
Maximizing the aggregate amount of compute that can be brought to bear for any given pile of money is what traditional high performance computing is all about. What happens in a world, though, where the compute environment is not homogeneous and cannot be stuffed full of work by the MPI protocol? What happens when the compute environment has multiple kinds of compute engines, and they are expensive even if they are stuffed to the 400 watts with all kinds of math engines?
What happens, we think, is that HPC jumps on the disaggregation and composability bandwagon, which we have been predicting would eventually come since we founded The Next Platform. (See Smashing The Server To Put It Back Together Better, from November 2015.) Like other IT organizations, HPC centers are starting to look for ways to carve up physical resources from their motherboard moorings, pool them., and then reassemble them virtually into various and changing configurations so they can keep as many elements in their clusters running at maximum utilization at all times as workloads change. This is the next phase in driving up utilization, which is of utmost importance when system components are expensive and Moore’s Law is not giving us a free ride on the economics anymore.
With this in mind, we watched as with great interest as Liqid, one of the upstart vendors of hardware disaggregation and composability software won two deals with the US Department of Defense. By the way, among other contenders, Liqid came up against Hewlett Packard Enterprise with its “Shasta” Cray EX supercomputers with their Slingshot interconnect for server nodes and storage and AMD with compute engines – and beat them twice. That’s pretty good in an HPC market that, at least at the very high end, is favoring the AMD-Cray combo for capability-class systems once again after a long hiatus.
We have been watching Liqid since it dropped out of stealth mode in June 2017 with its PCI-Express switching fabric its disaggregation and composability stack, when it had raised $10 million in Series A funding. The company’s initial product had a PCI-Express switching complex that required that the hardware be pooled at the physical layer in order to be composed – meaning, you had to put flash drives, network cards, and GPUs in their own enclosures and link them to compute nodes over the Liqid PCI-Express switch complex. But last November, at the SC19 supercomputing conference, Liqid announced that it had updated its LiqidOS fabric software – it’s really hard not to say fabric softener there, and don’t be surprised some day if a vendor launches an interconnect called Downy – so that it could disaggregate and pool devices sitting inside bog standard X86 servers and compose across the PCI-Express fabric and also extend it out beyond a single node with Ethernet or InfiniBand switching.
There are a bunch of things that are interesting about the two deals that Liqid has taken down for three machines at the DoD on behalf of the US Army at the Army Research Lab (ARL) at the Aberdeen Proving Ground in the town in Maryland by that name and at the Army’s Engineering and Research Development Center (ERDC) at Vicksburg, Mississippi. These are the two key supercomputing centers for the Army, and we have written about them recently, in fact. So having two more deals for three more machines in less than a year’s time shows that the DoD is serious about having more supercomputing might on hand. And hence the funding in the High Performance Computing Modernization Program (HPCMP) keeps flowing.

The first thing that is interesting about these Army supercomputers is that Liqid is the prime contractor for all three machines – nicknamed “Jean” and “Kay” at ARL and “Wheat” at ERDC. This is pretty significant traction for a startup, and it attests to the fact that HPC sometimes means that centers have to take the risk and see how a technology plays out for realsies. This is, in fact, what HPC is supposed to do.
The ARL deal for the pair of machines, which are based on the Liqid architecture, was actually announced in late August. The pair of machines, interestingly, are based on servers built by Intel using its “Cascade Lake-AP” Xeon Platinum 9242 dual-chip modules, which have a pair of 24-core chips in each socket for a total of 48 cores, which means 96 cores per node. The Jean system has 1,202 Cascade Lake-AP processors in 601 nodes, for a total of 57,696 cores. Some of the nodes have the PCI-Express versions of the Nvidia “Ampere” A100 GPU accelerators, for a total of 280 across the Jean system, which has 512 GB of main memory per node and 12.5 PB of NVM-Express local storage across the nodes using an unspecific parallel file system. The Kay system is a little smaller, with 505 nodes, each with a pair of the double-whammy Cascade Lake-AP chips for a total of 48,480 cores with similar memory setups (it seems to vary a little across the nodes), a total of 74 Nvidia A100 GPU accelerators, and 10 PB of NVM-Express running on that unnamed parallel file system. The Liqid fabric switches are based on PCI-Express 4.0, but link to the Intel servers using PCI-Express 3.0 slots, so there will be some bandwidth downshifting there.
The Jean and Kay machines, named after Jean Bartik and Kay McNulty, programmers on the ENIAC supercomputer in the late 1940s and early 1950s, are interlinked with 200 Gb/sec InfiniBand, and together have over 15 petaflops of double-precision floating point performance for just under $32 million for the term of their contract. It looks like $25.5 million of that was used for acquiring the systems. That’s about $1,700 per teraflops if that figure is correct for the base system price, which is a lot more per unit of oomph than the buyers of per-exascale and exascale systems are paying. But that is just volume economics and prestige at play. The smaller shops have always helped to pay the way of the bigger shops – it has never not been that way.
Over at ERDC, Liqid bagged its third system for the US Army with the Wheat system, named after Roy Wheat, a decorated hero and US Marine who fought in and died in the Vietnam War by throwing himself on a bounding mine and saving the life of two fellow Marines. The $20.6 million contract that Liqid has landed is heavier on the GPUs and lighter on the CPUs but is similarly based on Intel’s Cascade Lake-AP servers (which we have to figure the US Army is getting nearly for free). The Wheat system will go live in 2021, and is rated at 17 petaflops peak double precision performance. It has 86,784 cores with a total of 391 TB of memory and 4.5 PB of flash. The Wheat system has 904 nodes in total, linked by the Liqid fabric for hooking the CPUs to the GPUs and the 200 Gb/sec InfiniBand fabric for linking the nodes to each other. The system has a total of 536 Nvidia A100 GPU accelerators, which provide the bulk of its peak floating point performance, obviously. We don’t know how much of the ERCD contract was for hardware and how much for services and support, so we can’t tell you the cost of the flops. But at the full contract level, including everything, not just the hardware, the Jean and Kay systems cost $2,133 per teraflops compared to $1,206 per teraflops for the Wheat systems.
Which is why people invest in GPUs to accelerate compute. And having spent all that money on the GPUs, the trick is to get them to be more highly utilized. That’s how you get the most use out of that iron, and with AI frameworks not based on MPI protocols, you have to have some way to dynamically allocate CPUs and GPUs to each other as workloads change.
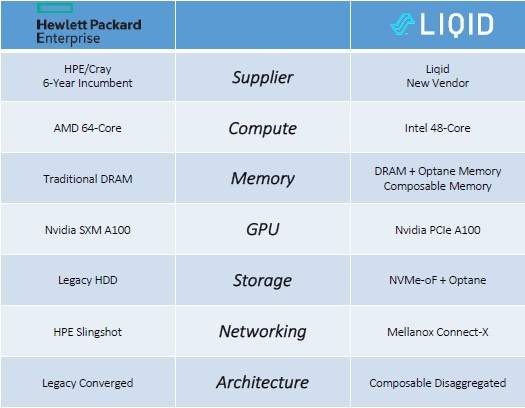
At ARL, the word on the street was that HPE/Cray was pitching a system based on 64-core AMD Epyc processors and the new SXM4 variant of the Nvidia A100 accelerators, which use NVLink to lash the GPU memories together coherently, and given that the US Army had just invested $46 million buying two Cray CS500 clusters for ARL and ERDC, last November, for machines based on AMD’s “Rome” Epyc processors and Nvidia’s “Volta” V100 GPU accelerators for a total of 10.6 petaflops, you would have thought that HPE/Cray would have been able to lock this one down.
But in the case of all three machines bought by the Army in recent weeks, the ability to disaggregate and compose the GPUs (and to a certain extent the CPUs) was more important than just getting the lowest cost peak theoretical performance on both floating point and integer calculations or scaling them out across a network. And then the ability to take SSD variants of Intel’s Optane memory and use them as composable extended main memory for the CPU nodes seems to have clinched the deal. (This is done using Intel’s Memory Drive Technology drivers, which the chip maker doesn’t talk about much because it wants to sell Optane persistent memory sticks.) And, finally, the added bonus is that linking the PCI-Express versions of the A100 GPU accelerators over the Liqid PCI-Express 4.0 fabric had performance similar to that of the NVLink-attached and more expensive A100 SXM4 GPU accelerators.
“The flexibility of the fabric was more valuable than pure bandwidth,” Sumit Puri, co-founder and chief executive officer at Liqid, tells The Next Platform. “We are using a homegrown PCI-Express version of Optane here, and we compose as much memory as you want and then we flip the drivers to treat that Optane SSD capacity like emulated DRAM.” Interestingly, the drivers can be flipped back and the same Optane SSDs can be used over PCI-Express using NVM-Express drivers as a kind of faster flash. The performance of the Liqid Optane memory cards, which it designs and manufacturers to do this, is substantially better than what Intel is itself delivering. Take a look:

The Liqid Optane card has two times the capacity and eight times the performance as the Intel device. And the cost per unit of capacity is much better, as the chart below from Liqid shows:
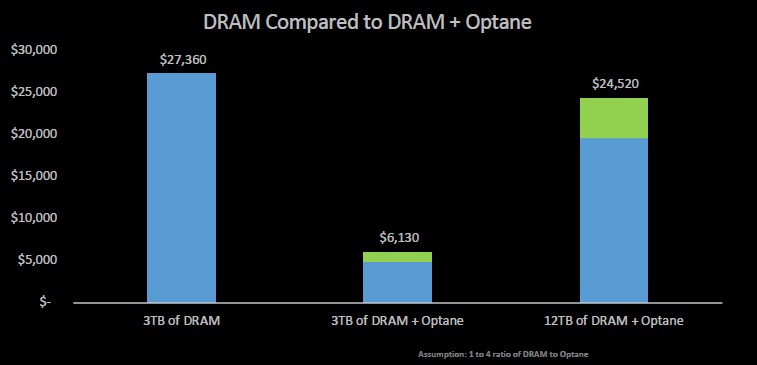
The chart above shows three different things. In the left column, that is the cost of putting 3 TB of DRAM memory into a physical server, in this case it is $27,360. Now, using a 1 to 4 ratio of DRAM to Optane SSD cards running emulated DRAM, you can get a mix of DRAM and emulated DRAM that offers similar performance (thanks to the magic of behind the scenes page caching) for $6,130, a reduction in 4.5X in cost per TB. Or, for $24,250 – about 10 percent less than that full-on DRAM block – you can use a much larger block of Optane SSDs plus a reasonably large chunk of DRAM to deliver 12 TB of usable main memory to the server node.
Now, here’s the beauty of this. Customers don’t have to decide upfront. They can use the Optane as fast storage or extended DRAM as the nature of the job requires, and they can allocate the memory and storage to composed server nodes in the ratios they need as the workloads require.
HPC schedulers like SLURM are going to need hooks into composability platforms like Liqid so they can change the hardware configurations as the workloads change. Perhaps that is part of the work that will be done here.
Anyway, here is generally what a pod of the Liqid iron looks like:

The ARL and ERDC machines are variations on these themes, but generally have a dozen or so of these pods to create the system. The three rack pods are all interlinked using PCI-Express fabrics, and the dozen pods are interlinked to each other using 200 Gb/sec InfiniBand. Composability happens within these pods, but Puri says that there is no reason that it cannot be extended across InfiniBand if required. Obviously, the latency and bandwidth will be different, and the speed of light also comes into play across longer distances, which PCI-Express cannot support.
It will be interesting to see how more HPC systems – and bigger ones – start incorporating ideas of disaggregation and composability. That has not been a requirement in any of the contracts we have heard about, but we strongly suspect this will change.


Datacenter Is The New Unit Of Compute, Open Networking Is How To Automate It
Datacenters have evolved from physical servers, to virtualized systems, and now to composable infrastructure where resources such as storage and persistent memory are disaggregated from the server. At the same time, processing has evolved from running only on CPUs to accelerated computing running on GPUs, DPUs, or FPGAs to handle …
CXL Borgs IBM’s OpenCAPI, Weaves Memory Fabrics With 3.0 Spec
System architects are often impatient about the future, especially when they can see something good coming down the pike. And thus, we can expect a certain amount of healthy and excited frustration when it comes to the Compute Express Link, or CXL, interconnect created by Intel, which with the absorption …
In A Peer-To-Peer Datacenter, PCI-Express Fabrics Will Be Pervasive
Supercomputers are expensive, and getting increasingly so. Even if they are delivering impressive performance gains over the past decade, modern HPC workloads require an incredible amount of performance, and this is particularly true of any workload that is going to blend together traditional HPC simulation and modeling with some sort …
Hi, In the DRAM chart, consider including the TOTAL costs b/c to use more than 1TB of pRAM per pSOCKET, you must use the Intel(L/M) pCPUs which can handle that much pRAM. The $ of those can quickly erase and change those graphs. We’ve run these #’s on 3TB – 6TB 2/4 pSOCKET setups and we could not make the play on CapEx alone. Certain specific workloads will benefit as would some licensing costs offsets which is where the real avoidance may be achieved. In a heavily virtualized workloads, with high bin-packing, you also have to be careful if intense CPU workloads are part of the profile. Systems can quickly run out of GHz too. Finding the right balance is key.