
Dynamic allocation of resources inside of a system, within a cluster, and across clusters is a bin-packing nightmare for hyperscalers and cloud builders. No two workloads need the same ratios of compute, memory, storage, and network, and yet these service providers need to present the illusion of configuration flexibility and vast capacity. But capacity inevitably ends up being stranded.
It is absolutely unavoidable.
But because main memory in systems is very expensive, and will continue to grow more expensive over time relative to the costs of other components in the system, the stranding of memory capacity has to be minimized, and it is not as simple as just letting VMs grab the extra memory and hoping that the extra megabytes and gigabytes yield better performance when they are thrown at virtual machines running atop a hypervisor on a server. The number of moving parts here is high, but dynamically allocating resources like memory and trying to keep it from being stranded – meaning all of the cores in a machine have memory allocations and there is memory capacity left over that can’t be used because there are no cores assigned to it – is far better than having a static configuration of memory per core. Such as the most blunt approach, which would be to take the memory capacity, divide it by the number of cores, and give each core the same sized piece.
If you like simplicity, that works. But we shudder to think of the performance implications that such a static linking of cores and memory might have. Memory pooling over CXL is taking off among the hyperscalers and cloud builders as they try to deploy that new protocol it atop CPUs configured with PCI-Express 5.0 peripheral links. We covered Facebook’s research and development recently as well as some other work being done at Pacific Northwest National Laboratory, and have discussed the prognostications about CXL memory from Intel and Marvell as well.
Microsoft’s Azure cloud has also been working on CXL memory pooling as it tries to tackle stranded and frigid memory, the latter being a kind of stranded memory where there are no cores left on the hypervisor to tap into that memory and the former being a broader example of memory that is allocated by the hypervisor for VMs but is nonetheless never actually used by the operating system and applications running in the VM.
According to a recent paper published by Microsoft Azure, Microsoft Research, and Carnegie Mellon University, DRAM memory can account for more than 50 percent of the cost of building a server for Azure, which is a lot higher than the average of 30 percent to 35 percent that we cited last week when we walked the Marvell CXL memory roadmap into the future. But this may be more of a function of the deep discounting that hyperscalers and cloud builders can get in a competitive CPU market, with Intel and AMD slugging it out, and that DRAM memory for servers is much more constrained and that Micron Technology, Samsung, and SK Hynix as well as their downstream DIMM makers can charge what are outrageous prices compared to historical trends because there is more demand than supply. And when it comes to servers, we think the memory makers like it that way.
Memory stranding is a big issue because that capital expense for memory is huge. If a hyperscaler or cloud builder is spending tens of billions of dollars a year on IT infrastructure, then it is billions of dollars on memory, and driving up memory usage in any way has to potential to save that hyperscaler or cloud builder hundreds of millions of dollars a year.
How bad is the problem? Bad enough for Microsoft to cite a statistic from rival Google, which has said that the average utilization of the DRAM across its clusters is somewhere around 40 percent. That is, of course, terrible. Microsoft took measurements of 100 clusters running on the Azure cloud – that is clusters, not server nodes, and it did not specify the size of these clusters – over a 75 day period, and found out some surprising things.
First, somewhere around 50 percent of the VMs running on these Azure clusters never touch 50 percent of the memory that is configured to them when they are rented. The other interesting bit is that as more and more of the cores are allocated to VMs on a cluster, the share of the memory that becomes stranded rises. Like this:
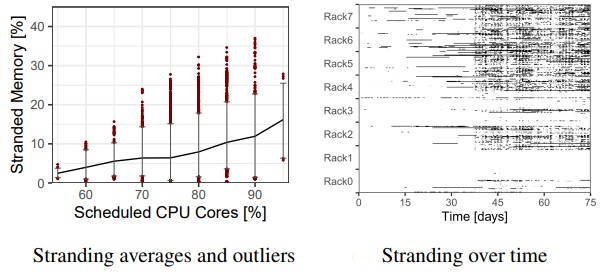
To be specific, when 75 percent of cores in a cluster are allocated, 6 percent of the memory is stranded. This rises to 10 percent of memory when 85 percent of the cores are allocated to VMs, 13 percent at 90 percent of cores, and full loading of cores it can hit 25 percent and outliers can push that to as high 30 percent of DRAM capacity across the cluster being stranded. On the chart on the right above, the workload changed halfway through and there was a lot more memory stranding.
The other neat thing Microsoft noticed on its Azure clusters – which again have VMs of all shapes and sizes running real-world workloads for both Microsoft itself and its cloud customers – that almost all VMs that companies deploy fit within one NUMA region on a node within the cluster. This is very, very convenient because spanning NUMA regions really messes with VM performance. NUMA spanning happens on about 2 percent of VMs and on less than 1 percent of memory pages, and that is no accident because the Azure hypervisor tries to schedule VMs – both their cores and their memory – on a single NUMA node by intent.
The Azure cloud does not currently pool memory and share it across nodes in a cluster, but that stranded and frigid DRAM memory could be moved to a CXL memory pool without any impact to performance, and some of the allocated local memory on the VMs in a node could be allocated out to a CXL memory pool, which Microsoft calls a zNUMA pool because it is a zero-core virtual NUMA node, and one that Linux understands because it already supports CPU-less NUMA memory extensions in its kernel. This zNUMA software layer is clever in that it has statistical techniques to learn which workloads have memory latency sensitivity and those that don’t. So, workloads don’t have such sensitivity, they get their memory allocated all or in part out to the DRAM pool over CXL and if they do, then the software allocates memory locally on the node and also from that core-less “frigid” memory. Here is what the decision tree looks like to give you a taste:
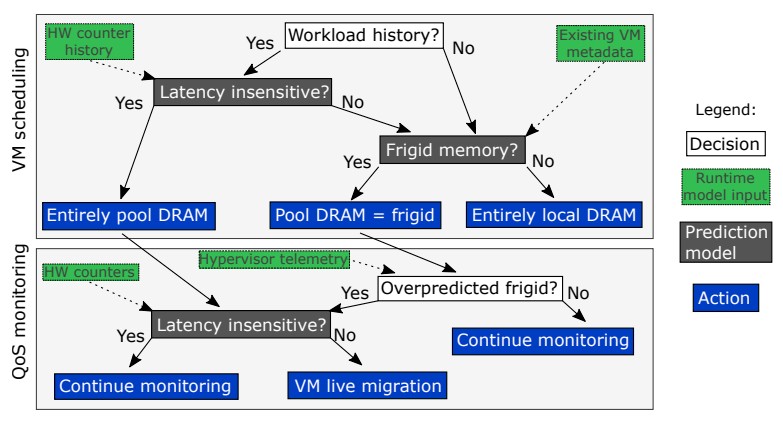
This is a lot hairier than it sounds, as you will see from reading the paper, but the clever bit as far as we are concerned is that Microsoft has come up with a way to create CXL memory pools that doesn’t mess with applications and operating systems, which it says is a key requirement for adding CXL extended memory to its Azure cloud. The Azure hypervisor did have to be tweaked to extend the API between the server nodes and the Autopilot Azure control plane to the zNUMA external memory controller, which has four 80-bit DDR5 memory channels and multiple CXL ports running over PCI-Express 5.0 links that implements the CXL.memory load/store memory semantics protocol. (We wonder if this is a Tanzanite device, which we talked about recently after Marvell acquired the company.) Each CPU socket in the Azure cluster links to multiple EMCs and therefore multiple blocks of external DRAM that comprise the pool.
The servers used in the Microsoft test are nothing special. They are two-socket machines with a pair of 24-core “Skylake” Xeon SP-8157M processors. It looks like the researchers emulated a CPU with a CXL memory pool by disabling all of the cores in one socket and making all of its memory available to the first socket over UltraPath links. It is not at all clear how such vintage servers plug into the EMC device, but it must be a PCI-Express 3.0 link since that is all that Skylake Xeon SPs support. We find it peculiar that the zNUMA tests were not run with “Ice Lake” Xeon SP processors with DDR5 memory on the nodes and PCI-Express 5.0 ports.
The DRAM access time on the CPU socket in a node was measured at 78 nanoseconds and the bandwidth was over 80 GB/sec from the socket-local memory. The researchers say that when using only zNUMA memory the bandwidth is around 30 GB/sec, or about 75 percent of the bandwidth of a CXL x8 link, and it added another 67 nanoseconds to the latency.
Here is what the zNUMA setup looks like:
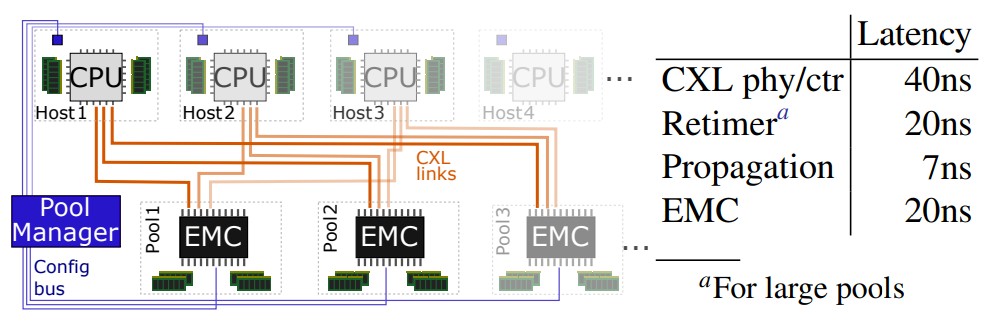
Microsoft says that a CXL x8 link matches the bandwidth of a DDR5 memory channel. In the simplest configuration, with four or eight total CPU sockets, each EMC can be directly connected to each socket in the pod and that cable lengths are short enough so that the latency out to the zNUMA memory is an additional 67 nanoseconds. If you want to hook the zNUMA memory into a larger pool of servers – say, a total of 32 sockets – then you can lower the amount of overall memory that gets stranded but you have to add retimers to extend the cable and that pushes the latency out to zNUMA memory to around 87 nanoseconds.
Unstranding the memory and driving up overall utilization of the memory is a big deal for Microsoft, but there are performance implications of using the zNUMA memory:
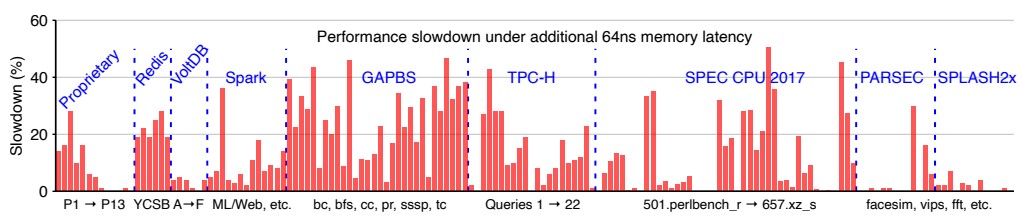
Of the 158 workloads tested above, 20 percent had no slowdown using CXL memory, and 23 percent had a slowdown of 5 percent or less. Which is good. But as you can see, some workloads were hit pretty hard. About a quarter of the workloads had a 20 percent or greater performance hit from using zNUMA memory for at least some of their capacity and 12 percent of the workloads had their performance cropped by 30 percent or more. Applications that are already NUMA aware have been tweaked so they understand memory and compute locality well, and we strongly suspect that workloads will have to be tweaked to use CXL memory and controllers like the EMC device.
And just because we think all memory will have CXL attachment in the server over time does not mean we think that all memory will be local and that CXL somehow makes latency issues disappear. It makes it a little more complicated than a big, fat NUMA box. But not impossibly more complicated and that is why research line the zNUMA effort at Microsoft is so important. Such research points the way on how this can be done.
Here is the real point: Microsoft found that by pooling memory across 16 sockets and 32 sockets in a cluster, it could reduce the memory demand by 10 percent. That means cutting the cost of servers by 4 percent to 5 percent, and that is real money in the bank. Hundreds of millions of dollars a year per hyperscaler and cloud builder.
We are counting on people creating the PCI-Express 6.0 and 7.0 standards and the electronics implementing these protocols to push down to reduce latencies as much as they push up to increase bandwidth. Disaggregated memory and the emergency of CXL as a universal memory fabric will depend on this.

For HPC And AI, Composability Might Trump Cheap Flops
Maximizing the aggregate amount of compute that can be brought to bear for any given pile of money is what traditional high performance computing is all about. What happens in a world, though, where the compute environment is not homogeneous and cannot be stuffed full of work by the MPI …
The Big Clouds Get First Dibs On AMD “Genoa” Chips
The expanded lineup of AMD’s 4th generation “Genoa” Epyc server chips – built atop “Zen 4” core and some with the chip maker’s L3-boosting 3D V-Cache – unveiled at a high-profile event in San Francisco this week is quickly making its way into the cloud. Microsoft and Amazon Web Services both …
Compute Is Easy, Memory Is Harder And Harder
What good is a floating point operation embodied in a vector or matrix unit if you can’t get data into fast enough to actually use the compute engine to process it in some fashion in a clock cycle? The answer is obvious to all of us: Not much. People have …
I think the design of the Linux buffer cache is such that any free memory not wired to a process is used to cache the filesystem. Does the statistic of 40 percent RAM use ignore or include this aspect of memory use? Or was this working at the VM level?