

The GPU has become a standard platform for accelerating high performance computing workloads, at least for those that have had their code tweaked to support acceleration at all. Up until recently though, the majority of that acceleration has taken place on host systems using Intel Xeon or IBM Power processors. But with Nvidia making good on its commitment to support Arm as a peer to X86 and Power, the prospects for HPC powered by the Arm-GPU combo have increased significantly.
From Nvidia’s perspective, this certainly makes a lot of sense, given that Arm is being groomed as a replacement for X86 in future HPC deployments, especially in the European Union and the United Kingdom. In the United States and elsewhere, Arm is seen as a way to inject more diversity and competition into the HPC ecosystem. Then there’s the broader geographical possibilities of Arm in hyperscale, cloud and enterprise settings.
Helping Nvidia to make this Arm-GPU computing model a reality for HPC is a trio of big-name supercomputing centers: RIKEN in Japan, University of Bristol in the United Kingdom and Oak Ridge National Laboratory in the United States.
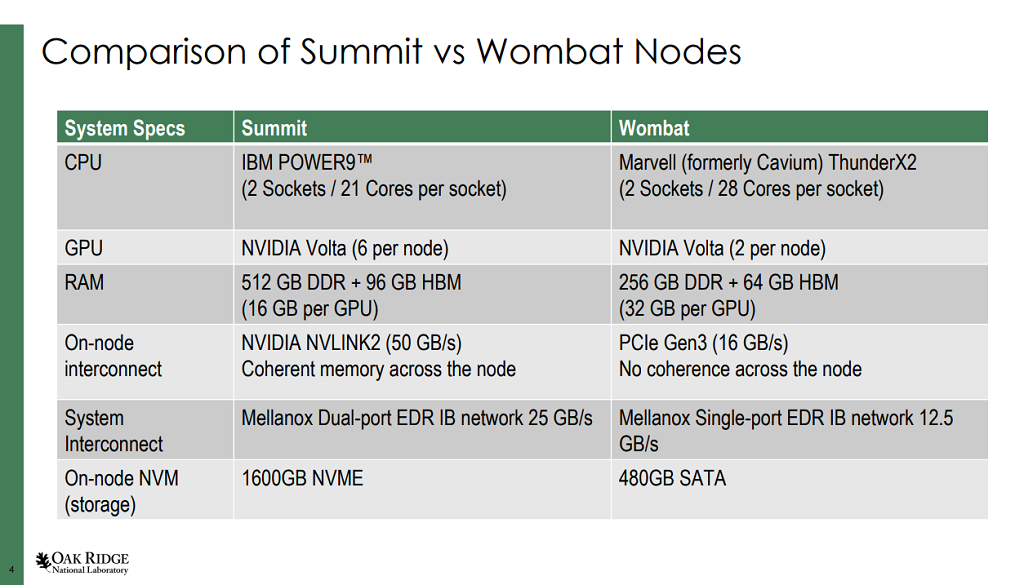
In the case of Oak Ridge, the lab has embarked on this effort by equipping its ThunderX2-based Wombat testbed cluster with Nvidia V100 GPUs and using the setup for porting and benchmarking an array of accelerated HPC codes. Wombat is comprised of 16 pre-production HPE Apollo 70 nodes, each outfitted with a pair of 28-core ThunderX2 CPUs, 256 GB of RAM, and 100 Gb/sec EDR InfiniBand network interfaces. Four of the nodes have been equipped with Nvidia V100 GPUs, two per node, with each GPU hooked into 32 GB of HBM2 memory. Compared to the V100 GPUs setup on Oak Ridge’s “Summit” supercomputer, Wombat’s have twice as much HBM2 memory, but a much slower interface, since these GPUs use PCI-Express 3.0 links instead of Nvidia’s purpose-built NVLink2 interconnect.
On the software side, Wombat users were presented with the Arm-enhanced CUDA 10.1 (pre-release), along with an array of Arm-supported compilers, including gcc v8.2, gcc v9.2, the Arm Compiler for HPC v19.3, and a developer’s version of the PGI with CUDA Fortran support. Support libraries consist of OpenMPI v3.1 and v4.0, and UCX 1.7.0, as well as optimized BLAS, LAPACK, FFT other math routines provided by the Arm Performance Libraries.
Among the application tested were the Combinatorial Metrics (CoMet) code for comparative genomics; GROningen MAchine for Chemical Simulations (GROMACS), used for molecular dynamics simulations; the Dynamical Cluster Approximation ++ (DCA++) code for quantum many-body systems; the Large-scale Atomic/Molecular Massively Parallel Simulator (LAMMPS) code; and the Locally Self-consistent Multiple Scattering (LSMS) code for material sciences.
Wayne Joubert, a computational scientist in the Scientific Computing Group at Oak Ridge, tells The Next Platform that porting was fairly straightforward, mostly requiring changes to the application build scripts. For example, porting, testing and benchmarking of the primary methods of CoMet required less than two days. Other codes required just hours to port.
“The experience was very similar to moving the code from X86 to the Power architecture,” Joubert told us. “In fact, the most significant challenge in porting was to ensure that all the required system software was installed on the system.”
Ross Miller, an HPC systems programmer in the Technology Integration Group at ORNL, said the different teams porting the codes had just a couple of weeks prior to SC19 to port the codes, so in most cases they only had time to get the applications up and running on Wombat, rather than do the more labor-intensive work of optimizing their performance. For example, although the GPUs had twice the HBM2 capacity as the GPUs on Summit, the developers didn’t get the chance to tune their problem sizes for the additional memory.
“In at least one case (VMD), the developer had written hand-tuned SSE, AVX and AVX-512 routines for the X86 code,” Miller noted. “The Arm port had to rely entirely on compiler generated code that just wasn’t as efficient. If the developer spent the time to write similarly optimized routines for the NEON instruction set, the performance would be much closer.”
Generally, the GPU performance was within 20 percent of that of Summit, the variance attributed to the less powerful host processor (ThunderX2 versus Power9) and the lack of optimizations. Some applications were affected by the lower PCIe bandwidth, while for others, the difference wasn’t that noticeable. Given all those factors, plus the fact that Wombat is using pre-production hardware and, in some cases, pre-production software, it’s a little early to say anything definitive about the relative performance of this Arm-GPU mix.
Likewise, it’s also little too early to evaluate the energy efficiency of this particular system. That’s something they intend to look at in the future. “We are looking forward to seeing the results once these codes are fully optimized for the system,” explained Miller. “Wombat will enable us to design more targeted solutions as we port these important scientific applications to new and emerging Arm-based architectures.”
Everyone involved here – Arm, Nvidia, and the HPC user community – is playing the long game. At this point, no one is expecting Arm to take the HPC market by storm, as was the case in the early 1990s when the X86 took over HPC and became the dominant architecture for the next three decades. But little by little Arm can chip away at the competition, bring in new players, and perhaps more importantly, make sure the old players stay humble.


Cache Is King
The gap between the performance of processors, broadly defined, and the performance of DRAM main memory, also broadly defined, has been an issue for at least three decades when the gap really started to open up. And giving absolute credit where credit is due, the hardware and software engineers that …
Red Hat Stacks Up Software To Contain AI On Nvidia Platforms
Nvidia and VMware have forged a tight partnership when it comes to bringing AI to the enterprise, which stands to reason given the prevalence of VMware’s ESXi hypervisor and vSphere management tools across more than 300,000 companies worldwide. But there is another important server virtualization and container platform provider: Red …
Extended “Blackwell” GPU Ramp Cools Growth At Supermicro
Nvidia may be shipping its “Blackwell” B100, B200, and GB200 compute engines, but not in enough volumes for server maker Supermicro to meet its revenue expectations in the quarter ended in December. And the less-steep Blackwell ramp has put a damper on the next two quarters as well, the companies …
Be the first to comment