

This week Nvidia shared details about upcoming updates to its platform for building, tuning, and deploying generative AI models.
The framework, called NeMo (not to be confused with Nvidia’s conversational AI toolkit or BioNeMo for drug development), is designed to let users train large-scale models and is the same platform used for a recent MLPerf run on GPT-3 175B that achieved 797 teraflops per device across 10,752 H100 GPUs.
Dave Salvator, Director of Accelerated Computing Products at Nvidia tells The Next Platform that NeMo is being used by companies like AWS as part of their Bedrock and Titan models with several AWS customers leveraging that to develop their own. He adds that other customers, including SAP and Dropbox are using the framework and contributing insights about new features.
“The LLM space is still relatively nascent and there’s still a lot of discovery going on around the ways we can make the models smarter and more capable but try to do that in a way that doesn’t completely crush your infrastructure, that lets you get training done in a practical amount of tie measured in days and weeks as opposed to years or even decades,” Salvator tells us.
As noted above, the performance is worth a look:
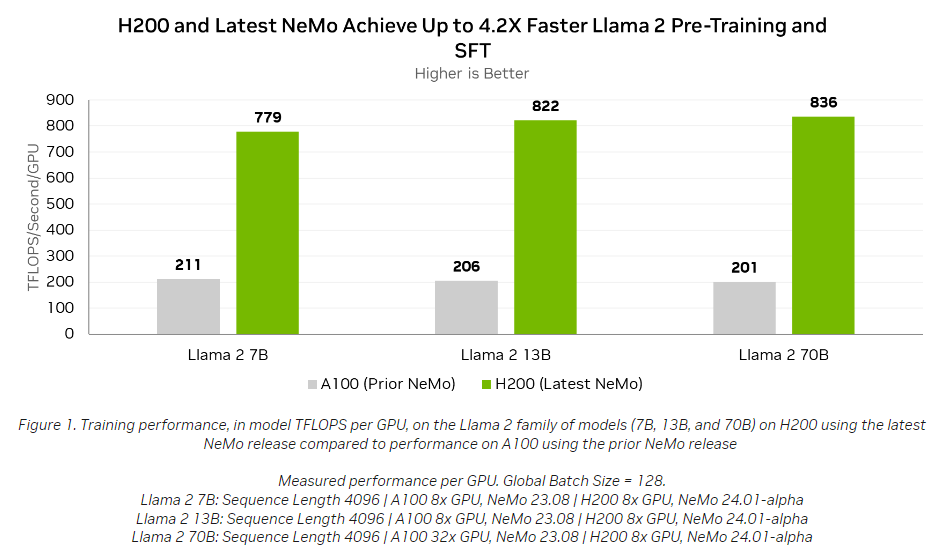
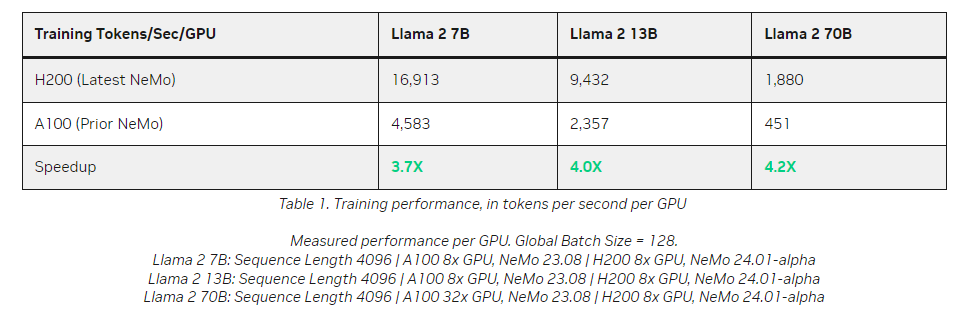
The 4.2X is achieved using supervised tuning, which is a harder way to do things but gets a more accurate model. The thing to note is how even on the Llama models of varying sizes (the same architecture is run with different hyperparameter counts between 7-70B) Nvidia is able to maintain throughput per GPU for the most part.
There is a fair amount of inference built into the LLM training process (bringing data in from the dataset, seeing results, and updating the model). If you’re doing this kind of fine-tuning, it’s not a one-shot deal: it’s iterative and extended. By bringing the new feature inside the training process to do reinforcement learning with human feedback, Salvator says users can see a 5X performance bounce. In a small config of 16 GPUs on a 2m parameter model the 5X is easily doable and even if bumping to 129 GPUs and a commensurate model size increase, it doesn’t fall far, if at all, from the 5X mark.
According to Nvidia, following the introduction of TensorRT-LLM in October, they were able to demonstrate the ability to run the latest Falcon-180B model on a single H200 GPU, leveraging TensorRT-LLM’s advanced 4-bit quantization feature, while maintaining 99% accuracy, as detailed in this technical piece from the team from today.
Among other new features that helped Nvidia reach the above results is the addition of fully sharded data parallelism, something that’s already baked into other platforms (PyTorch, for instance). To be fair, this didn’t add any of the cited speedup (in fact, there might have been a slight hit) but it does bring ease of use.
In essence, it’s a friendlier way to get different parts of a model to lay across different GPU resources. This can mean faster time to market for models, Salvator says, which might cancel out some of the performance hit but he’s confident they’ll be able to trim down the tradeoff in successive updates.
Nvidia has also added mixed-precision implementations of the model optimizer, which they say “improves the effective memory bandwidth for operations that interact with the model state by 1.8X”. If you’re not knee-deep in tuning models, it might seem odd that mixed-precision support is just being added but it’s not as simple as having FP8 and just using it.
As Salvator explains, “just because FP8 is implemented in hardware, doesn’t mean you can use it across the board on a model and expect that it’s going to converge… We have our transformer engine tech and can go layer by layer, examine the model and see if a specific layer can use FP8. If we come back and see it will cause unacceptable accuracy losses that will slow down training or keep the model from converging we run in FP16.”
He adds, “It’s not just about having FP8 as a checkbox, it’s about being able to intelligently use it.”
Another feature, called Mixture of Experts (MoE) has been added, which “enables model capacity to be increased without a proportional increase in both the training and inference compute requirements.” Nvidia says MoE architectures achieve this through a conditional computation approach where each input token is routed to only one or a few expert neural network layers instead of being routed through all of them. This decouples model capacity from required compute. The latest release of NeMo introduces official support for MoE-based LLM architectures with expert parallelism.
The MoE models based on NeMo support expert parallelism, which can be used in combination with data parallelism to distribute MoE experts across data parallel ranks. Nvidia says NeMo also provides the ability to configure expert parallelism arbitrarily. “Users can map experts to different GPUs in various ways without restricting the number of experts on a single device (all devices, however, must contain the same number of experts). NeMo also supports cases where the expert parallel size is less than the data parallel size.:
“LLMs represent some of the most exciting work in AI today, the most interesting advances are based on LLMs due to their ability to text, computer code, or even proteins in the case of BioNeMo. However, all that capability comes at a significant requirement of both compute, memory, and memory bandwidth and full system design,” Salvator says.
“What we’re doing with NeMo framework is continuing to find new techniques and methods and listening to the community about what to implement first to bring more performance and ease of use to make it possible to get these models trained and deployed.”




Interesting presentation! I’m glad they are incorporating mixed-precision in NeMo, it made me think about bf16 (bfloat16, brain floating point) and a trip to WikiPedia that promptly sent me back to TNP ( https://www.nextplatform.com/2018/05/10/tearing-apart-googles-tpu-3-0-ai-coprocessor/ )! bf16 now makes sense to me, for FP32-oriented mixed-precision, as it has the same sign and exponent bits as FP32, but a shorter mantissa (7 bits vs 23 bits). Might some hf16 and hf32 encodings, with 1 sign bit and 11 exponent bits, be similarly useful for FP64-oriented mixed-precision (eg. in HPC, with 4, 20, and 52 mantissa bits) … “Inquisition Minds” … ?
And BioNeMo! That sure sounds interesting in view of yesterday’s TNP “Test of Time” article on the Battle Royale between MD and genAI in the ring of protein folding, and ironing … (eh-eh!)
Hmmm, your hf16-hf32-FP64 mixed-precision proposition is quite intriguing. In the same vein, for computational problems that don’t need the gigantic dynamic range afforded by 11-bit exponents (eg. 1e-308 to 1e308), but do benefit from a more precise (longer) mantissa to tackle roundoff error, I think that a system of bf16-FP32-bf64 could be a mixed-precision winner, with bf64 having 1 sign bit, 8 exponent bits, and 55 mantissa bits (a precision-only extension of FP32).