

There are a lot of new technologies that are available now or are going to be available shortly that have the potential to radically change the compute, memory, and storage hierarchies in systems. It is a great time to be a system architect, given all of the component and interconnect choices.
But the interesting bit, as far as we are concerned, is not that potential. It is what happens when smart people who use real systems make choices and the inevitable compromises to move the state of the art in high-end computing forward. This is why we find machines like the future “El Capitan” exascale-class system at Lawrence Livermore National Laboratory so fascinating. This lab, like several others around the world, helps define and develop and deploy the future that the rest of us will eventually live, every bit as much as any hyperscaler or cloud builder ever did or will do. And as a matter of course, being publicly funded, the labs actually talk about what they are doing and why they are doing it, thereby enabling us all to learn something.
It is with all of this in mind that we wanted to talk about the integrated storage that is part of the future “El Capitan” exascale system that Lawrence Livermore announced a year ago. El Capitan will have in excess of 2 exaflops of raw computing power spread across nodes based on stock (meaning not custom) AMD “Genoa” Epyc CPUs and a quad of stock AMD Instinct GPUs and which is expected to be installed in late 2022 and go into production around the middle of 2023. This integrated storage system, which is called “Rabbit” presumably because it is small and fast, is a key aspect of the El Capitan system and, importantly, is what will make this exascale system useful across traditional HPC simulation and modeling, AI training and inference, and data analytics workloads as well as workflows that mesh together these techniques and need to chew on the same data as it enters and exits various compute elements of the system.
Before getting into Rabbit, we asked Bronis de Supinski, who is chief technology officer for Livermore Computing, the organization that designs and runs systems for the lab, why Lawrence Livermore was taking a different approach with storage than was used with the 125 petaflops “Sierra” supercomputer that is its current flagship machine and still the third most powerful system in the world. That system is comprised of a pair of IBM Power9 processors with 256 GB of main memory and a quad of Nvidia V100 GPU accelerators, each with their own 16 GB of HBM2 memory. (Does this architecture sound a little familiar once you consider that AMD has been saying for years use one of its CPUs in a system instead of two of Intel’s or IBM’s or anyone else’s?) Each node also had a 1.6 TB NVM-Express flash drive hooked to the node over the PCI-Express 4.0 bus, which was a very fast kind of local storage in the node. The supercomputer had a massive 154 PB Spectrum Scale (GPFS) parallel file system with an aggregate of 1.54 TB/sec of read/write bandwidth. Add it all up across those 4,320 nodes, and you have a massive 6.9 PB of flash storage, which balances out nicely between 1.9 PB of main memory and that massive parallel file system.
Why not just put local NVM-Express storage in the El Capitan nodes, as was done with Sierra, and be done with it? This was, presumably, a big improvement over using a concentrated burst buffer as some systems did.
“Rabbit gives us the best of both worlds,” de Supinski tells The Next Platform. “Cray has been selling DataWarp, which is essentially a non-volatile media server that sits on the high performance interconnect, but you have to go over the interconnect to get to those SSDs. With Sierra, we have node local SSDs that you can access directly from the compute node, but that compute has to be involved with that access to some extent. We can use NVM-Express over Fabrics, which reduces that involvement. But you still have to build a special distributed file system in order to do shared I/O to those SSDs. It’s really good for output files and checkpoints written by each specific compute node, or having system files to reduce boot times. But it is not really good for shared files. Another problem with the way we did it in Sierra is that it is all or nothing. A job running on a compute node has access to precisely and only that SSD, and if it is not being used, it’s just sitting there.”
And frankly, de Supinski says that this local node storage does not get used a lot on Sierra because of these limitations.
With El Capitan and its Rabbit storage system, that local node SSD storage is evolving into a disaggregated shared storage array, with its own compute so I/O management doesn’t interrupt the CPUs and GPUs doing the HPC and AI and analytics work, that is converged into a set of nodes but on a separate PCI-Express network. To one way of looking at it, Rabbit is a kind of storage DPU with precisely allocated NVM-Express flash storage; to another way of looking at it, it is a baby dedicated flash array for a pod of El Capitan nodes.
The fun bit is that it is disaggregated and converged, and it can do many different things. It can look like a node-local SSD when needed, it can look something like a DataWarp burst buffer when needed, and it can even run ephemeral or permanent mini parallel file systems (Lustre or GPFS) or maybe even block or object storage if the use case calls for it.
Here is the block diagram of the El Capitan compute nodes and Rabbit storage nodes:
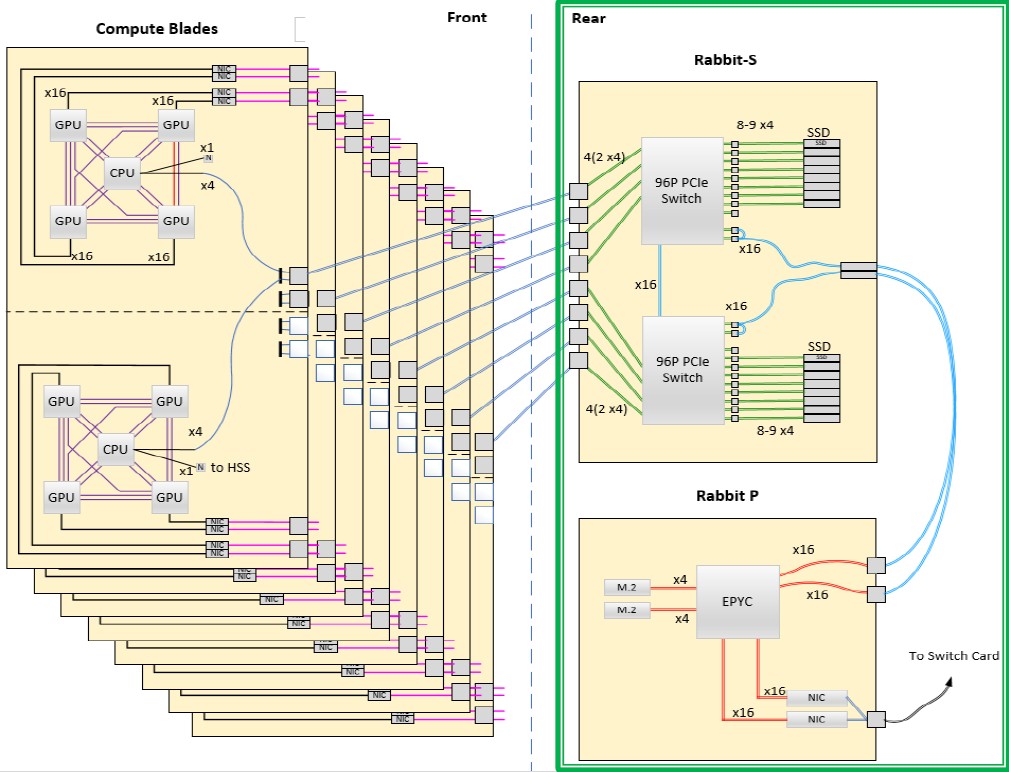
The compute blades are on the left and the storage blades are on the left and they slot into a PCI-Express backplane in the “Shasta” systems from Hewlett Packard Enterprise (formerly Cray) using direct connections – meaning there are no cables.
There are a couple of things to note here.
One the compute side of El Capitan, each blade has a pair of CPU-GPU nodes. For each node, the Genoa CPU is cross-coupled with Infinity Fabric links – a kind of superset of PCI-Express and a subset of the old AMD HyperTransport NUMA (and therefore coherent) interconnect – to the four Instinct GPU accelerators. There are four lanes of PCI-Express (presumably at PCI-Express 5.0 speed, but there is an outside chance it could be PCI-Express 6.0) I/O coming off the CPU and another single lane of PCI-Express that links out to something called the “HSS” which could mean a lot of things but is not a lot of I/O with only 32 Gb/sec of signaling in a PCI-Express 5.0 lane but is more interesting if it is a 64 Gb/sec PCI-Express 6.0 lane – this is probably the management network for the system. You will notice that there are a pair of PCI-Express backplane connectors on each node, each with a pair of PCI-Express x4 slots, and the Rabbit storage takes two nodes and drives them through this double-wide x4 connector out to the Rabbit system.
What is not relevant for this storage discussion, but what is interesting in its own right, is this. You will see there is another PCI-Express connector on each node, and only three of the four PCI-Express connectors for the blade midplane are actually being used. What is the deal here? Supercomputers don’t have extra components. We strongly suspect that there is a way to daisy chain the PCI-Express fabric implemented in Rabbit to do other clever things that Lawrence Livermore is not talking about yet. And perhaps a PCI-Express fabric between the CPUs to provide some sort of coherency. Those spare 24 lanes in three midplane connectors don’t link to anything. That’s just odd.
Here is another thing to notice. The Slingshot interconnect that is used to interlace the compute nodes – and we presume it is a faster, future Slingshot interconnect running at 400 Gb/sec, not the original 200 Gb/sec speeds available now – hangs off of the GPUs, not the CPUs. So, in a sense, the CPU is a serial and big memory coprocessor for the GPUs and also an I/O interface to the Rabbit storage. This block diagram seems to suggest the supremacy of GPU compute over CPU compute, and we wonder just how modest that Genoa CPU at the heart of the system really will be.
Now, let’s look to the right of this block diagram and talk about Rabbits. To the top right of this chart, which will be the back left of the actual El Capitan system, will be a chassis with a total of eighteen SSDs, two 96-port PCI-Express switches, and eight PCI-Express midplane connectors reaching back into a pod of eight El Capitan compute nodes. This is called a Rabbit-S node, and the S is for storage. The SSDs are partitioned into blocks of nine, with eight usable and one spare because failure is not only an option, it is an inevitability in an exascale-class machine. Half of the PCI-Express midplane connectors go to one switch and half to the other, and there is an x16 lane connector between the switches so they can multipath to the partitions of SSD storage.
Each switch also has a pair of x8 connectors that provide an x16 link from each switch out to a pair of x16 links on the Rabbit-P board, and the P stands for processor. Rabbit has its own dedicated AMD Epyc processor – probably not a big fat Genoa chip, probably something more modest, but de Supinski is not saying. It looks like it has four DDR memory slots, presumably of the DDR5 flavor that is coming down the pike.
This Rabbit processor has a pair of M.2 flash drives for local operating system and systems software storage, and has two PCI-Express x16 lanes (presumably running at PCI-Express 5.0 speeds like the rest of this, but maybe PCI-Express 6.0 if it can get into the field in time) that have Slingshot network interfaces on them. It is those network interfaces that link out to the high speed interconnect, like the GPUs on the compute side do, and that will also allow for Rabbit storage nodes to scale to larger and transient Lustre parallel file systems if need be.
But don’t get the wrong idea. El Capitan will have a dedicated parallel file system – the feeds and speeds have not been disclosed – that is based on HPE/Cray ClusterStor arrays, presumably with some flash and lots of disk drives but again, Lawrence Livermore is not saying more.
Here is conceptually how it will all fit together: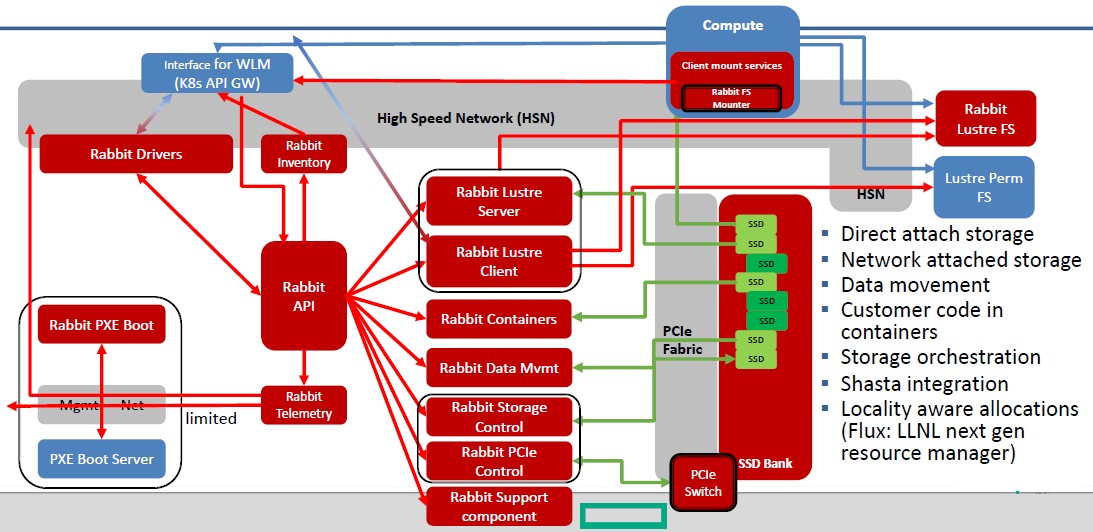
“The Rabbit processors will run user containers and we will be able to run any code we want to in those user containers,” explains de Supinski. “So we can run any file system out of those containers over those SSDs. We are looking specifically at porting the UnifyFS distributed file system developed by Kathryn Mohror here at Lawrence Livermore.”
Perhaps the most important thing about the Rabbit storage is that it will allow for data to be pre-processed or post-processed, perhaps using a data analytics or machine learning stack, before it is put through the CPU-GPU complexes for a simulation. In the past, Lawrence Livermore would have had to buy a separate commodity server cluster for this work. Now, it can just boot up the software in Rabbit containers and run this work there, and still be local to some nodes and still be on the high speed Slingshot network to pass that data directly to compute nodes for simulation work.
The key to Rabbit is the flexibility that it brings. In the past, supercomputers like Sequoia and Sierra were diskless and relied on the parallel file system, clustered to each other using a dedicated network and also patched into the high speed compute network, for storage. The ingest and output of files both tend to be bursty, and cause issues on that high speed network. By putting flash-based burst buffers in the mix on the other side of the high speed network, but interposed between the compute cluster and the storage cluster, data could be pumped into the storage system fast and access times could also be goosed (disk ain’t that fast, after all). But network bursting was still an issue because the compute nodes still had to go out over the high speed network to access the burst buffer. Distributing flash within the nodes go the flash off the high speed network, but also made it less useful because it was not shared.
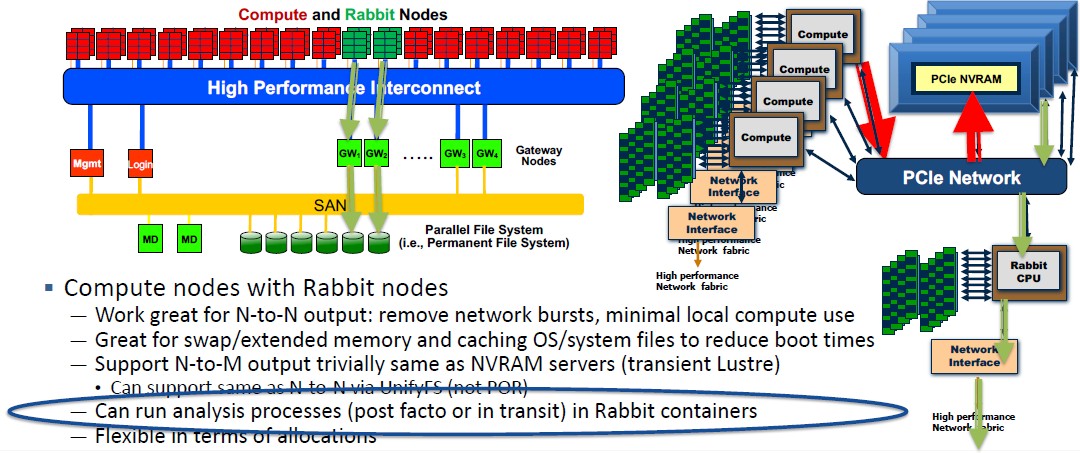
With Rabbit, storage runs on a completely local level and is shared across some nodes, and is not on the network path for the compute elements and does not have to share network interfaces into the high speed network, either.
We suspect that the Rabbit storage will be considerably more expensive, with those PCI-Express switches and Epyc compute engines embedded in it, but we also expect that some of this was paid for by the very aggressive pricing that AMD gave to HPE/Cray and therefore to Lawrence Livermore to build the compute side of the El Capitan system. There is no question in our minds that what AMD offered with its Epyc-Instinct combo from AMD was a lot less expensive – and had a lot more oomph for the dollar – than what IBM pitched with Power10 and what Nvidia pitched with the E100 – we presume “Einstein” is next after the “Ampere” A100 – GPU accelerators slated for 2022 or so. So in that sense, the Rabbit storage is “free” and is one of the reasons by HPE/Cray closed this deal.


Cooling Magma Is A Challenge That Lawrence Livermore Can Take On
With 5.4 petaflops of peak performance crammed into 760 compute nodes, that is a lot of computing capability in a small space generating a considerable amount of heat. And that is what Lawrence Livermore National Laboratory’s latest HPC system – aptly nicknamed “Magma” and procured under the Commodity Technology Systems …

To Exascale And (Maybe) Beyond!
The difference between “high performance computing” in the general way that many thousands of organizations run traditional simulation and modeling applications and the kind of exascale computing that is only now becoming a little more commonplace is like the difference between a single, two door coupe that goes 65 miles …
Lining Up The “El Capitan” Supercomputer Against The AI Upstarts
The question is no longer whether or not the “El Capitan” supercomputer that has been in the process of being installed at Lawrence Livermore National Laboratory for the past week – with photographic evidence to prove it – will be the most powerful system in the world. The question is …
Be the first to comment