
What good is a floating point operation embodied in a vector or matrix unit if you can’t get data into fast enough to actually use the compute engine to process it in some fashion in a clock cycle? The answer is obvious to all of us: Not much.
People have been talking about the imbalance between compute and memory bandwidth for decades, and every year the high performance computing industry has been forced to accept less and less memory bandwidth per floating point operation because increasing memory bandwidth is exceedingly difficult in a fashion that doesn’t also end up being very pricey.
And while we are thinking about it, increasing memory capacity is also getting more difficult because fat memory is also coming under Moore’s Law pressures and making increasingly dense as well as increasingly faster memory is getting more and more difficult, and hence the price of memory has not come down as much as it otherwise. And thus, we do not have the kind of massive memory machines that we might have dreamed of decades ago.
We were reminded of this acutely during the Turing Award keynote by Jack Dongarra, well know to readers of The Next Platform as a distinguished researcher at Oak Ridge National Laboratory and research professor emeritus at the University of Tennessee. Like many of you, we watched the Turing Award keynote that Dongarra gave, talking about how he unexpectedly got into the supercomputing business and became the expert on measuring system performance on these massive machine – mostly by being part of the team that was constantly evolving math libraries as supercomputer architectures changed every decade or so. If you haven’t watched the keynote, you should, and you can do so at this link. This history is fascinating, and it forecasts how we will continue to evolve software as architectures continue to evolve.
But that’s what we are not going to talk about here.
What stuck out in our mind as we were watching Dongarra’s keynote is the massive overprovisioning of flops in today’s processors relative to memory bandwidth, and it was resonating in our head because that same week Intel had just announced some benchmark results on its upcoming “Sapphire Rapids” Xeon SP server CPUs, showing the benefit of HBM2e stacked memory, which has roughly 4X the memory bandwidth of plain vanilla DDR5 memory sticks used in modern server CPUs. (Sapphire Rapids has a 64 GB HBM2e memory option, and can be used in conjunction with DDR5 memory or instead of it.) The benefit of the HBM2e high bandwidth memory shows how much out of whack flops and bandwidth are:
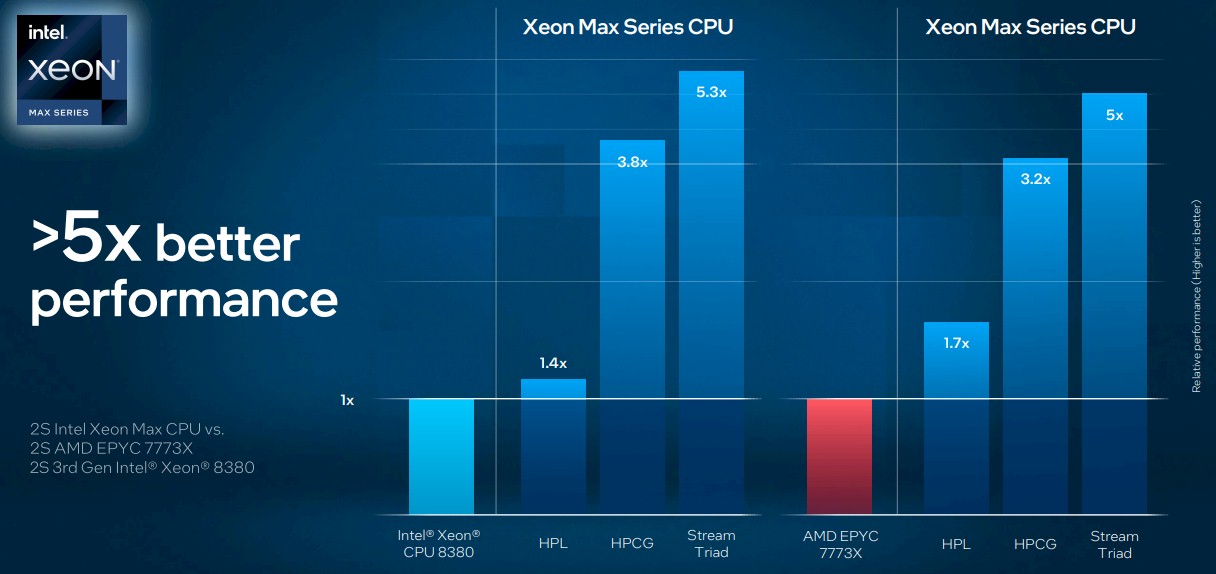
The addition of HBM2e memory to the Sapphire Rapids CPU does not affect Dongarra’s beloved High Performance Linpack (HPL) matrix math test very much, as you can see, and that is because HPL is not particularly memory bound. But the High Performance Conjugate Gradients (HPCG) and Stream Triad benchmarks, both of which are memory bound like crazy, sure do see a performance boost just by switching memory. (We presume that the machines tested had a pair of top bin, 60-core Sapphire Rapids chips.) Under normal circumstances with the HPCG test, which is probably the most accurate test reflecting how some very tough HPC applications really are written (and by necessity, not by choice), the world’s fastest supercomputers are use anywhere from 1 percent to 5 percent of the machine’s potential flops. So by increasing this by a factor of 3.8X would be a very, very big improvement indeed if that performance can scale across thousands of nodes. (This remains to be seen, and HPCG is the test that will – or won’t – show it.
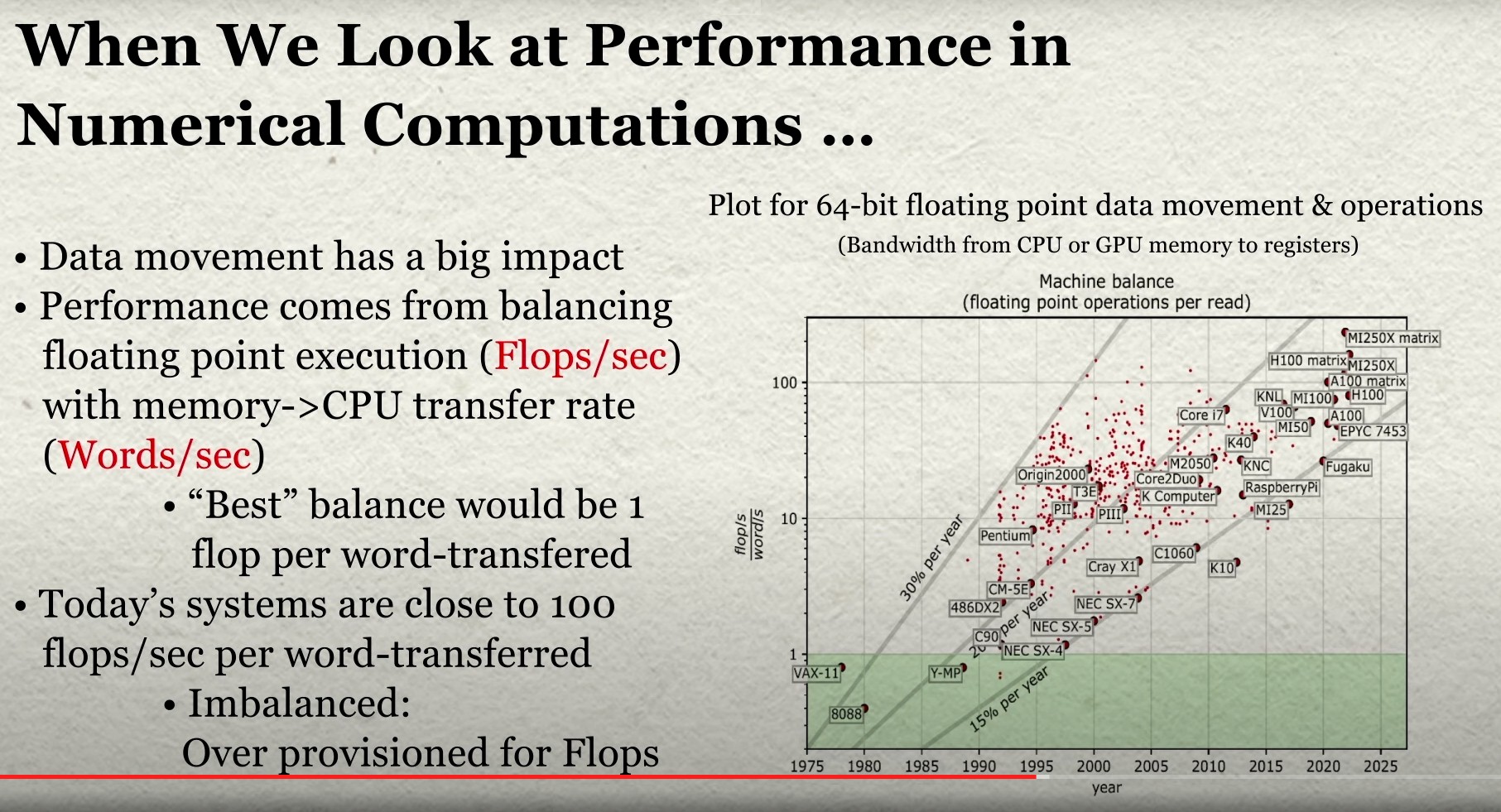
So just how far out of whack are flops and memory bandwidth with each other? Dongarra showed how it is getting worse with each passing architectural revolution in supercomputing:
And here is a zoom into the chart that Dongarra showed:
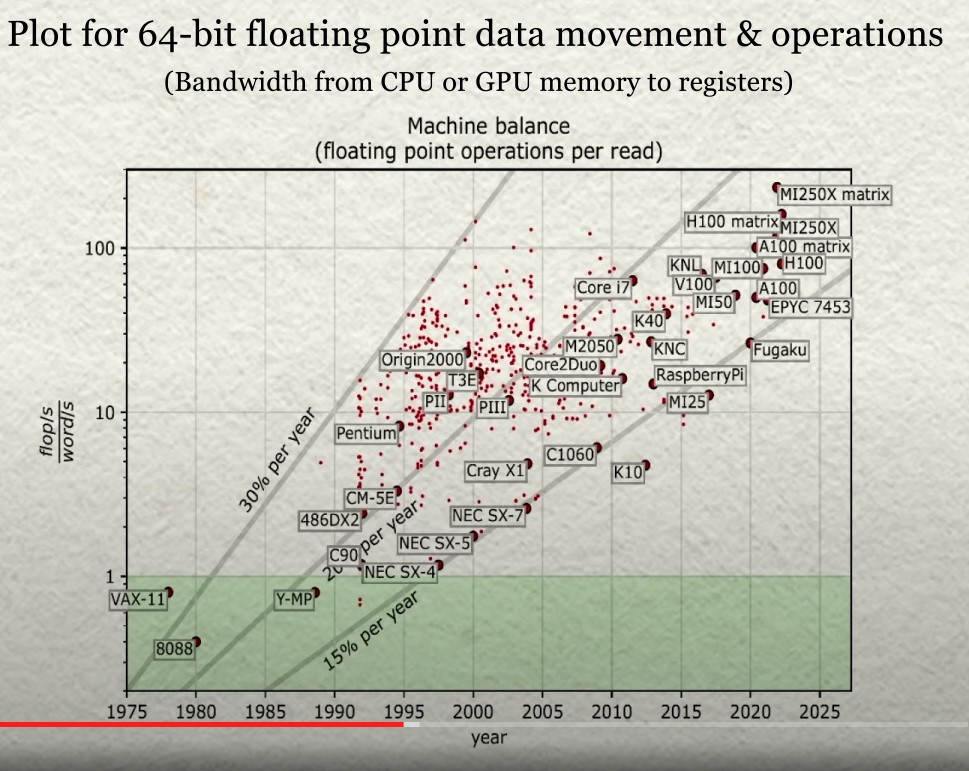
“When we look at performance today on our machines, the data movement is the thing that’s the killer,” Dongarra explained. “We’re looking at the floating point execution rate divided by the data movement rate, and we’re looking at different processors. In the old days, we had processors that basically had a match of one flops per one data movement – that’s how they were balanced. And if you guys remember the old Cray-1s, you could do two floating point operations and three data movements all simultaneously. So this is trying to get a get a handle on that. But over time, the processors have changed the balance. What has happened over the course of the next twenty years, from the beginning here is that an order of magnitude was lost. That is, we can now do ten floating point operations for every data movement that we make. And more recently, we’ve seen that number grow to 100 floating point operations for every data movement. And even some machines today are in the 200 range. That says there’s a tremendous imbalance between the floating point and data movement. So we have tremendous floating point capability – we are overprovision for floating point – but we don’t have the mechanism for moving data very effectively around in our system.”
The chart shows how generationally is has gotten worse and worse. And moving to HBM2e and even HBM3 or HBM4 and HBM5 memory is only a start, we think. And CXL memory can only partially address the issue. Inasmuch as CXL memory is faster than flash, we love it as a tool for system architects. But there are only so many PCI-Express lanes in the system to do CXL memory capacity and memory bandwidth expansion inside of a node. And while shared memory is interesting and possibly quite useful for HPC simulation and modeling as well as AI training workloads – again, because it will be higher performing than flash storage – that doesn’t mean any of this will be affordable.
We don’t yet know what even the HBM2e memory option on Sapphire Rapids will cost. If it gooses memory bound applications by 4X to 5X but the CPU costs 3X more, that is not a gain really on the performance per watt front that really gates architectural choices.
The HBM2e memory option on the future Xeon SP is a good step in the right direction. But maybe having a lot more SRAM in L1, L2, and L3 caches is more important than adding cores if we want to get the memory back in balance.
![]()
Having won the Turing Award gives Dongarra a chance to lecture the industry a bit, and once encouraged to do so, he thankfully did. And we quote him at length because when Dongarra speaks, people should listen.
“I have harped on the imbalance of the machines,” Dongarra said. “So today, we build our machines based on commodity off the shelf processors from AMD or Intel, commodity off the shelf accelerators, commodity off the shelf interconnects – those are commodity stuff. We’re not designing our hardware to the specifics of the applications that are going to be used to drive them. So perhaps we should step back and have a closer look at the how the architecture should interact with the with the applications, with the software co-design – something we talk about, but the reality is very little co-design takes place today with our hardware. And you can see from those numbers, there’s very little that goes on. And perhaps a good –better – indicator is what’s happening in Japan, where they have much closer interactions with the with the architects, with the hardware people to design machines that have a better balance. So if I was going to look at forward looking research projects, I would say maybe we should spin up projects that look at architecture and have the architecture better reflected in the applications. But I would say that we should have a better balance between the hardware and the applications and the software – really engage in co-design. Have spin-off projects, which look at hardware. You know, in the old days, when I was going to school, we had universities that were developing architectures that would, that would put together machines. Illinois was a good example of that – Stanford, MIT, CMU. Other places spun up and had had hardware projects that were investigating architectures. We don’t see that as much today. Maybe we should think about investing there, putting some research money – perhaps from the Department of Energy – into that mechanism for doing that kind of work.”
We agree wholeheartedly on the hardware-software co-design, and we believe that architectures should reflect the software that is running them. Frankly, if an exascale machine costs $500 million, but you can only use 5 percent of the flops to do real work, that is like paying $10 billion for what is effectively a 100 petaflops machine running at 100 percent utilization if you look at the price/performance. To do it the way Dongarra is suggesting would make all supercomputers more unique and less general purpose, and also more expensive. But there is a place where the performance per watt, cost per flops, performance per memory bandwidth, and cost per memory bandwidth all line up better than we are seeing today with tests like HPCG. We have to get these HPC and AI architectures back in whack.
The next generation of researchers, inspired by Dongarra and his peers, need to tackle this memory bandwidth problem and not sweep it under the rug. Or, better still for a metaphorical image – stop rolling it up in a carpet like a Mob hit and driving it out to the Meadowlands in the trunk of a Lincoln. A divergence of 100X or 200X is, in fact, a performance and an economic crime.

Microsoft Azure Blazes The Disaggregated Memory Trail With zNUMA
Dynamic allocation of resources inside of a system, within a cluster, and across clusters is a bin-packing nightmare for hyperscalers and cloud builders. No two workloads need the same ratios of compute, memory, storage, and network, and yet these service providers need to present the illusion of configuration flexibility and …
Just How Bad Is CXL Memory Latency?
Conventional wisdom says that trying to attach system memory to the PCI-Express bus is a bad idea if you care at all about latency. The further the memory is from the CPU, the higher the latency gets, which is why memory DIMMs are usually crammed as close to the socket …

Dell Gives A Second Opinion On Enterprise IT Spending
Like many of you, we are trying to find out what the heck is really going on in the global economy. And as such, we are paying particularly close attention to the original equipment manufacturers, or OEMs, who peddle servers, storage, and often switching into the enterprise. They are leading …
I wonder about what impact in-memory computing could have. Could some vector/matrix calculations be offloaded to to a local accelerator, or is that a pipe dream?
“Some” – probably yes. PIM works really well if you have a lot of math to do on discrete chunks of memory. If you can partition the work so that most of the data access fits within the memory device, and you rarely have to go off to other devices, it’ll work well. That’s not all bandwidth starved codes, and it’s one that’s already pretty well served by caching hardware. The even harder problems – like the sparse-matrix codes will get no benefit.
BANDWIDTH IS EASY, LATENCY IS HARDER AND HARDER
Yes, that is the next one in the series …. HA!
Twenty years ago, whrn buying HPC, I used to specify the lowest power consumption processors instead of the fastest. The loss of real performance, on Fluent and the like, was negligible. There were fewer supply issues and we were in a good position to negotiate on price, particularly as we had really simplified acceptance criteria and a record of early payment. Useless for HPC headlines, of course…
Wow! Thanks for coming back to this topic (as promised), and linking to Jack Dongarra’s very informative Turing Lecture. Yes, if HBM only improves HPCG efficiency from 1% to 3%, then it is probably not really the “miracle” solution hoped-for (maybe more of a stopgap). Hardware (dedicated?) designed to simultaneously fetch data from memory locations that are quite distant from one another would likely be a better bet (maybe even some in-memory processing as one audience member asked about at the end). For the 27-point stencil of HPCG that Dr. Dongarra mentioned, we know the memory access pattern ahead of time, and so might be able to pre-specify those to some memory-access hardware (maybe the stencil-based approach of French researchers), to preload related data into cache before they are needed by the solution algo (in parallel with computations on data already in cache) — but I have to guess that HPC folks are already doing some level of this (possibly in a purely software-based approach). Then again there are mixed-precision and posit/unum approaches that could reduce the needed memory bandwidth by working with data smaller than 64-bits. The 0% to 6% fraction of peak (in your HPCG link) is great food for thought and will hopefully spark innovations in memory access technology, with broad applicabilty!
The ideal ratio is not so simple to determine as Dongarra suggests, as it is different for every application. As tempting as it is to say that the Cray-1 got the ratio correct, there are and were a lot of applications that need a lot of flops, and don’t make great use of the memory bandwidth, or for which a couple megabytes of sram cache are enough. There are also plenty of applications somewhere between the extremes. For some of these applications, it would be an economic crime to pay for a lot of memory bandwidth that goes unused.
This is where Cray Research had problems in the early 90s, when they were trying to sell high bandwidth machines to solve all problems when some applications really needed it, and some really didn’t. Then, as now, it’s difficult to find a solution that makes everyone happy, and even harder to do that cheaply.
I think Dongarra is right in hoping microprocessor vendors are able to mix and match cores, cache, and memory controllers to offer different ratios, using the same building blocks. You’re probably not going to see Cray-1 style ratios, but a 10-100 spread of ratios might be plausible.
You’re quite right (I think). In HPL (dense matrices, Karate), the top500 machines run at 65% of theoretical peak (Frontier at least), but in HPCG (sparse matrices, Kung-Fu), they run at 2% of theoretical peak. I would expect that they run even farther from peak in Graph500 (depth-first and bradth-first search) where the impact of latency would be felt more strongly due to the rather more unpredictable memory-access patterns.
This article came in my google chrome suggestions. Right from my childhood, I love topics related to cpu and memories. I have bookmarked your website for more future article reading.
…mob hit… funny ! Very informative and well written.
>>We have to get these HPC and AI architectures back in whack.<< Can't speak to the HPC side, but isn't prioritizing memory bandwidth and access precisely what Nvidia's Grace+Hopper architecture is attempting? A machine architecture built to a specific purpose? Nvidia gets the "specifics of the applications" driving them due to their unique position supplying the accelerator and software kernals. Nvidia cut it's teeth counting cycles and optimizing game applications. Machine learning is more of that but on a much much larger scale.
My understanding is that the Nvidia GPU is still spending a lot of time scratching itself waiting for data to hit the cores, and it is memory capacity constrained even if it is not as bandwidth constrained. Still a memory problem, and Grace will help fix that by being a glorified memory controller with 512 GB of memory capacity.
Tufts U HotGuage. Landauer E disspHEAT = kTln2. Icarus. Computationally intensive kernels. Helios.