

There is little question that generative AI as well as other kinds of machine learning are going to augment applications in every industry and in every part of the application stack in the coming years. It is also pretty obvious that AI training for the most advanced models, with trillions of parameters in their neural networks and trillions of tokens of data, is very costly and that if generative AI is to be deployed in production, a way has to be found to do AI inference at a much lower cost.
With the largest GenAI models, it takes tens of thousands of GPUs to train those models over the course of somewhere around three or four months. And it takes a node or two with eight GPUs each to do the inferencing that creates the generative responses that will be embedded in the applications mentioned above. If GPUs do not get a lot smaller and cheaper, then CPU makers will be able to add a lot more matrix math capability to their devices to keep inference work from shifting even more than it has to GPUs or other kinds of matrix math accelerators. If the CPUs don’t get enough matrix oomph and take the business back from GPUs, there is a chance that GenAI will not be cheap enough to be widely deployed – at least not at what GPUs cost these days.
It is an interesting conundrum. And it is not clear how this might all play out. Intel has a relatively weak position in matrix math accelerators with its “Ponte Vecchio” Max Series GPUs – they are too hot and too expensive to make – and even with its well-regarded Gaudi 2 and Gaudi 3 neural network processor (NNP) chips, it is not at all clear how customers will adopt them for GenAI inference. The Gaudi line will be displaced by the future “Falcon Shores” converged GPU-NNP sometime in 2025, so it is a bit of a dead end and there is no reason to believe that Intel can build a better and cheaper GPU than either Nvidia or AMD can in 2025. Also, there is no indication that Intel is going to be wildly expanding the low-precision math capabilities of the AMX units in the future Xeon SP cores, either.
We continue to believe that companies want to run AI inference on their CPUs whenever possible, but the trouble is this might not be possible with the most advanced GenAI models, which need a lot of compute to achieve acceptably low latencies on responses to prompts.
It is against this AI backdrop, as well as increasing competition from AMD on the X86 server CPU front and the dominance of Nvidia in datacenter GPUs and the rise of AMD in datacenter GPUs, that we have to consider Intel’s current datacenter compute business. Yes, it did better than expected in the third quarter ended in September. Which is great for those of us who want intense competition to drive down prices for datacenter compute of all kinds. But this battle for the datacenter is far from over, and in fact may be a decades-long war that no vendor can ever win. The fact that Intel could control datacenter compute for so long is perhaps an anomaly that can never be repeated, even if it looks like Nvidia is setting the pace for the datacenter. There are a lot of workloads that have nothing to do with AI. But the question is how long will this remain true? Over the next four or five years, AI training and inference together could drive around half of server revenues by our estimates. We do not doubt this, but it is less clear where these AI training and inference workloads will run.
Pat Gelsinger, Intel’s chief executive officer and general manager of its datacenter business as well as its first chief technology officer in glory days gone by, talked a bit about this situation in going over the company’s financial results for the third quarter.
“While the industry has seen some wallet share shifts between CPU and accelerators over the last several quarters, as well as some inventory burn in the server market, we see signs of normalization as we enter Q4, driving modest sequential TAM growth,” Gelsinger explained. “Across most customers, we expect to exit the year at healthy inventory levels, and we see growth in compute cores returning to more normal historical rates off the depressed 2023. More importantly, our successful road map execution is strengthening our product portfolio with Gen 4 and Gen 5 Xeon, Sierra Forest and Granite Rapids positioning us well to win back share in the datacenter. In addition, we expect to capture a growing portion of the accelerator market in 2024 with our suite of AI accelerators led by Gaudi, which is setting leadership benchmark results with third parties like MLCommons and Hugging Face. We are pleased with the customer momentum we are seeing from our accelerator portfolio and Gaudi in particular, and we have nearly doubled our pipeline over the last ninety days.”
That pipeline is about a $2 billion opportunity, mostly centered on the Gaudi line of accelerators that are seeing a resurgence in a world of extremely scarce GPU supplies from Nvidia and AMD, if we understand how Intel has talked about it over the past several quarters, but we think that AI inference and training servers represent something close to $50 billion in revenues in 2023. And be careful of comparing a pipeline to actual sales – pipelines are always many factors larger than revenues, and moreso as there are many different competitors with various devices to chase those opportunities.
As we have said before, if you can make a reasonable matrix math engine and run TensorFlow and PyTorch on it, you can sell it. The fact that Intel is putting 4,000 of the Gaudi 2 devices on a cloud and not selling them directly to an AI startup is interesting to us. You might jump to the conclusion that maybe Intel can’t sell this capacity directly to customers. But when AI processing capacity generates around 2.5X more revenue over multiple years than selling the raw iron itself, you can see now why Intel would be building its own cloud and getting Stability.ai, the maker of the Stable Diffusion generative image processing platform, as its anchor customer.
Given the dearth of Nvidia “Hopper” H100 GPUs and given that we really have no idea how many “Antares” Instinct MI300A and MI300X GPUs that AMD can make, small wonder that Intel can sell Gaudi 2 accelerators – and indeed, will be able to sell the Gaudi 3 accelerators that will double performance. So what? The question is will this revenue be material, and will these sales lay a foundation for the future Falcon Shores GPU or not?
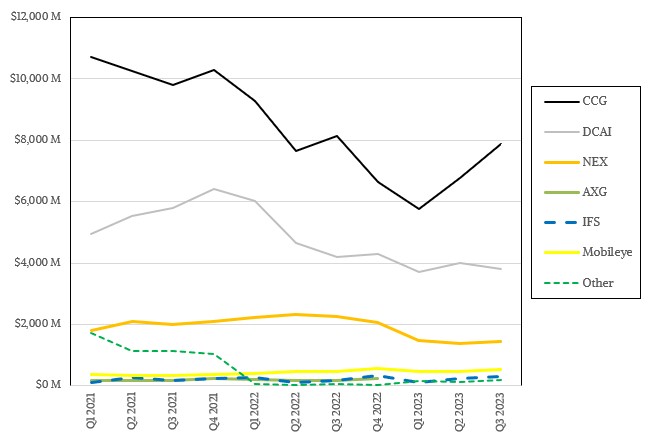
The Data Center & AI group, or DCAI for short, had $3.81 billion in sales, down 9.4 percent, and posted an operating income of $71 million, 4.2X higher than the year ago period.
Intel is introducing a new abbreviation into out lives: MNCs, short for multinational corporations and what we used to just call “large enterprises to make it distinct from SMBs, or small and medium businesses, and hyperscalers and cloud builders as we call them, which Intel might abbreviate to be HCBs if it wants to start sounding like a military organizations. Anyway, Gelsinger said on the call that DCAI exceeded Intel’s forecasts by a little bit and that revenues were up modestly on a sequential basis, with the world’s ten largest CSPs – short for cloud service providers, which is apparently hyperscalers plus cloud builders – having the “Sapphire Rapids” fourth gen Xeon SPs, which launched in January of this year, in production. Intel broke through 1 million shipments of Sapphire Rapids at the beginning of this quarter and will break through 2 million shipments in November, according to Gelsinger, who also has high hopes for the sixth gen “Granite Rapids” Xeon SPs, which will have 2X to 3X the AI performance of Sapphire Rapids.
Gelsinger reminded everyone that the fifth gen “Emerald Rapids” Xeon SP, which is just a tweak on Sapphire Rapids, will be launched on December 14, and that the sixth gen “Sierra Forest” Xeon SP based on its energy-efficient “Sierra Glen” E-cores rather than the “Redwood Cove” performance cores, or P-cores, that are coming in the Granite Rapids Xeon SPs, also a gen six product sharing the same “Birch Stream” socket and platform. Sierra Forest, which will pack 144 cores on a die and which will come in a two-die socket with 288 cores, comes in the first half of 2024, with Granite Rapids following shortly after it. (We drilled down into both CPUs back in September.)
We shall see how much Intel gets supply wins and how much it gets design wins. It’s not like AMD is sitting still with Epyc CPUs and Nvidia and Ampere Computing are not competitive in some server segments, too, And Google and Microsoft are working on their own Arm CPUs, too, alongside Amazon Web Services, which will be debuting its Graviton4 in November if history is any guide.
In its 10-Q filing with the US Securities and Exchange Commission, Intel provided a little more insight into its DCAI business. Intel said that server volumes (which means mostly CPUs but includes some motherboards and chipsets) were down 35 percent in the third quarter, which is a stunning number really and which Intel blamed on “a softening CPU datacenter market.” Which is fair, with the cloud builders and hyperscalers taking a pause as they pour a lot of their money into GPUs for GenAI workloads. Interestingly, thanks to that downshift in sales from the hyperscalers and cloud builders, server average selling prices (ASPs) were up 38 percent, a trend that was also boosted by the adoption of CPUs with higher core counts by all Xeon SP shoppers (including those hyperscalers and cloud builders).
Year to date through the end of the third quarter, DCAI revenues are off 22.5 percent to $11.54 billion, and Intel said in the 10-Q that server volumes are off 41 percent but ASPs are up 17 percent. Sales of FPGAs also helped boost revenues but going forward, despite product launches, Intel seems to be entering a slowing period of FPGA sales. For the nine months, DCAI has an operating loss of $608 million, compared to an operating gain of $1.92 billion against $14.89 billion in sales in the first three months of 2022.
As far as we can tell, Q1 2023 was a local minima for Intel, financially speaking, in the datacenter. It remains to be seen if it is an absolute minima.
Now, DCAI covers a lot of the datacenter business at Intel, but not all of it. Its Network and Edge, or NEX, group also sells gear into the datacenter and its edge extension. In Q3, NEX sales were off 36 percent to $1,45 billion, and operating income was down 77.3 percent to $17 million. For the nine months, NEX sales are off 36.8 percent to $4.3 billion and in terms of profits, has shifted from an operating income of $682 million in the first nine months of 2022 to an operating loss of $470 million in the first three quarters of 2023. Ouch.
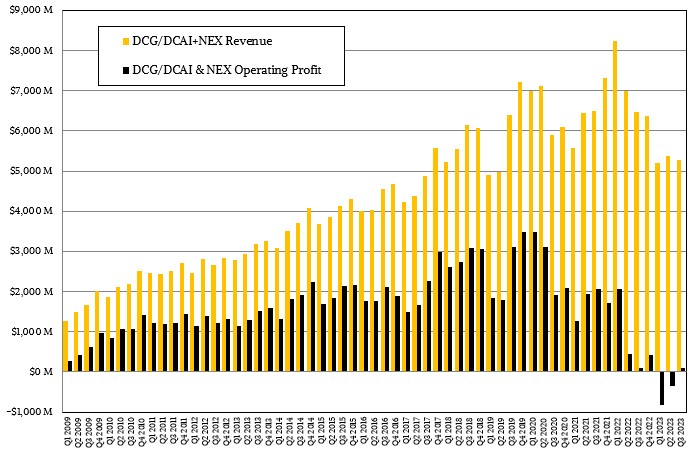
Add DCAI and NEX together and you geta kind of proxy for what used to be called Data Center Group in the old days, and if you add up pieces of the old flash, storage, FPGA, and IoT businesses that Intel used to have, you can get a proxy for what Intel’s “real” datacenter business looked like over time and how it has changed in the wake of product divestitures, product shutdowns, and competitive pressures. Like this:
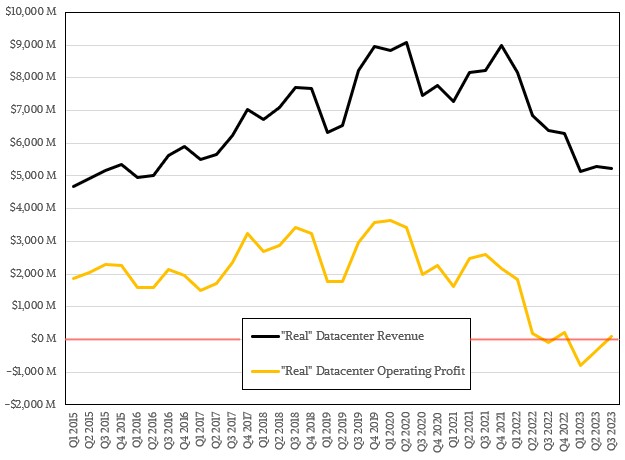
No one watching Intel rise through the 2000s and 2010s would have expected the Intel datacenter business to dip below that red line in the chart above into operating red ink. It seemed, as was said many times in The Princess Bride, inconceivable.
The discontinued Optane 3D XPoint persistent memory, which was used solely in servers, is now part of the Other revenue and operating income – well, operating loss – category, and we are being generous and not trying to allocate a portion of the $2.25 billion in operating losses Intel posted in the Other segment in Q3 2023 to the “datacenter” business as we show it above. Heaven only knows what the losses are for the Accelerated Computing & Graphics (AXG) business that was split up and apportioned to the DCAI and Client Computing (CCG) groups.
Funny how Intel doesn’t really talk about the Ponte Vecchio GPUs, which are deployed in the “Aurora” supercomputer at Argonne National Laboratory, any more. It’s all Gaudi 2 this and Gaudi 3 that and just wait until you see the converged Falcon Shores GPUs with Gaudi matrix math engines and Gaudi fat Ethernet pipes on the chip. . . .
By our math, Intel’s “real” datacenter business is down 19 percent to $51.7 billion and its operating income has been cut in half to $86 million, or 1.7 percent of revenues. That is a far cry from the peak Intel datacenter business, which posted $9.06 billion in sales in Q2 2020 and had an operating profit of $3.43 billion, or about 37.8 percent of revenues.




It is a tough comeback for Intel (from hubris) but I’m quite confident that they’re getting there. The Top500 performance-share of Xeons dropped from 70% (of 1.6 EF/s) in June 2019 to just 27% (of 5.2 EF/s) in June 2023 (with Zen at 50.1% then) as a result of decisions by past leadership. If everything went well last week (HPL submission deadline for Top500) Aurora should bring Intel back up to 37% (of estimated 9.2 EF/s sum) in November 2023 (with AMD still at 50% if El Capitan also tested right).
That’s the right direction to be moving in for Intel, and should be further solidified with Granite in 2024, and Falcon in 2025, in my opinonion (eh-eh!).
November 2015 (8 years ago) was the last time Xeons were #1 in Top500, with Tianhe-2A. This was followed by 6 years of RISC: two each for SW26010, Power9, and A64FX. AMD’s Frontier then brought back the #1 crown to CISC (June 2022) topped with the cherry of largest power-efficiency.
The Battle Royale taking place right now (leading up to SC23) is just so crucial! A TNP-classic trifurcation ( https://www.nextplatform.com/2020/10/22/the-resurrection-of-cray-and-amd-in-a-trifurcating-hpc-space/ )! A fork in the road where competitors need to exhibit their best knives, and suplexes ( https://www.nextplatform.com/2022/10/06/the-art-of-system-design-as-hpc-and-ai-applications-diverge/ )! This most awesome of ballroom blitzes will uniquely determine whether CISC keeps the championship belt or is re-overtaken by RISC (for good?), by Santa’s GH200 rocket sleigh that is the red-nosed Venado, or even by the Alps’ Swiss cheese supergrater of HPC gastronomy! If CISC stays on top, will it be thanks to Aurora’s sleeping beauty, lovingly kissed to harbinger Intel’s reawakening, or to the swashbuckling oldspice strongerswagger of ElCapitan’s masterful sailing abilities, and physique!? Will answers be finally provided at the end of these next 10 excruciatingly long days of atrocious anticipatory agony!? Will it beat being mousified by witches? “Inquisition minds” …
The suspense is thicker than a recreational stratocumulus of herbaceous sativa, right now, in Denver’s thinnest of mile-high broomstick-friendly skies (for folks coming to SC23 from either Salem, MA, or Winston-Salem, NC!)! 8^b
I don’t know the details of your broomstick, but it was sure fun to see a few kids in costumes go from store to store yesterday (café, bakery, …), for free fistfuls of candy, in that French version of Halloween (not quite the North-American house-to-house approach yet … too many Hansel-&-Gretel witches maybe?)!
Speaking of SC23 though, a recent Eviden press release (10/04/23) suggests that 2024’s Jupiter (to be described at SC23) will be a GH200-type affair (Booster rocket), with Rhea1 possibly playing a mostly secondary role (Cluster ammunition) ( https://eviden.com/insights/press-releases/ ). It’ll be a RISC Exaflopper either way, but one may have hoped (unrealistically?) for a more central place for Rhea1 … (?)
“Intel has a relatively weak position in matrix math accelerators with its “Ponte Vecchio” Max Series GPUs ”
Ponte Vecchio has a large matrix math engine and will be used for trillion parameter models at Argonne in Aurora.
The position is not weak because PVC can’t do math. It is weak because the device is pretty hot for the performance it yields and there is not a follow-on coming until 2025 and no one thinks Intel can make it at a reasonable profit due to its complexity and low package yield. You know I know about Aurora, Jay. Show me another customer Intel has talked about even being able to buy PVC. I have not been pitched such a story, and would very much like to see more competitive pressure on Nvidia.
Even if Ponte Vecchio was amazing, Argonne would still be a disaster for how much program slip it’s had. Even the alternate-alternate-backup plan is two years late. The point of the machine isn’t to pass a benchmark, the point is to deliver useful science and it’s still not doing that.
Top500 is clear and concise but GenAI is the Wild-Wild-West by comparison! My summary of MLPerf 3.1, for offline LLM (gptj-99) is:
a) a good CPU (Xeon 8480+, Grace) gives 1 sample/s
b) a good accelerator (Gaudi2, H100) gives 10-12 samples/s
I didn’t see unaccelerated EPYC Zens listed there, nor Instinct devices, unfortunately, but would expect similar performance. If Intel succeeds in weaving (updated) Gaudis into its GPUs, or even Xeons, it should be just fine.
Updated to add: the H100 in b) above, is H100-SXM; Other accelerators are as follows: H100-PCIe = 6 sample/s; A100 = 3 samples/s (PCIe and SXM); TPUv5e = 2 sample/s; Nvidia L4 = 1 sample/s.
Appreciate you all. Thanks.
In my current job position, I’m working on trying to deploy HPC resources for AI on a national scale for a European country. I could easily write a book on the topic at this point and by the time I finished writing it, everything would be old and somewhat irrelevant news. The article is absolutely correct that the two key areas where AI resources are consumed is in training and inference. Beyond that, I have issues with the article.
We’ve worked with AI/ML researchers across Europe to identify their computational requirements for inference and training. Our goal will be to deploy systems which sit comfortably near the top of the Top500, but only when measuring AI results. We will of course employ Lumi at CSC in Finland for a large portion of our workload.
What we learned is that most forms of AI and ML training can run fairly well on run of the mill servers. GPUs help, but while we have more than a few nVidia H100s and AMD MiXXX accelerators and we also have access to some of the world’s largest NVidia DGX clusters, most of the researchers we’re working with don’t need these types of resources. In fact, many run their science on their laptops.
There are a limited number of cases we identified which need HPC resources for training. That includes large language models, diffusion based image processing, etc… effectively only the models which require applying weights based on billions or trillions of source documents tend to need massive processing.
Interestingly, while we haven’t substantiated our hypothesis yet, we believe that a relatively small and inexpensive cluster of special purpose tensor processors (such as those you can run on Google cloud or similar) is possibly exponentially more cost effective than running on general purpose GPUs. The scale should be at least as drastic as comparing CPU to GPU for graphics processing.
Also, training is a short term investment and I personally predict that it is nearly impossible to see a return on investment when building systems for training. It’s also unlikely that paying to power a supercomputer for training a large language model will provide a return on investment. Especially with the expected electricity prices this coming winter.
On the other hand, once a model is trained, there is incredible potential for ROI across many fields in inference. And there are numerous potential use cases for inference and transformation in HPC. But not for the reasons one would typically think.
National or even international scale supercomputing environments are not optimal for AI because we don’t build these machines for a single task to hog for a month at a time. There are certainly oil companies who own their own HPC environments dedicated to weather simulation and exploration, but the massive computers we make have to be shared since there’s no way to pay for such a computer if there aren’t multiple projects benefiting from them. Therefore, running a process that consumes 50% of a super for 3 months would be unrealistic and simply wasteful.
This is ok because if we need to do this, we can just upload to an environment like AWS where rather than building a $100 million computer, we can rent someone else’s for a few hundred thousand dollars and be done with it.
But there are some excellent use cases for ML and GenAI once a model is trained. For example, we can us GenAI to take O(x^n) tasks such as protein folding and, while we are far from having quantum computers today (we’re building a big one now, Lumi-Q), while ML can’t provide as accurate an answer as a real quantum computer in O(x log(n)) time (current quantum computers can’t possibly do that either), we can estimate the outcome in a much shorter time comparable to quantum computers via inference.
For systems like this, it’s far smarter to use something like a Guadi2 system or better yet, a large scale Huawei Atlas 9000 system than a bunch of H100’s, DGX, MI250s… but keep in mind that the technology is moving so impressively fast that I’m quite sure that in the next year or two we’ll see developments in this field which completely change how we handle neural networks.
My thoughts on this is a play on other quotes. All it will take is some kids sitting in a garage… maybe in Ukraine to make a new innovation that squashes all the AI efforts from Google, Microsoft, AWS, OpenAI and more. And I think it’s going to happen sooner than later.
No, there is not.
If Intel is counting on AI inference to save Xeon, why isn’t there a Xeon Max version of Emerald Rapids with High Bandwidth Memory (HBM)? The performance of large language model inference is limited by the bandwidth of reading neural net weights from DRAM, not by arithmetic. The arithmetic for large language model inference is just one 8-bit x 8-bit integer multiply accumulate per byte read from DRAM.
They want to use double-pumped DDR5 memory instead. I think it is called MCR. We’re going to dig into it. Emerald Rapids is a stop-gap. The real show is Granite Rapids.
I agree Emerald Rapids is a stop-gap. The next big step forward from Intel is Granite Rapids. Multiplexer Combined Ranks (MCR) DIMM supported by Granite Rapids is much slower than HBM. NVIDIA is currently getting 5 TBytes/sec from 6 stacks of HBM3e. The second generation HBM3e, which is already sampling to NVIDIA and AMD, has 1.2 TBytes/sec per stack and 7.2 TBytes/sec per 6 stacks. 12 channels of MCR-DIMM is only 860 GBytes/sec, which is 8.4x slower than 7.2 TBytes/sec. Granite Rapids will not be competitive for large language model inference if all it has is 12 channels of MCR-DIMMs. Intel needs a Xeon Max version with 6 stacks of HBM. Even AMD has an HBM version of Turin, which is their server processor after Genoa. Unlike AMD and NVIDIA, Intel does not have the TSMC supply constraints for packaging HBM with Xeon.
Very insightful article — both the technology involved and associated business aspects. I have no doubt Gelsinger finds your Intel datacenter business revenue chart as “inconceivable” as you do. But the whole GenAI effort is on the wrong track. The underlying need is for a novel inference architecture, combined with a fundamental change in training algorithms. There is zero chance the human brain, in 40 W, is performing complex math (e.g. gradient descent) with a level of numerical accuracy and error free calculation required by Big AI algorithms. Huge amounts of memory params are fine if access can be slow and errors allowed — rather than wasting power hungry circuitry on EDAC and every possible incremental tick in bandwidth. Big AI, instead of striving for efficiency, which evolution prizes above all else, strives for continuously increasing capex, energy usage, and complexity. I guess that increases the width of their moat, but it doesn’t come anywhere close to matching the human brain.
Well put.