
We have been excited about the possibilities of adding tiers of memory to systems, particularly persistent memories that are less expensive than DRAM but offer similar-enough performance and functionality to be useful.
In particular, we have been strong advocates for disaggregating DRAM memory from the CPUs that make use of it and for the creation tiers of pooled memory that are shared by many systems, thus driving massive memory capacity expansion and the kind of utilization that has been common in storage area networks in the enterprise datacenter for decades now.
But prying apart the memory hierarchy and jamming in some new hardware doesn’t magically enable that new tier – or tiers – to be immediately useful. Very clever systems software has to be created transparently make use of that new memory. We say transparent – and that is a good word for it, as hyperscaler Meta Platforms and its Facebook social network division knows full well – because in order for this new, disaggregated memory to be accepted, it cannot mean that applications have to be rewritten to exploit the new memory technology and tier. This all has to happen under the skins and within the operating system kernel – in this case, the Linux kernel – because even a hyperscaler like Facebook, with legions of PhDs working as software engineers, cannot afford to go back and rewrite – and debug – its entire stack of code.
It is the very nature of the hyperscalers (along with cloud builders and HPC centers) to push the technology envelope, and Facebook has been working for years on disaggregating and pooling memory in an effort to make memory work better in its fleet of servers and to try to rein in the cost of memory while at the same time boost its performance.
The social network has been working with Mosharaf Chowdhury, assistant professor at the University of Michigan, on memory pooling technologies for many years, starting with the Infiniswap Linux kernel extension that pooled memory over the RDMA protocol on top of InfiniBand or Ethernet, which we profiled way back in June 2017 when it was revealed. Infiniswap was a kind of memory load balancer across the servers, and it debuted as several different transports and memory semantic protocols emerged in the market – the OpenCAPI Memory Interface protocol from IBM, the CCIX protocol from Xilinx, the NVLink protocol from Nvidia, the Gen-Z protocol from Hewlett Packard Enterprise and championed by Dell – with similar ideas about memory pooling.
At this point, when it comes to memory pooling in the rack at least, Intel’s CXL protocol, which runs atop the PCI-Express 5.0 and faster controllers that will be common in new and future servers, has emerged as the dominant standard for disaggregated memory, and not just for linking the far memory in accelerators and as well as flash memory to CPUs, but in the future as a means of moving DRAM near memory to the PCI-Express bus and creating a new class of CXL DRAM main memory.
As a consequence, Chowdhury and fellow researchers at what is now called Meta Platforms are taking another run at the idea of disaggregated memory, moving some of the ideas of Infiniswap forward with a Linux kernel extension called Transparent Page Placement, or TPP, which does memory page management in a slightly different way from how DRAM main memory attached to a CPU is done and takes into account the relative farness of CXL main memory. The researchers have outlined this more recent work in a paper, which you can read here.
The TPP protocol, which Meta Platforms has open sourced and moved upstream in the Linux kernel development cycle, is being paired with the company’s Chameleon memory tracking tool, which runs in Linux user space and which also will be open sourced so people can track how well or poorly CXL memory works for their applications. It is also a way of keeping track of how well or poorly NUMA balancing and AutoTiering, two existing techniques for managing memory pages on Linux machines across multiple processors using NUMA protocols, works and how this technique compares to the TPP protocol when CXL memory is involved.
Expanding The Memory Hierarchy From the Middle Out
If transistors cost nothing and chip die area was infinite, all memory would be SRAM extremely local to the compute. And in fact, FPGAs and their offspring like the matrix processors created by Cerebras, GraphCore, and SambaNova Systems all have local SRAM memories to get very tiny memories next to very tiny processor cores and have an aggregate bandwidth that is many times higher than what you can get with a GPU accelerator. But the capacity, as we say, is not huge and the cost is large.
And so, with the evolution of CPUs, system architects moved up and down from main memory, adding one, two, three, and sometimes four levels of cache between the cores and the main memory and out over the system bus to tape, then disk and tape, and then flash, disk, and tape. In more recent years, we have added persistent memory like 3D XPoint.
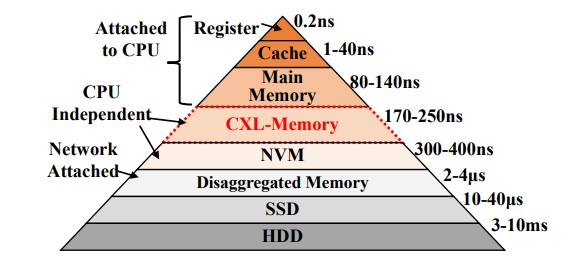
And now, as we, Meta Platforms, MemVerge, and a slew of other system makers believe, we are going to have CXL main memory coming off CPUs, and that CXL memory will look and feel like a regular NUMA socket, but one without any CPU in it. And, if Meta Platforms is right with the TPP protocol it has created, it will have a different memory paging system that better deals with the slightly higher latencies and other eccentricities that come with having lots of pooled memory outside of the server motherboard.
Here is what Facebook has been up against when it comes to memory capacity, bandwidth, power, and cost in several generations of its machines:
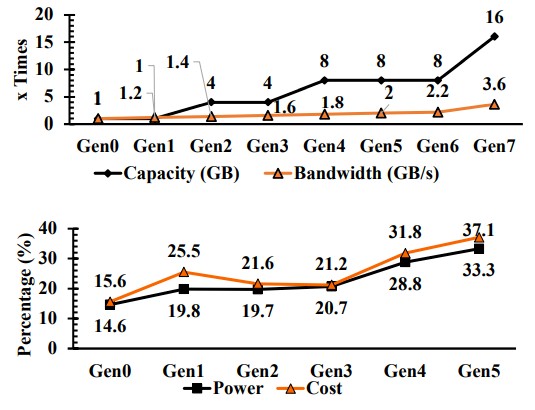
As you can see, memory capacity rises faster than memory bandwidth, which has had important implications for performance. If bandwidth was higher – a lot higher – it might require less memory capacity to do a certain amount of work on a set number of CPU cores. Just like if the clock speed of a CPU was 10 GHz it would be a lot better than 2.5 GHz. But faster CPU and memory clocks generate exponentially more heat, so you can’t do it and therefore system architecture bends itself in all kinds of ways to try to do more work and stay within a reasonable power envelope.
But it doesn’t work. The system power and the memory power on each server generation keeps going up, driven by the need for more performance, and the cost of the memory as a share of the total system cost keeps going up, too. At this point, main memory – not the CPU itself – is the dominant cost in the system. (This is true at Facebook and in the world at large.)
So we are basically having to move main memory to the PCI-Express bus, using the CXL protocol overlay, to expand the memory capacity and memory bandwidth in the system in a way that doesn’t add more memory controllers onto the CPU dies. There is a little bit of a latency delay in this memory, as you can see in the chart below, but it is on the same order of magnitude as a NUMA link between two CPUs in a shared memory system:
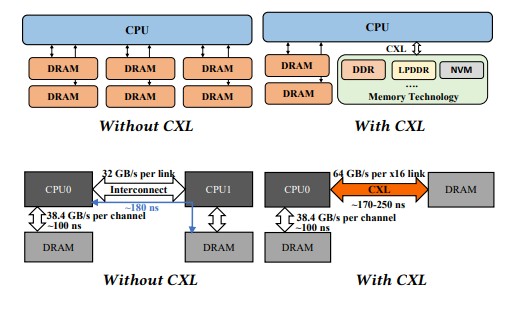
So, now you have this CXL memory that you can beef the system up with. You could, for instance, buy skinnier and cheaper memory sticks and drive up the aggregate memory bandwidth over the DDR controllers and PCI controllers, getting cost down, bandwidth up, and capacity up or flat or even down as you see fit.
The trick in trying to figure out how to use CXL memory, just as was the case with Optane 3D XPoint DIMMs and flash of various speeds, is to figure out how much of what you are using in memory is hot, warm, or cold and then figure out a mechanism to get the hot data on the fastest memory, the cold data on the coolest memory, and the warm data on the warm memory. You also need to know how much data is on each temperature tier so you can get the right capacities. That is what the Chameleon tool created by Meta Platforms and Chowdhury is all about.
Meta Platforms picked the four most popular applications running across its fleet of servers – a Web tier with a just in time compiler and runtime, two layers of caching between the Web and the back-end databases that house Facebook data, and a data warehouse that runs complex queries across terabytes of memory and that can take days to complete, according to the paper. Each stage of the queries is checkpointed out to disk, just like HPC shops have been doing for decades, because no one wants to run queries like this again.
Here’s what the Chameleon tool showed about these workloads as they run:
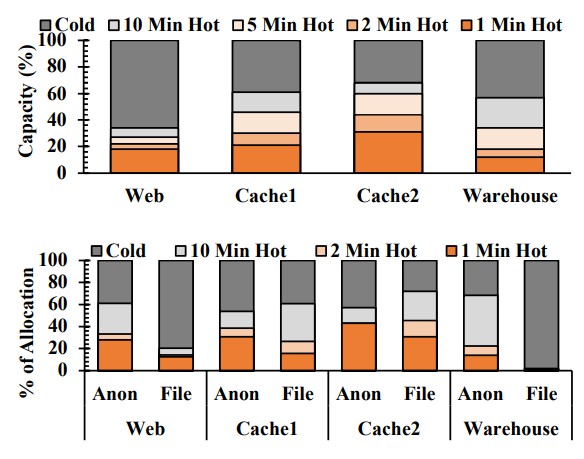
The top set of charts shows the levels of heat on the data by workloads, and obviously, the colder the data, the more reasonable it is to move it to CXL memory. Now, there are two different kind of memory page types in the top set of charts, and the bottom set shows the heat distribution for anonymous and file pages. Anon pages tend to stay hotter than file pages, and Meta Platforms says that applications tend to have a fairly steady memory usage pattern, with some variance. These factors are also important to know.
Meta Platforms tried to use the NUMA balancing algorithms in the Linux kernel (also sometimes called AutoNUMA) to balance memory pages across regular DDR main memory and CXL main memory, and also analyzed the memory page reclamation technique in the Linux kernel. The basic workings of these processes are shown here:
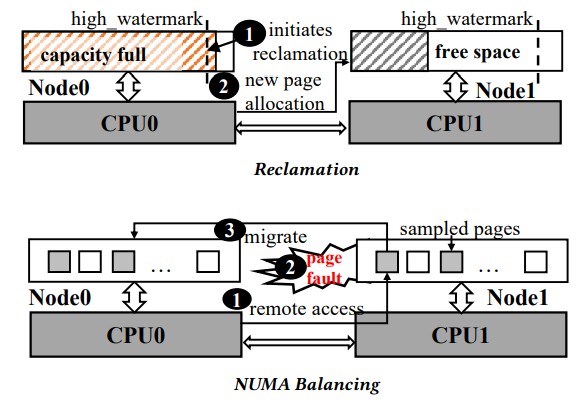
Basically, Linux tries to allocate data for processing as close to the CPU that is going to be doing the processing, but there is always contention and sometimes it has to be pushed out to adjacent NUMA regions where another CPU has the memory attached. Data is shuffled around, with hot data for each CPU kept as close to that CPU and pushed out to others. Linux allocated pages for CPUs, and when it gets under pressure, it pushes data to other regions and reclaims memory capacity as applications need memory space. Sometimes this can strand hot data out in a different NUMA region, casual extra latency and application performance degradation. This paging mechanism, therefore, is not really good for CXL memory.
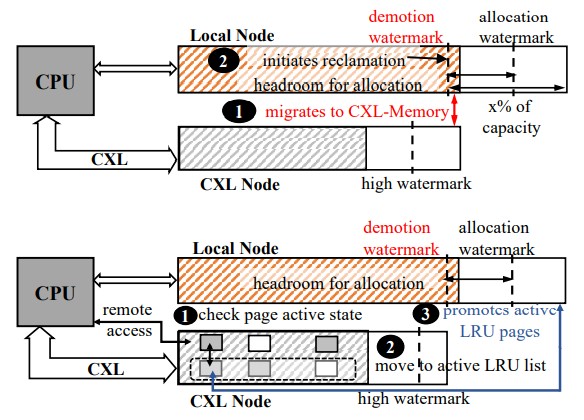
With TPP, the allocation of memory pages and the reclamation of memory pages by the CPU are decoupled from each other, and mechanisms are added so data can be pushed and pulled from CXL memory into CPU main memory as needed. The reclamation rate is 44X faster with the TPP protocol than the default mechanisms in the Linux kernel, and instead of degrading performance by adding CXL memory (which happened) the system offers 99.5 percent of the same performance as having the same memory capacity (local DDR plus CXL memory) on the local node.
The net-net of this is that the first pass of the TPP protocol, say the researchers, is that TPP outperformed the AutoNUMA NUMA balancing mechanisms within the Linux kernel by between 10 percent and 17 percent, depending on the workload, and that that the performance of the Linux applications tested increased by an average of 18 percent. That’s a pretty good place to start with CXL memory.

Photonics To Make Celestial HBM3 Memory Fabric
There is no shortage of silicon photonics technologies under development, and every few months it seems like another startup crops up promising massive bandwidth, over longer distances, while using less power than copper interconnects. Celestial AI is the latest contender to enter this space, having popped back up after a …

Talking System Architecture With AMD CTO Mark Papermaster
It is funny to think that in a certain light, AMD has Big Blue to thank for its resurgence in the datacenter. And not because IBM is not good at crafting processors and interconnects, but because some of the seasoned executives who honed their skills in semiconductors at IBM ended …

Intel “Emerald Rapids” Xeon SPs: A Little More Bang, A Little Less Bucks
With each successive Intel Xeon SP server processor launch, we can’t help but think the same thing: it would have been better for Intel and customers alike if this chip was out the door a year ago, or two years ago, as must have been planned. The new “Emerald Rapids” …
A comparison of the latency and coherency of IBM’s Power10 memory inception versus CXL memory framed in the context of large-socket NUMA architectures and the newly developed Linux TPP memory layer would be interesting.
The question in my mind is whether TPP could also benefit Linux on Power10 at both multisocket NUMA and memory inception levels.
It would be interesting to see the CXL management made a service on a SmartNIC/IPU/DPU/XPU that could aggregate the server before boot, monitor and disaggregate as requested, perhaps from a control console/utility. Could collect activity and performance statistics as well.
Not the only thing the XPU would do, but a useful basic add-on facility.
That is an interesting set of ideas.
more info on meta’s use of the tiered memory for DLRM models in their youtube presentation, “Intel Optane Memory Requirements of Meta AI Workloads”.
so, cxl is enabling easier handling of tiered memory. Intel is moving Optane to a cxl memory memory pool. Looks like Meta will be a customer.