

Predicting the future is hard, even with supercomputers. And maybe specifically when you are talking about predicting the future of supercomputers.
As we noted many years ago, the fact that AI training workloads using convolution neural networks came along with enough data to actually start working at the same time that the major HPC centers of the world had been working with Nvidia for several years on a GPU offload approach for simulation and modeling was a very happy coincidence. A harmonic convergence, as we called it at the time, that this massively parallel processor could do both HPC simulation and modeling and AI training.
But only five years into the AI revolution, which began in earnest in 2012 when image recognition software could beat the accuracy of human beings performing the same task, we were wondering if this happy overlap between HPC and AI could last. And in the summer of 2019, in the wake of the iterative refinement model work done to use mixed precision math units to get to the same answer as FP64 compute on the Linpack benchmark and ahead of Nvidia’s “Ampere” GA100 GPU launch the following spring, we took another run at this HPC-AI divergence idea. And that was before we saw the balance of vector core and tensor core computing in the Nvidia “Ampere” A100 GPU accelerators was going to heavily emphasize AI training on mixed-precision Tensor Cores, with HPC workloads using FP64 vector units taking a bit of a backseat in the architecture. We thought it could go either way, and said as much.
With the “Hopper” GH100 GPUs that Nvidia launched earlier this year, that gap between generational AI performance and HPC performance improvements opened up even wider, and not only that, in the recent fall GTC 2022 conference, Nvidia co-founder and chief executive officer Jensen Huang, said that there was a divergence happening in the upper echelons of AI itself – one that has compelled Nvidia to get into the CPU – or what we might call a glorified extended memory controller for the GPU – business.
More on that in a moment.
I Came To A Fork In The Road When What I Needed Was A Knife *
Let’s start with the obvious. If Nvidia wanted to make a GPU that had great gobs of FP64 performance, therefore allowing existing 64-bit floating point HPC applications like weather modeling, computational fluid dynamics, finite element analysis, quantum chromodynamics, and other math heavy simulations, it could make such an accelerator. Nvidia could make one with no Tensor Cores at all, and no FP32 CUDA cores as well, which do double time as shaders for graphics work in the CUDA architecture.
But that product might have hundreds of customers per year, and each chip might cost many tens of thousands to hundreds of thousands of dollars, including designs and manufacturing costs. To create a larger and ultimately more profitable business, Nvidia has had to create a more general purpose architecture that only had to beat the tar out of CPUs for vector math.
And so, as Nvidia chased HPC applications starting in earnest 15 years ago, it had to focus on HPC applications that used FP32 floating point math – certain seismic processing, signal processing, and genomics workloads use single-precision data and processing – and gradually boost the FP64 capability of its GPUs.
With the K10 accelerator, based on a pair of “Kepler” GK104 GPUs, launched back in July 2012, which was the same GPU used in gamer graphics cards, it had 1,536 FP32 CUDA cores and did not have dedicated FP64 cores at all. The FP64 support was done in software and did not deliver very much performance: 4.58 teraflops across the pair of GK104s at FP32 versus 190 gigaflops at FP64, which is a ratio of 24 to 1. With the K20X, based on the GK110 GPU and launched at the end of 2012 at the SC12 supercomputing conference, the FP32 performance was 3.95 teraflops versus FP64 at 1.31 teraflops. The ratio here was 3 to 1, and this was a usable accelerator for HPC applications as well as those who were starting to play with AI applications in academia and at the hyperscalers. The K80 GPU accelerator card, based on a pair of GK110B GPUs because Nvidia didn’t add FP64 support to the high-end “Maxwell” GPUs, was wildly popular and offered excellent price/performance for the time. FP32 performance of the K80 was 8.74 teraflops and FP64 was 2.91, a 3 to 1 ratio again.
With the “Pascal” GP100 GPUs, the HPC and AI gap opened up with the addition of FP16 mixed precision, but the ratio of vector FP32 to vector FP64 was reduced to 2 to 1, where it has been ever since through the “Volta” GV100, “Ampere” GA100, and “Hopper” GH100 generations of GPUs. And with the Volta architecture, Nvidia introduced Tensor Core matrix math units, with fixed matrix sizes, that significantly boosted floating point (and sometimes integer) processing over the vector units that were still part of the architecture. And the gap between FP64 vector processing got even larger.
As these Tensor Cores have been made to handle larger and larger matrices and as the precision has been lowered and lowered, the effective throughput of AI processing on these machines – enabled because of the fuzzy statistical nature of machine learning itself, which stands in stark contrast to the high precision math of many HPC algorithms – the gap has gotten larger and larger. This illustrates the AI and HPC performance gap on a log scale so you can see the trends:

But if you really want to feel the difference, you have to look at it on a normal scale:
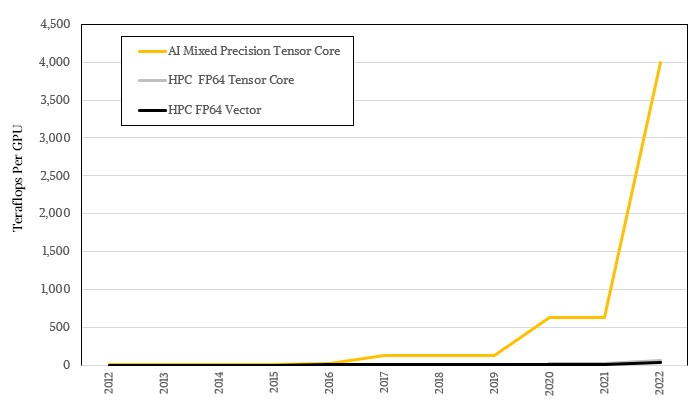
Not every HPC application has been tweaked to use Tensor Cores, and not every application can move its math to Tensor Cores, and that is why distinct vector units are still in the Nvidia GPU architecture. And not every HPC organization can come up with iterative solvers like the HPL-AI solver put inside the Linpack benchmark, which takes normal HPL Linpack and uses FP16 and FP32 math and a tiny bit of FP64 to converge to exactly the same answer as a pure, brute force FP64 calculation. This iterative solver is now providing a factor of 6.2X effective speedup on the “Frontier” supercomputer at Oak Ridge National Laboratories and 4.5X on the “Fugaku” supercomputer at RIKEN Lab, and is running at anywhere from 8.3X to 10X on other relatively large machines. It would be nice if more HPC applications were like HPL-AI, and maybe someday they will be.
But in the meantime, for a lot of workloads, FP64 performance is important and Nvidia is making much, much more money chasing AI with its GPUs.
Two Roads Diverge, And Then Fork Again
And so, as you can see, the architecture has leaned heavily on boosting AI performance and delivering enough HPC performance to keep customers buying new iron every three years. If you look at pure FP64 performance, between 2012 and 2022, the FP64 throughput of Nvidia GPUs has grown by 22.9X from 1.3 teraflops on the K20X to 30 teraflops for the H100, and if you can use the Tensor Core matrix units, then the delta is 45.8X. But if you have been riding the Low Precision Express downhill from FP32 to FP8 for AI training, then the performance increase has gone from 3.95 teraflops at FP32 to 4 petaflops with FP8 sparse matrix support, a factor of 1,012.7X if you want to be precise. And if you were coding your AI algorithms in FP64 back on those K20X GPUs back in the day – and people were in many cases – then the performance increase over that decade is double that.
That is a huge divergence in performance. And now, AI is splitting into at least two, according to Huang. Transformer models, which are the huge foundation models that underpin natural language processing, sometimes called large language models, are driving up parameter counts and driving the need for ever more powerful hardware. Transformers are in another league compared to the neural network models that have come before them, as you can see here:
![]()
This chart is a little fuzzy, but here is the gist: For the first set of AI models that did not include transformers, the compute requirements grow at a rate of 8X over two years. The transformers are growing their computational needs for training at a rate of 275X over two years. We will need to be at fractional bit precision with 100,000 GPUs in a system to meet this need. (That wasn’t serious.) But moving to FP4 precision might happen to get 2X, and boosting the size of the GPU by shrinking transistors to 1.8 nanometers will happen, which gives another 2.5X or so. So that leaves only another 55X of more compute to come up with. FP2 processing (if such a thing could even work), would drop that in half, but you are still talking about needing something like 250,000 GPUs instead of 10,000 GPUs. (We are still kidding. We hope.) Large language transformer models look like an exceedingly hard thing to scale. It looks economically unfeasible, if you want to be honest. It looks like a rich company’s game only, akin to having nuclear weapons being only a rich country’s game.
Recommendation systems, which are “the engines of the digital economy,” as Huang put it, don’t just need exponentially more compute, but they need more memory than a GPU can ever have and more memory than large language models require. Here is how Huang characterized it in his GTC keynote a few weeks ago:
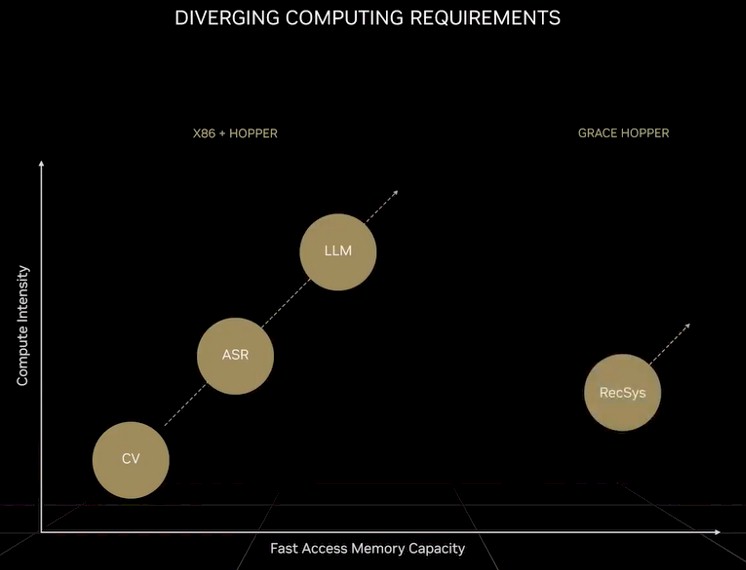
“Compared to large language models, the amount of data moved, for every unit of computation is an order of magnitude larger,” Huang explained. “You can see that recommender systems require an order of magnitude more fast memory capacity. Large language models will continue to grow exponentially and require more computation over time. recommender systems will also grow exponentially, and will require more fast memory capacity over time. Large language models and recommender systems are the two most important AI models today. And they have diverging computing requirements. Recommenders can scale to billions of users and billions of items. For example, every article, video, and social media item has a learned numerical representation called embedding. Each embedding table can be tens of terabytes of data that requires multiple GPUs to process. Processing recommenders require data parallelism in parts of the network and model parallelism in other parts of the network, stressing every part of the computer.”
Here is what the architecture looks like:
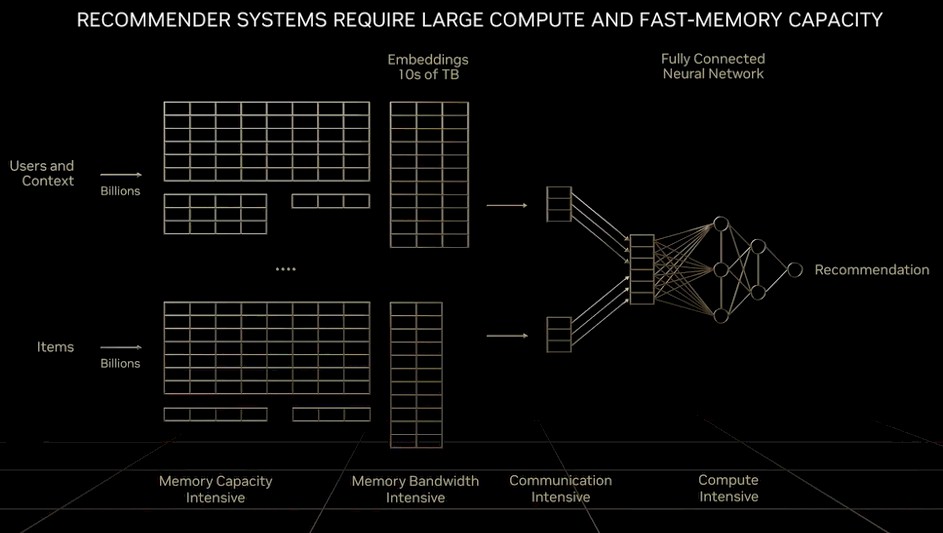
To solve this particular memory capacity and bandwidth problem, Nvidia created the “Grace” Arm server CPU, and coupled it tightly to the Hopper GPU. We have been joking that Grace is really just a memory controller for Hopper in cases where more main memory is necessary, but in the long run maybe a bunch of CXL ports running the NVLink protocol hanging off a HopperNext GPU will do the trick just fine.
It’s great that a baby CPU-only cluster is buried inside of a monstrous GPU-accelerated cluster when companies use the Grace-Hopper superchip. Those Arm CPUs can support legacy C++ and Fortran workloads. But at what cost? The CPU portion of a hybrid cluster will have a factor of 10X less performance than the GPU side of the cluster and cost somewhere between 3X and 5X as much as a plain vanilla CPU-only cluster.
And by the way, we are not disrespecting any of the engineering choices Nvidia has made. Grace is a fine CPU, and Hopper is a fine GPU. They are clearly better together. But now we have three diverging workloads on the same platform, pulling the architecture in different directions, and economics does not allow for absolute optimization on these three very different vectors: HPC, LLM, and RecSys.
What seems clear to us is that the AI tail is wagging the HPC dog, and has been for nearly a decade now. If HPC wants to transform itself, the code has to look a lot more like a recommendation system and a large language model than it does existing C++ and Fortran code running on a straight FP64 flops box. And it is also clear that HPC customers will pay a premium compared to what AI customers do per computation unless HPC experts figure out how to do more iterative solvers. We leave it to the experts to figure out how to model the physical world in lower precision.
Our contention, for many decades, has been that nature itself doesn’t actually do math. We are stuck using high precision math to describe what nature does because we are the ones that don’t understand. Maybe, just maybe, nature does more intelligent guessing than we want to admit, and statistical, iterative solvers are closer to the reality that we think we are modeling. This could turn out to be extremely fortunate, moreso even than the initial convergence of HPC and AI a decade ago, if it can be done.
It is perhaps best to keep in mind the warning of poet Robert Frost:
“I shall be telling this with a sigh
Somewhere ages and ages hence:
Two roads diverged in a wood, and I –
I took the one less traveled by,
And that has made all the difference.”
*Editor’s Note: I have been saying that line for decades. You have my permission to use it.

How To Build A Better “Blackwell” GPU Than Nvidia Did
While a lot of people focus on the floating point and integer processing architectures of various kinds of compute engines, we are spending more and more of our time looking at memory hierarchies and interconnect hierarchies. And that is because compute is easy, and data movement and memory are getting …
Different GPU Horses For Different Datacenter Courses
If the semiconductor business teaches us anything, it is that volumes matter more than architecture. A great design doesn’t mean all that much if the intellectual property in that design can’t be spread across a wide number of customers addressing an even wider array of workloads. How many interesting and …
Large-Scale Weather Modeling Shows What True HPC Networking Can Do
The Korean Meteorological Administration (KMA) operates 20+ numerical weather prediction (NWP) models, including Korean numerical models, for weather forecasting. Large-scale compute is certainly a critical factor in its operations, but with vast computational capability comes the need to balance it with ultra-high performance networking. Over the years, the KMA has …
Very nice piece! I think that this three-pronged pitchfork in the road (combining fork and knife) has been sparking innovation in HPC algorithm research, to take advantage of GPU (accelerators) capabilities, beyond pure parallelism, towards mixed-precision speedups. It is challenging, because, for example, single precision Runge-Kutta doesn’t generate closed orbits in phase-space for solutions of the Lotka-Volterra system (it produces spirals, which is incorrect). But mixed-precision Runge-Kutta (FP32+FP64), applied to the Van Der Pol system (nonlinear, cubic) is reportedly accurate and faster than a purely FP64 implementation. Mixed-precision iterative refinement solvers (FP16 to FP64) also seems quite accurate, faster, and more energy efficient, than pure FP64 methods. There is definitely productive cross-fertilization between hardware advancements for AI/ML/gaming (where the bulk of financial rewards lie) and algorithm development for HPC (where most benefits to humanity are located) I think. Mixed-precision HPC is still mostly research today, but has great potential for mainstreaming (the benefits are huge where it is both stable and accurate). Quantum computing, with its half- and 3/4-bits, may yet further revolutionize HPC, but that will be in a future that cannot be fully observed, without modifying it!
Don’t mitigate. Eliminate.
No hotspots!
HotGauge: A Methodology for Characterizing Advanced Hotspots in Modern and Next Generation Processors
https://sites.tufts.edu/tcal/files/2021/11/HotGauge_IISWC_2021.pdf
NNShim: Thermal Hotspots Simulation on ML Accelerators
https://sites.tufts.edu/tcal/files/2022/06/ISCA22_HSSB_paper_5.pdf
Exactly. The idea of modeling say the earth’s entire weather system in SOTA FP64 models is impossible with today’s technology, or tomorrow’s for that matter. So these models compromise both reach and fidelity. OTOH, the Earth-2 digital twin model and system Nvidia is building will do just that at both higher fidelity and provide a global reach. (https://www.forbes.com/sites/karlfreund/2022/04/03/nvidia-earth-2-leveraging-the-omniverse-to-help-understand-climate-change/?sh=4d904625491f) One can only get there with mixed precision computation and ML. The number of HPC environments succumbing to ML will only increase in time.
I see, “Fourier neural operator” (for PDEs), that may be what Tim was hinting at: “nature itself doesn’t actually do math […] maybe […] more intelligent guessing” — an alternative to domain and equation discretization (maybe ADI), reordering (reverse Cuthill-McKee), linear algebraic system solution (matrix). Interesting research (if it works…)!
Nice article TPM. Look forward to seeing you at SC22