarter, and the pace of innovation is really fast, to build new chips takes a certain amount of time, to build new datacenters takes a certain amount of time, to build new power distribution capability takes a lot of time,” Haas says. “Ensuring that you are able to design chips with as much flexibility as possible, that’s pretty huge. But it is happening. It is happening at an incredible pace.”




It strikes me that the big AI models happen only after the zero/negative interest rate phase, even though most of the model makers are not concerned with profits right now.
The cheap money/easy funding of the past decade got us business models like Uber and Door dash with a lot of contenders and little (or negative) margin desperate to turn spending and market share into margin and profit. It didn’t work well for most of them unless they sold their shop early enough.
AI and especially the GenAI seems a lot like it. Except this time the biggest players are the ones most able to drop 9-13 figures and the least likely to make money by being acquired and/or going public for the first time.
There’s a lot of money to be made with AI, but I’m not convinced it’s in the flagship Geminis, Copilots, Llamas and MM1s of this world. I see a lot more revenue from engineering and science applications, like Synopsis seems to think of with Ansys, or internal models to manage systems/networks and that sort of applications. But that’s not as flashy or impressive for the public and boards to drop money on due to FOMO.
I sure am looking forward to seeing some impressive combinations of performance and efficiency from ARM devices in Top500 and MLPerf (for example from Grace-Grace, GH200, and/or GB200). At present though, it bears noting that for CPU-only machines, the highest rank on Green500 is at #13 (MN-3, Xeon Platinum 8260M 24C 2.4GHz) which gets 41 GF/Watt, while the A64FX systems run at approx. 16 GF/Watt (eg. #48 Central Weather PrimeHPC). I think that when looking at high performance CPUs (eg. Neoverse V, versus Neoverse N), it remains necessary to pay special attention to the whole system in order for potential “power-sipping” characteristics of the cores to propagate to the whole machine. Apple’s M-based laptops for example, combine SDRAM with the CPU for improvements in both performance and efficicency. Similarly, the LPDDR5 used by Nvidia likely helps the Grace systems in power efficiency. Meanwhile, in most AI-oriented systems, the performance of accelerators probably trumps that of CPUs (w/r overall perf and eff).
Comparing performance and efficiency of LANL’s Crossroads (CPU-only) to that of Venado’s Grace-Grace partition, and also that of MI300A-based systems (El Capitan) to Grace-Hopper machines (Venado, Alps, CEA EXA1 HE, …) should be most informative in this, IMHO. Maybe we’ll see more power-sipping accelerators from ARM (beyond the 4-TOPs U85)?
Hmmmm … no, and yes! The MN-3 is accelerated by custom MN-core processors as you can see here: https://projects.preferred.jp/supercomputers/en/ — it is not a CPU-only system and so A64FX wins on perf/Watt in that category at 16 GF/W. The first x86-only looks to be Leonardo at 7 GF/W (Crossroads is near 5 GF/W).
But yes, the Ballroom blitz Battle Royale between the swashbuckling stronger swagger of El Capitan, Santa’s red-nosed rocket sleigh, the Swiss-cheese-grater of the Alps, and this new EXA1 atomic leaping frog, should be most entertaining (not to mention the recently awakened sleeping beauty!)! q^8
Hopefully that all takes place next month, hosted by the delicious Hamburgers of HPC gastronomy! (May 12-16: https://www.isc-hpc.com/ )
Thanks for the correction. I see it now: Green500 #79 Leonardo-CPU ( https://top500.org/lists/green500/list/2023/11/ ), right there with Mare Nostrum 5 GPP, Snellius Phase 2 CPU, Shaheen III – CPU, … I’m glad I had it wrong (it puts my mind back at ease to see this 2x-3x better efficiency for A64FX ARM in CPU-only action, as actually expected. The universe is back in harmony!).
Good points! Overall efficiency improvements in hybrid CPU+Accelerator architectures may hinge on whether some type of RISC-vs-CISC duality can be identified also in mixed-precision matrix-vector units. This could be key to bringing us closer to the Zettascale, as Kathy Yelick will discuss in her ISC 2024 Keynote ( https://www.isc-hpc.com/conference-keynote-2024.html ).
Scaling Frontier straight to 1.2 ZF/s would see it consume 23 GW of juice. Assuming that MxP is acceptable for FP64 accuracy and gives a 10x performance boost reduces that to 2.3 GW — which is already less than Microsoft’s 5 GW “death”-star-gate AI project ( https://www.nextplatform.com/2024/04/01/microsoft-stargate-the-next-ai-platform-will-be-an-entire-cloud-region/ , https://www.theregister.com/2024/04/01/microsoft_openai_5gw_dc/ ). Switching to RISC-CPU and RISC-accelerator (if possible) might get this down to 1 GW– still large, but 30 years ago (June 1994) the Top500 #1 was Sandia’s XP/S140 at just 184 kW (and 0.14 PF/s). If it was acceptable to increase power consumption by 100x to get from there to the ExaFlop of Frontier, maybe it is okay to increase it another 50x for a FP64 MxP ZettaFlopper?
While the Arm power efficiency claims are impressive, the lack of real data is not. Is there a single CPU to CPU perf/w comparison of best-in-class x86 and best-in-class Arm from the currently shipping generation of CPUs? Also, how much of the GH or GB efficiency benefits are purely from the GPU and the NVLINK between the CPU and the GPU versus something fundamental in the Arm architecture? Inquiring minds want to know 🙂