

AMD has been on such a run with its future server CPUs and server GPUs in the supercomputer market, taking down big deals for big machines coming later this year and out into 2023, that we might forget sometimes that there are many more deals to be done and that neither Intel nor Nvidia are inactive when it comes to trying to get their compute engines into upper echelon machines.
System maker Fujitsu, which has built its own A64FX heavily vectored processor and the surrounding system and interconnect for the “Fugaku” supercomputer at the RIKEN Lab in Japan, did not just take a chip off the Fugaku block and sell that to the University of Tokyo. It sort of did. But then Fujitsu and the university’s Information Technology Center, which has installed some famous machines over the years and which has a history of using all-CPU as well as hybrid CPU-GPU systems, grafted another hybrid CPU-GPU system onto the side. So the impending “Wisteria” system, is really a cross-coupling of two distinct but related clusters, the latter hybrid machine being built by Fujitsu using a combination of future Intel processors and current Nvidia GPU accelerators.
The Wisteria system is the first iteration of what UTokyo calls the Big Data and Extreme Computing, or BDEC, architecture, is going to be installed in phases, with a CPU heavy partition called Wisteria-Odyssey going in first and a GPU-laden partition called Wisteria-Aquarius.
It is relatively easy to build the hardware, but getting the budget is always a challenge and the most interesting bit of Wisteria may turn out to be the software stack, called the Hierarchical, Hybrid, Heterogeneous Open BDEC platform, or H3 for short, that creates a pipeline that brings together HPC simulation, data analytics, and machine learning under the covers of the machine and provides a workflow where these three distinct workloads can feed into each other to create more efficient simulations and analyses.
At the moment, the plan is to run the traditional HPC simulations and models on the CPU-only Wisteria-Odyssey partition and to run the data analytics and machine learning – and we also presume the visualization of results as well, although this is not mentioned – on the Wisteria-Aquarius partition. But there is nothing that will prevent machine learning inference from running on the CPU-only partition or that will prevent GPU-accelerated HPC workloads from running on the hybrid CPU-GPU partitions. The 512-bit wide vector units on the 48-core A64FX processor used in Fugaku machine – and now the Wisteria-Odyssey machine – supports the expected 32-bit single precision and 64-bit double precision floating point math we expect in an HPC systems, but also support 16-bit half precision floating point as well as 8-bit and 16-bit integer data types that use the vector as a dot-product engine and output to a 32-bit floating point format.
While Fujitsu could have used any interconnect between these A64FX nodes, it stuck with the Torus Fusion D (Tofu D) interconnect, which is the fourth generation of 6D torus interconnect created by Fujitsu and specifically designed for the Fugaku machine at RIKEN. (NEC and Fujitsu worked together on the original Tofu interconnect used in the K supercomputer at RIKEN a decade ago, but Fujitsu took over development after that.) Opting for Tofu D, which we detailed here, stands to reason since the compute nodes and the interconnect are tightly architected together. While companies such as Hewlett Packard Enterprise are able to resell A64FX nodes in their supercomputers, very likely using the Slingshot HPC variant of Ethernet created by Cray (which was acquired by HPE last year), we do not think there will necessarily be a lot of takers for this approach given the very tight coupling between A64FX compute and Tofu D interconnect.
The Wisteria-Odyssey partition is comprised of 7,680 single-socket A64FX processors, which are housed in a Fujitsu PrimeHPC FX1000 system spanning 20 racks and which have a total of 368,640 cores. (There are two or four helper cores, running operating system and other functions, on the A64FX chips, and we are not counting these because they are not used for computation. But that is still another 30,720 cores if you use the four helper core option. It does add up.) Each A64FX node has 32 GB of HBM2 memory, so Wisteria-Odyssey has 240 TB of memory with a combines 7.8 PB/sec of bandwidth. The Tofu D interconnect within the baby Fugaku portion of the Wisteria machine has a bisection bandwidth of 13 TB/sec. Add it all up, and the Wisteria-Odyssey portion of the Wisteria machine has 25.9 petaflops of peak theoretical double precision oomph.
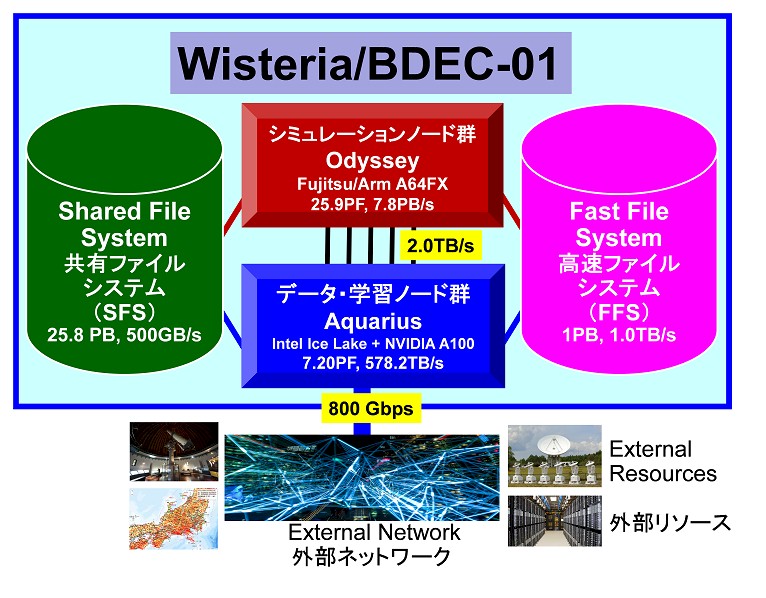
The Aquarius partition of the Wisteria machine is comprised of Fujitsu Primergy GX2570 servers, which have two X86 processors and eight Nvidia V100 or A100 GPU accelerators in a rack-mounted, 4U chassis. This partition has a total of 45 nodes, and it will be equipped with a pair of the impending “Ice Lake” Xeon SP processors from Intel and eight of the Nvidia A100 accelerators. At double precision floating point, the Wisteria-Aquarius partition is rated at 7.2 petaflops, but with lower precision and sparse matrix support, those A100s can drive about 25X the throughput at 4-bit integer math with sparse matrix on. The Wisteria-Aquarius partition has 36.5 TB of combined HBM2 memory with 578.2 TB/sec of memory bandwidth.
Just a reminder, the closest analogy to a CPU core with an Nvidia GPU is the streaming multiprocessor, and the GA100 GPU has 128 of these on the die and 108 of them are activated on the A100 GPU accelerators that Nvidia is currently selling. (At some point, the 7 nanometer processes that Taiwan Semiconductor Manufacturing Corp is using to etch the GA100 GPU will improve and more of these streaming multiprocessors will be able to do work and we should expect a refresh of the product line, likely with an expansion of memory to the full 48 GB of HBM2 on the device.) The Wisteria-Aquarius partition has what is effectively 38,880 cores delivering that 7.2 petaflops. The GPUs have much higher compute density – that’s an order of magnitude more “cores” on the CPUs but only 3.6X more performance – but we will venture based on past results that the computational efficiency for HPC workloads on the A64FX portion of the Wisteria machine will be in the 90 percent range after tuning, and the hybrid CPU-GPU portion will be lucky to be in the 70 percent range. This efficiency gap has been reflected in the High Performance Linpack results as well as HPCG and other tests and comes as no surprise to us. Getting two things to work together in harmony is harder than getting one thing to work well. The CPU-GPU partition is, however, going to be cheaper per unit of peak compute and probably offer better energy efficiency. None of that matters much because for the moment machine learning training is done on GPUs. Full stop.
The nodes in the Aquarius partition are interconnected with four 200 Gb/sec HDR InfiniBand ports from Nvidia (from its formerly independent Mellanox Technologies division). Each node in the Aquarius partition has a 25 Gb/sec Ethernet port for management as well. There is a network of switches based on 100 Gb/sec EDR InfiniBand, which provides a total of 2 TB/sec of interconnect bandwidth, between the Odyssey and Aquarius partitions, and there is 800 Gb/sec of aggregate Ethernet bandwidth coming out of the backend of the Aquarius cluster to the outside world.
The Wisteria machine’s partitions both plug into two file systems. The shared file system has 25.8 PB of capacity and has a data transfer rate of 500 GB/sec; it is presumably based on disks. The fast file system has 1 PB of SSD flash memory as its primary storage, and delivers 1 TB/sec of bandwidth – the kind of level that five years ago needed a burst buffer of memory and flash to accomplish. Both parallel file systems are running the Fujitsu Exabyte File System, which is the Japanese company’s implementation of Lustre. Many years ago, Fujitsu did lots of work on Lustre to make it reach exabyte limits, pushing its features many orders of magnitude over the stock Lustre code out there in the wild.
The idea behind the Wisteria machine is to create feedback loops between HPC and AI, and to be easily to move data back and forth across machine learning, analytics, and simulation. Fortran and C/C++ as well as Python are supported, and the Message Passing Interface (MPI) protocol will be used across the HPC and AI portions of the system for scaling applications.
The Wisteria machine will be up and running in the middle of May and fully operational by October, just in time for the November 2021 Top500 supercomputer rankings.


Fractional GPUs Empower New Wave Of Accelerated Software Development
There is no denying that GPUs have incredible potential to accelerate workloads of all kinds, but developing applications that can scale across two, four, or even more GPUs continues to be a prohibitively expensive proposition. The cloud has certainly made renting many compute resources more accessible. A few CPU cores …
Details Emerge On Europe’s First Exascale Supercomputer
Some details are emerging on Europe’s first exascale system, codenamed “Jupiter” and to be installed at the Jülich Supercomputing Center in Germany in 2024. There has been a lot of speculation about what Jupiter will include for its compute engines and networking and who will build and maintain the system. …
VMware Partners Its Way Deeper into Cloud, Edge, And AI
Software maker VMware has always been about tight partnerships with other tech vendors. When you are middleware between hardware and operating systems, you sort of have no choice. You need to support a diverse set of hardware below and a rich of operating systems and applications above. During its early …
Be the first to comment