

The National Energy Research Scientific Computing Center at Lawrence Berkeley National Laboratory, one of the key facilities of the US Department of Energy that drives supercomputing innovation and that spends big bucks so at least a few vendors will design and build them, has opened up the bidding on its future NERSC-10 exascale-class supercomputer.
If you feel up to the task, Hewlett Packard Enterprise, which is the sole major server vendor taking down capability-class supercomputer deals that is based in the United States, could use some competition.
HPE bought Silicon Graphics for $275 million in August 2016 and then bought Cray for $1.3 billion in August 2019, consolidating two competitors that might have otherwise bid against each other for a NERSC-10 machine that, as yet, does not have a nickname.
With IBM walking away from the supercomputing business – which it has said was unequivocally unprofitable for Big Blue – after installing the 200 petaflops “Summit” hybrid CPU-GPU supercomputer at Oak Ridge National Laboratory and the 125 petaflops “Sierra” variant of Summit at Lawrence Livermore National Laboratory in 2018, it is pretty slim pickings when it comes to finding a second source of exascale-class supercomputers.
Nvidia could be a primary contractor on an HPC system for the DOE, and it would be interesting to see its optically linked GPU research put into production. But Nvidia does not seem to be all that interested in the idea. Intel has lost all interest in being an HPC system prime contractor after its “Aurora” exascale system woes at Argonne National Laboratory, AMD has shown no interest in taking that bull by the horns, and Lenovo is pretty much out of the running because it is half Chinese even if it is half American. That leaves Atos, which is French, and Dell, which is more of a box shifter in smaller scale HPC rather than an architect for capability-class systems.
Microsoft Azure, Amazon Web Services, or Google Cloud could build a system inside of Berkeley Lab, and that may in fact be the second bidder that the US government wants to come up against HPE and whatever it pitches for the NERSC-10 deal. But we have a hard time believing that any of the clouds will look at this as an opportunity, given the fact that these are fixed cost deals that are more like research and development cost coverage than a profitable, commercial deal at even cost plus, much less at a reasonable profit.
Building exascale machines is important for national security and for driving information technology innovation, but it is not an easy way to make money. And it has never been. And it almost certainly never will be. Jennifer Granholm, who is the Secretary of Energy, should send flowers, chocolates, and Thank You notes to HPE and AMD for the “Frontier” machine running for the past year at Oak Ridge and for the “El Capitan” machine going into Lawrence Livermore National Laboratory later this year.
The bidding for NERSC-10 is going to be thin, we think. And probably coerced to a certain extent by Uncle Sam, which needs alternate vendors and architectures for exascale-class machines to mitigate against various risks of delivery and the simple risk of having a single source for such important machines. And given the desire for diversity, we think there is a good chance that NERSC-10 will be based on future hybrid CPU-GPU chips from Nvidia rather than similar CPU-GPU hybrids from AMD unless AMD is very aggressive with its future Instinct MI400 or MI500 compute engines. This could be a machine based on “Falcon Shores” hybrid CPU-GPU designs, but Intel would have to give lots of concessions to be a part of the NERSC-10 system given its woes with the “Aurora” hybrid CPU-GPU machine at Argonne National Laboratory. Those concessions would be price, and that could win the deal. That is how AMD beat out IBM and Nvidia for the exascale systems bought by the DOE.
Perhaps the Department of Energy and the Department of Defense will have to start their own supercomputer maker, behaving themselves like a hyperscaler and getting a US-based original design manufacturer (ODM) to build it. Why not? We need a big US-based ODM anyway, right? (Supermicro sort of counts as the biggest one located in the United States, but there are others.) And NERSC-10 is not being installed until 2026, so there is time to do something different. But if that happens, competitive bidding goes out the window because once it is set up, Uncle Sam Systems, as we might call it, will win all of the deals. It will have to in order to justify its existence.
The NERSC-10 RPF Feeds And Speeds
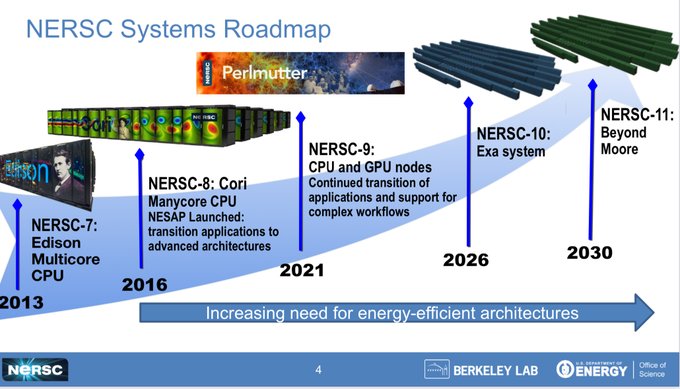
Berkeley Lab opened up the RFP documents for the NERSC-10 machine on April 17, and the RFP is expected to be released in the fourth quarter this year with contracts for the system build and non-recurring engineering (NRE) add-ons awarded in the fourth quarter of 2024. The NERSC-10 early access system will be installed in 2025, system delivery is slated for the second half of 2026, with full production use in 2027.
Let’s go through the NERSC-10 wish list.
First and foremost, the machine has to deliver 10X the application performance of the existing 93.8 petaflops “Perlmutter” machine, which is an HPE Cray EX235n system that has 64-core AMD “Milan” Epyc 7763 processors paired with Nvidia “Ampere” A100 GPU accelerators, linked by the HPE Slingshot-10 Ethernet interconnect. That 10X is not a raw theoretical 64-bit flops requirement, but rather a 10X performance improvement on a mix of applications, called the Workflow-SSI stack, that have been run on Perlmutter. Berkeley Lab says further that the NERSC-10 machine will have to have a mix of CPU-only and hybrid CPU-GPU nodes to adequately drive the performance of Workflow-SSI and that the precise mix of these two kinds of nodes are left up to the vendor providing the RFP.
Whatever the architecture, NERSC has to fit in a 20 megawatt power envelope, which is a little lower than the 21.1 megawatts that a chunk of Frontier is burning at Oak Ridge to deliver its peak 1.69 exaflops and sustained 1.1 exaflops on the High Performance Linpack benchmark. Perlmutter burns 2.6 megawatts to deliver 70.9 petaflops on Linpack, which works out to 27.4 gigaflops per watt, which is half as efficient as Frontier, which is driving 62.7 gigaflops per watt on Linpack.
It is very hard to guess where the gigaflops per watt might be for a top-end supercomputer installed in 2026 might be, but let’s take a stab at it. If you look at the Green500 rankings for November every other years, then in 2014 it was averaging somewhere around 4 gigaflops to 5 gigaflops per watt. In 2016, two years later, it was somewhere between 6 gigaflops and 10 gigaflops per watt. In 2018, it was around 15 gigaflops per watt and in 2020 it was around 27 gigaflops per watt. Frontier is 62.7 gigaflops per watt. The question is: Can computational efficiency double again in 2024, or will it be more like a 50 percent increase from here on out? Let’s be pessimistic because Moore’s Law is running out. Call it 100 gigaflops per watt for machines built in 2024, an increase of 60 percent, and 135 gigaflops per watt for machines built in 2026, a further 35 percent increase. That’s a more than doubling in four years, enabled by process shrinks and packaging that reduces latencies between CPUs and GPUs.
So, in a 20 megawatt power envelope, that means the raw 64-bit performance of the NERSC-10 machine would be 2.7 exaflops at 135 gigaflops per watt. We don’t think Berkeley Lab is trying to burn 20 megawatts, especially given the cost of electricity in California, but we do think it wants to have a machine that delivers at least 1 exaflops on Linpack. Call NERSC-10 a 1.5 exaflops peak machine, and that would fit inside of an 11 megawatt power envelope delivering 1 exaflops on Linpack. Such a machine, by our back of the envelope math, would deliver 16X the peak performance of Perlmutter and that should be well within the 10X performance increase on real-world applications that Berkeley Lab is prescribing in the NERSC-10 RFP. And if the compute increase or the compute efficiency is not as good as it hoped by the prospective suppliers of the system, then it can make it up in node volume, as often happens with capability class supercomputers and it will still fit within that 20 megawatt power envelope.
One might be tempted to call the scientists at Berkeley Lab cynical, but they are actually just being practical given all of the unknowns even four years into the future.
No budget figures were given for the NERSC-10 system, but the RFP guidelines did say that NRE tends to be 10 percent to 20 percent of the system build contract, which would include early access systems and multiple test and development systems.
The NERSC-10 machine has to be able to run C (2017), C++ (2020), and Fortran (2018) code using OpenMP directives. It has to support LLVM backends for compute engines (CPUs, GPUs, whatever) and to compile applications using Kokkos, SYCL, OpenACC, and CUDA applications. MPI is the glue for lashing together the cores on the devices across the network. The network was not specified in the documents, but it will no doubt be either InfiniBand or Ethernet.




Your back of the envelope math works for the GPU part of the machine, but they probably also want 10x on the CPU-only applications. I doubt we’re going to see the same ratio of performance improvement for CPU sockets as we will for GPUs. The only thing I can think that would support that is on-package cache and HBM plus another doubling or more of cores per socket. Otherwise you might just need a lot more cabinets full of cores to get that level of improvement.
What about one of the big defense contractors as the prime contractor? If Lockheed/Martin can bid airbus to the airforce, maybe they can bid Atos to DOE.
I think you are right. Good point. Not sure if Granite Rapids or Diamond Rapids will have HBM, but it will have something like it if not HBM4. And I agree, HPC customers need it. They need 10X the bandwidth than even that provides. Someday, we will slow down processors and fatten up memory and get this back into whack…..
I like the idea of bringing Atos to the mix (eg. through Lockheed/Martin) … maybe even Fujitsu(?).
GPU chip sizes have long been at the boundary of what is practical to fab.
Only very recently have we at long last seen AMD introduce elements of their chiplet architecture to GPUs.
I predict major advances from this.
Interesting article. I am surprised that AMD might not want to compete in the bidding with HPE. Their recent impressive success in supercomputer deals enabled them to get financing for their research for MI200 and the forthcoming MI300 at the time when they had little resources. Their gross margins were probably not very high but they got tremendous knowledge in performance and power efficiency at making working together CPU and GPU. The MI300 is the child of this cooperation. However with AMD making more money and being highly profitable they may believe they don’t needs these « grants ». We will see but I think that Lisa Sue is aware that these deals improved materially AMD image as a leader in supercomputing and also being a company that can deliver on its promises.
Given that they are already very successful in selling their chips in big HPC rigs, the question is how much more successful they would be if they were the prime contractor – a role outside their existing competencies, and one that does not typically result in amazing profit margins.
https://medium.com/@art_87634/open-standard-for-earth-health-monitor-version-2023-04-22-b7d92ab85c6c
Open Standard for “Earth Health Monitor ™”, version 2023.04.22
Earth Day 2023
Just published: US Patent Application on “Oscillator for Adiabatic Computational Circuitry.” This sort of thing will be essential for moving beyond the thermal barriers that otherwise threaten to soon halt improvements in digital energy efficiency. https://image-ppubs.uspto.gov/dirsearch-public/print/downloadPdf/20230114017