

Other than Hewlett Packard Enterprise, who wants to build the future NERSC-10 supercomputer at Lawrence Berkeley National Laboratory or the future OLCF-6 system at Oak Ridge National Laboratory? Anyone? OK, yes, we see you, Microsoft, and you, Amazon Web Services, raising your hands at the back of the room. Yes, we see you. Put your hands down, please. Anyone else?
Yeah, that’s what we thought.
Lawrence Berkeley put out the request for proposal technical requirements for the kicker to the current “Perlmutter” system on September 15, and Oak Ridge followed suit with its RFP technical requirements for the kicker to the “Frontier” system on September 27, and we can’t help but wonder what kinds of options both labs, and indeed any of the US Department of Energy national labs, has when it comes to acquiring their next-generation supercomputers.
Intel has had quite enough of being a prime contractor for supercomputers, and chief executive officer Pat Gelsinger has come to his senses and stopped talking about reaching zettascale – 1,000 exaflops – by 2027. Gelsinger dropped that mike on the stage two years ago talking to us at a briefing, and we did the math that showed if Intel could double the performance of its CPUs and GPUs every year between 2021 and 2027, it would still take 116,000 nodes and consume 772 megawatts to achieve zettascale. As far as we can tell, that mike drop broke the mike. And the Raj.
IBM is done with being a prime contractor, too, after losing money building massive machines in the past, and has focused on AI inference as its key HPC workload. Years ago, Nvidia and Mellanox worked independently with IBM on pre-exascale systems, which were installed at Lawrence Livermore National Laboratory and Oak Ridge, and at some point, Nvidia was making so much money from AI training that it no longer needed to care about HPC simulation and modeling like it did from 2008 through 2012. If Nvidia doubled its HPC business, it would have barely showed up in the numbers in 2019 and 2020, and these days, it would be a rounding error thanks to the generative AI explosion.
There is no way that Atos or Fujitsu can sell into US government labs. Dell could do it, but its stomping grounds at the University of Texas seem to be enough to whet its HPC appetite and to wave the American flag patriotically. (Michael Dell doesn’t like to lose money.)
Who is left? Yes, we see you, Microsoft and AWS and even Google. But you have your own issues, as we have recently reported, and among them is you talk big but people can’t really rent big. The perception of infinite capacity, with an easy on and easy off switch, is largely an illusion – especially at the scale of national supercomputing centers that will need tens of millions of concurrent cores to do their work and networks that interlink them at high bandwidth and low latency.
Lawrence Berkeley – and specifically, the National Energy Research Scientific Computing Center at the lab – put out a request for information from vendors regarding its NERSC-10 machine back in April, in which we did some prognosticating and complaining, and we are not going to repeat all of that here. We will show you the supercomputer roadmap at the lab as a reminder, however:
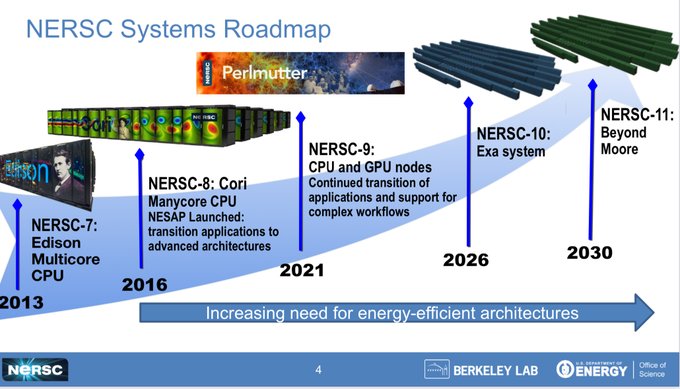
The RFP technical requirements document is not the RFP, but kind of a preview to get the juices going amongst those who will try to compete for the right to break even on the deal. The RFP for NERSC-10 will come out on February 5, 2024 and after a period of time for questions and answers, the proposals from vendors will be due on March 8, 2024. An early access machine has to be delivered in calendar 2025, the NERSC-10 system has to be delivered in the second half of 2026, and the system acceptance – and therefore when the prime contractor gets paid – is anticipated to happen in 2027.
The technical documents are a long shopping list of features and functions, but there is not much in the way of precision because Lawrence Berkeley is trying to keep an open mind about open architectures and complex HPC and AI workflows and their interplay. Nick Wright, leader of the Advanced technologies Group at Lawrence Berkeley and architect of the NERSC machines, gave a presentation at the recent HPC User Forum meeting saying that HPC was at an inflection point and that the HPC industry and the HPC community – these are not the same thing, according to us – need to deal with the end of Moore’s Law and the rise of AI.
The goal is for NERSC-10 to deliver at least 10X the performance of Perlmutter on HPC workloads. Lawrence Berkeley has a suite of quantum chromodynamics, materials, molecular dynamics, deep learning, genomics, and cosmology applications that are being used to gauge that 10X performance boost. We get the distinct impression that if a massively parallel array of squirrels running on mousewheels with abacuses in their front paws for doing calculations delivered better performance and better performance per watt than a hybrid CPU-GPU architecture, then all of the national labs would be buying up peanut farms and designing datacenters that looked like commercial chicken coops from days gone by built as an array of treehouses.
Four years ago, Hyperion was saying that saying that NERSC-10 would weigh in at somewhere between 8 exaflops and 12 exaflops of peak petaflops, but was also saying that Frontier would ne somewhere between 1.5 exaflops and 3 exaflops peak and that El Capitan at Lawrence Livermore would be between 4 exaflops and 5 exaflops. Take a lot of salt with that. And you won’t be able to see how far that is off from reality because no matter what the NERSC-10 machine ends up being, Wright says the RFP will not have a peak flops measure. Wright added that Lawrence Berkely is trying to expand the pool of vendors, including those who have not responded to a “leadership class” RFP from the US Department of Energy before.
The NERSC-10 RFP technical document are short on details – sadly – but the proposed system has to fit within a 20 megawatt maximum power draw and fit in a system footprint of 4,784 square feet. This being NERSC, energy efficiency is of the utmost importance, and it goes without saying that the machine has to be water cooled given the heat density of that tight space. (Just like Perlmutter is.)
Some 2,465.8 miles just a little south of due east from the communal hills of the University of Berkeley is Oak Ridge, nestled in the wild hills of eastern Tennessee. And that is where the RFP technical document for the OLCF-6 system was released to give HPE and any competition that might want to come up against it a chance to think about bidding on NERSC-10 and the OLCF-6 kicker to Frontier at the same time.
Here is an old roadmap that suggests what the goals for Frontier and its follow-on would be back in 2019 or so:
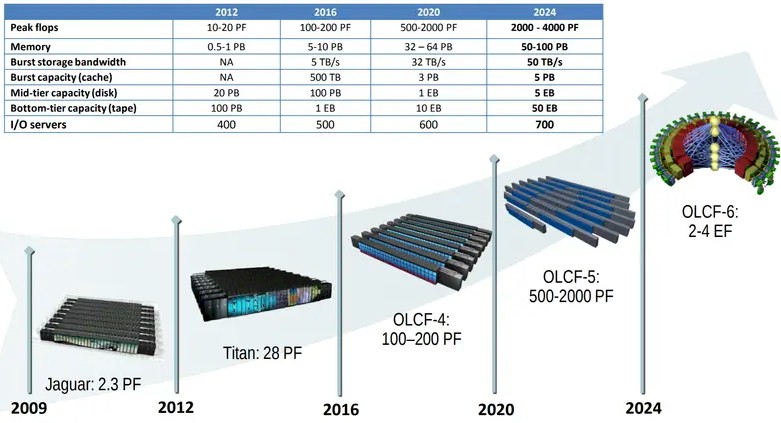
The “Summit” OLCF-4 machine hit its top-end performance target, and the Frontier OLCF-5 machine almost hit its top-end. If you assume that the machines launched in the middle of those time frames, then they are right on track with deliveries in 2018, 2022, and expected in 2027. But the “Jaguar” system was delivered in 2009 and “Titan” came in 2012, so the lines were the expected dates when this roadmap was drawn, probably sometime in 2014.
It’s OK. Everybody’s HPC roadmap was stretched a few years, and we think it will stretch even further, under the influence of the gravity of the Moore’s Law situation, in the next ten years.
Anyway, way back then, OLCF-6 was expected to weigh in at somewhere between 2 exaflops and 4 exaflops peak, with history guiding that up to 4 exaflops. The RFP technical requirements document says that by 2028, Frontier will be nearing its end of life. Before that day comes – specifically, in 2027 – OLCF-6 needs to be in place. Oak Ridge is willing to take bids for an upgrade to Frontier, whole new system designs, as well as off-premises systems – by which we presume it means hyperscalers and cloud builders. Oak Ridge is also welcoming bids on a parallel file system and an AI-optimized storage system separately for those who want to do that. (That means you, DataDirect Networks and Vast Data.)
Oh, and by the way, if the Frontier successor is not located in the state of Tennessee, there is a 9.75 percent sales tax that has to be part of the bid. So, say welcome to the US-East Knoxville datacenter region. . . .
Whatever the successor machine, it has to fit in a 4,300 square foot area in the Oak Ridge datacenter and it has to fit in a 30 megawatt power draw. There is no target as yet to application performance, but the list of applications in the OLCF-6 benchmark suite – LAMMPS, M-PSNDS, MILC, QMCPACK, SPATTER, FORGE, and Workflow – that covers a lot of the same bases as the NERSC-10 benchmark suite in HPC simulation and AI training.
It is hard to imagine that anyone but HPE will bid on these deals, but the government has to have more than one bidder. It may have to create one at this point, which is something we suggested in covering NERSC-10 earlier this year.
The real inflection point, and the question it drives, is whether HPE peddling an on-premises system can beat out Microsoft or AWS in winning these two deals. The cloud builders would have to do some things differently – acting more like a hosting company than a cloud, investing in real HPC interconnects that provide good performance on both HPC and AI workloads, and so on – but they may be the only ones who have deep enough pockets to do the job to push higher than exascale.
The only trouble is, they won’t do it at cost or less like SGI, IBM, Intel, and HPE have done in the past. This is a real quandary, particularly if AMD no longer needs Uncle Sam as an investment partner in its CPU and GPU efforts, as it most definitely did for the Frontier and El Capitan machines. Immunity from prosecution and the ability to build monopolies are something that the US government can trade to get its HPC/AI supercomputers on the cheap, but we don’t hear anyone talking about such a bold quid pro quo. Yet.




Aloha Timothy Prickett Morgan, and DOE. YES, “energy efficiency is of the utmost importance”; that and eliminating advanced hotspots (ref Tufts U HotGuage) THEREFORE -> 1000 times more efficient computation: “Oscillator for adiabatic computational circuitry”, “…an energy reservoir, the missing aspect of previously attempted adiabatic computational systems..”., (US11671054) Patent Granted on: 2023-06-06. September 2nd, 2023, Earth ICT, SPC license to make, have made, use , and sell. Earth ICT, SPC will compete fro the business. Mahalo, Art Scott Earth ICT, SPC, Fonder, Director, CEO. FYI Recommend industry SWOT https://labpartnering.org/patents/US11671054
Nice analysis. These DOE RFPs have a bit of a whiff of commoditization, privatization, and subcontracting, of the Fed’s Exascale HPC, as seen also in the space field with NASA, SpaceX, and Blue Origin. The outcomes could be gooey, or flaky, I think …
These are so definitely NOT leadership class targets (in my mind): 10x Perlmutter in 20 MW for NSERC-10, and 2-4 EF/s in 30 MW for OCLF-6. Frontier already bests NSERC-10, and, right-around the corner, ElCapitan, Aurora, and Venado, will best OCLF-6 (essentially).
I think the goal here (as I believe you are also suggesting) is to foster development of free-market enterprises of HPC/AI/ML computational infrastructure (eg. dedicated cloud), or test the waters for related enthusiasm from hyperscalers. Market-dynamics would then regulate the development and availability of related computational machinery, tree houses, chicken coops, peanut farms, and mousewheeling squirrel abacuses (expressed in units of Exaflopping equivalents) — if I misread correctly. (eh-eh-eh!)
Something akin to the model of the Cerebras UAE G42 deal, but with a stronger DOE component?
Spreading “original innovation capability” more broadly beyond Fed Lab cubicles … sounds great from an international competition perspective — the Thai chicken satay of HPC gastronomy (plus squirrel abacuses)!
Historically leadership-class supercomputers are big and all nodes the same. Such homogeneity has been important for leadership-class problems that simultaneously run on a large percentage of the system.
There is a growing variety of special purpose accelerator hardware and at the same time a growing desire to perform digital twin and multi-physics simulations. Such simulations might couple AI, traditional HPC, databases and other types of tasks together. Different types of accelerator hardware is better suited to each of those different tasks.
In particular, once the scope becomes post exascale the problem becomes heterogeneous. A heterogeneous problem suggests a heterogeneous type of supercomputer made from an assortment of different computational nodes.
The point is such a supercomputer does not need to be replaced all at once by a prime connector, because there is no need for all nodes to be the same. Instead it can updated in smaller steps without as much risk.
The gov’t is going to have to pay more, and perhaps place less faith in future product?
If MS/AWS/Google are going to cost an arm and a leg then what is the reason for not spending that money at HPE or Dell – companies that know how to build w super already. Make it profitable for them, eh?
As you say, a great big cloud is not an HPC super. Asking a cloud builder to build the biggest super ever seems like the most expensive and most risky option.
The compelling things that the cloud vendors offer are
1) their buying power – about the only thing big enough to get nvidia to come down on price a little bit
2) their efficiency of operations – the compute engine isn’t going to be any better, but they may be able to drive down the labor costs of running the thing (though will likely demand it back in margin)
3) Any custom AI innovations they were planning on investing in anyway.
The networking techs and the storage techs/topologies used in a supercomputer are different from those used in clouds. Clouds are more focused on composability and general purpose applicability whereas supercomputers are more focused on raw performance on a relatively small basket of applications. This is why it is risky to ask a cloud builder to build your super. The cloud builders should show they know how to do it on some contracts smaller than the next round of national supercomputers.
Buying power, IDK that that even makes sense. When the national labs commission new supers part of what they are doing is industrial policy. Intel latest round of XEON CPUs and AMD latest round of GPUs+ROCm – paid for in large part by supercomputer contracts. Hell, AMD doesn’t really pay attention to GPU comoute for the SME market because it’s customer was the Frontier contract.
Right on! AMD should definitely make sure that it doesn’t completely lose the plot on the youthful enthusiasm and energy generated by consumer GPUs for gaming (even as it meditates over enhanced HPC/AI archs). NVIDIA’s highly productive PhDs were very likely these same gaming kids just a couple of years back, and the many folks who code in Cuda today likely got their (minimum risk) start on “inexpensive” laptop and desktop cards, and now keep using that tech by familiarity of habit.
Kids are the future, gotta get them hooked early, and often (to tech; not drugs!)!
One can imagine a setup where Ratheon or General Dynamics bid on these proposals, and the hardware comes from dell or supermicro. That of course might happen if the margins were 60% or so. Of course, if the margins were that high, Cray and SGI might still be around, and IBM might still be in the HPC business. Nvidia is probably also in the mix. They probably don’t want to be the prime contractor, but they have to keep pressure on HPE (and the cloud teams). They can probably afford to take a loss on one deal, if it keeps everyone else scared about component pricing.
A very good point, Paul. But the margins on these machines are nil. Look at SGI, Cray and HPE’s HPC & AI numbers. The revenue is there, but over the long term of a decade, you show me even a few percent of revenue as profit.
Nvidia showed no interest the last several times I talked to Jensen.
Oracle might be a serious potential bidder for Next Generation HPC systems. They have deep pockets and experience with government bids. But they certainly wouldn’t it on the cheap.
On a less serious note, maybe Elon Musk might bid. He doesn’t seem to mind losing money. Not that the government would award him the project, but he could at least be the required second bidder, so that the government could award it to HPE.
Or maybe Elon Musk
These roadmaps are too much DOE, meh, bleh, incremental, boring; not enough MiB-level excitment for my attention span! Where are the men who stare at goats? The 3-D VR RayBan ML astrologies? The quantum photovoltaic AI banjos? The non-deterministic parapsychology metacomputing units? The time-traveling fluxonium capacitors? Are we wallowing in the middle of a deepening trough of unimaginativeness in HPC solicitationship? “Inquisition minds” … 8^b
Government is a funny thing, huh? A market analysis would suggest that in cases where the government is a big customer they should get their goods and services with low margins and where they are a small customer they should expect to pay more. But the reality is the opposite. They dole out trillions to defense and pharmaceutical companies who make massive margins on revenue that is significant – even majority – of the companies’ totals and want at-cost service on expenditures 1/1000th the size that are a miniscule part of their suppliers’ revenue. Just have to wonder what it takes to make the gears run backwards that way. Couldn’t have something to do with a little bit of those trillions of dollars leaking out in particular directions here and there, could it?
I think that the U.S. Department of Energy’s current conundrum of having a hard time finding more than a one potential bidder for its next generation national lab HPC systems shows an extreme lack of strategic thinking on the part of the government’s various departments and officials over the years. When the Reagan administration came to power, they decided that their FTC/DOJ Anti-trust Division was just going to stop enforcing most anti-trust laws and be “pro-business” (keep in mind that the AT&T anti-trust case started under an earlier administration). The Clinton administration went further, and relaxed anti-trust enforcement with defense contractors. We used to have quite a few HPC-capable computer companies, high-speed interconnect companies, parallel storage companies, etc., but with such a lax regulatory environment they were allowed to start eating each other. HPE alone has within it the consumed and long-digested remnants of DEC, Cray, and SGI inside it. Heck, Intel, AMD, and nVidia have also bought out interconnect companies, FPGA companies, and more to help themselves vertically integrate. The U.S. National Lab supercomputers are crucial to keeping the U.S. on the forefront of leading the world in technological advancement. I frustrates me that no one at the FTC/DOJ Anti-Trust Division was apparently keeping an eye on all of these mergers and acquisitions over the years to make sure that we still had plenty of independent entities left for guaranteed healthy competition, multiple bidders for every contract, and second-sources of parts and technology if need be. While HPE has made some incredible HPC systems, it’s too dangerous to leave all of the nation’s eggs in one corporation’s basket. For competition and innovation’s sake, the market should have never been allowed to become this consolidated in the first place.
Could not agree more. We have one vendor that will win all the deals (HPE) and still not make any money and another vendor (Nvidia) that won’t play because it won’t make any money and another vendor that stopped playing because it can’t afford to not make money (IBM).
It’s market conditions. The national lab-style supercomputer market has not grown much in the last 40 years. The computing market has. And more recently an even bigger shift has happened. The center of mass of HPC is now AI. In fact traditional supercomputing is like a moon around a planet around the sun with AI being the sun. It’s just a different ballgame now. Who exactly do you see surviving in the market and servicing the DOE if the US government had stepped in and prevented consolidation? Pensando? Mellanox? Surely HPE bought Cray it apply its technology to larger revenue streams than Cray was chasing itself. If HPE hadn’t been allowed to buy Cray how long would HPE have continued to make bids? Regardless, one must not lose sight of the forest for the trees. The government involving itself with markets of hundreds of billions if not trillions of dollars per year of revenue so that it can get better deals on its own $1 billion a year of purchases would certainly be terrible governance. Risking hamstringing the American tech sector would be far more dangerous than having a conundrum for getting cheap supercomputers. Maybe they have to pay market prices…?
That’ll be two more reasons for TNP Experts to absolutely and definitely attend SC23 Denver (Nov.12-17), press-passes in hand, and bring us the mile-high straight dope on this cloud/HPC (not THC) up-in-smoke yin/yang situation, as a live in-person update to the “Clouded Judgements” piece (TNP’s 09/27/23):
From ORNL, Sandia, Argonne, LBNL, LLNL, NASA, Google, Amazon, and Microsoft: Integrating Cloud Infrastructure with Large Scale HPC Environments ( https://sc23.supercomputing.org/presentation/?id=bof222&sess=sess342 )
and from LLNL, UTK, IBM, Google, and Amazon: HPC and Cloud Converged Computing: Merging Infrastructures and Communities ( https://sc23.supercomputing.org/presentation/?id=pan110&sess=sess193 )
There’ll even be some discussion of “Magic Castle” (from Quebec) and “SuperCompCloud” (Hoosiers & Euros) to further round things up! 8^b
It’s ironic that the drive of commodity hardware and services by the feds has gotten us to a single viable(?) source for leadership computing.
I have been around as a contractor for almost 20 years in the space. I have seen the feds squeeze every dollar out of the suppliers as well as poach talent from the contractors. Maybe we are closing in on a point where the design and integration (and risk) will have to be done by the feds and the RFPs are for the building blocks at the component level. 🙂