

From the moment the first rumors surfaced that AMD was thinking about acquiring FPGA maker Xilinx, we thought this deal was as much about software as it was about hardware.
We like that strange quantum state between hardware and software where the programmable gates in FPGAs, but that was not as important. Access to a whole set of new embedded customers was pretty important, too. But the Xilinx deal was really about the software, and the skills that Xilinx has built up over the decades crafting very precise dataflows and algorithms to solve problems where latency and locality matter.
After the Financial Analyst Day presentations last month, we have been mulling the one by Victor Peng, formerly chief executive officer at Xilinx and now president of the Adaptive and Embedded Computing Group at AMD.
This group mixes together embedded CPUs and GPUs from AMD with the Xilinx FPGAs and has over 6,000 customers. It brought in a combined $3.2 billion in 2021 and is on track to grow by 22 percent or so this year to reach $3.9 billion or so; importantly Xilinx had total addressable market of about $33 billion for 2025, but with the combination of AMD and Xilinx, the TAM has expanded to $105 billion for AECG. Of that, $13 billion is from the datacenter market that Xilinx has been trying to cater to, $33 billion is from embedded systems of various kinds (factories, weapons, and such), $27 billion is from the automotive sector (Lidar, Radar, cameras, automated parking, the list goes on and on), and $32 billion is from the communications sector (with 5G base stations being the important workload). This is roughly a third of the $304 billion TAM for 2025 of the new and improved AMD, by the way. (You can see how this TAM has exploded in the past five years here. It’s remarkable, and hence we remarked upon it in great detail.)
But a TAM is not a revenue stream, just a giant glacier off in the distance that can be melted with brilliance to make one.
Central to the strategy is AMD’s pursuit of what Peng called “pervasive AI,” and that means using a mix of CPUs, GPUs, and FPGAs to address this exploding market. What it also means is leveraging the work that AMD has done designing exascale systems in conjunction with Hewlett Packard Enterprise and some of the major HPC centers of the world to continue to flesh out an HPC stack. AMD will need both if it hopes to compete with Nvidia and to keep Intel at bay. CUDA is a formidable platform, and oneAPI could be if Intel keeps at it.

“When I was with Xilinx, I never said that adaptive computing was the end all, be all of computing,” Peng explained in his keynote address. “A CPU is going to always be driving a lot of the workloads, as will GPUs. But I’ve always said that in a world of change, adaptability is really an incredibly valuable attribute. Change is happening everywhere you hear about it, the architecture of a datacenter is changing. The platform of cars is totally changing. Industrial is changing. There is change everywhere. And if hardware is adaptable, then that means not only can you change it after it’s been manufactured, but you can change it even when it’s deployed in the field.”
Well, the same can be said of software, which follows hardware of course. Even though Peng didn’t say that. People were messing around with SmallTalk back in the late 1980s and early 1990s after it had been maturing for two decades because of the object oriented nature of the programming, but the market chose what we would argue was an inferior Java only a few years later because of its absolute portability thanks to the Java Virtual Machine. Companies not only want to have the options of lots of different hardware, tuned specifically for situations and workloads, but they want the ability to have code be portable across those scenarios.
This is why Nvidia needs a CPU that can run CUDA (we know how weird that sounds), and why Intel is creating oneAPI and anointing Data Parallel C++ with SYCL as its Esperanto across CPUs, GPUs, FPGAs, NNPs, and whatever else it comes up with.
This is also why AMD needed Xilinx. AMD has plenty of engineers – well, north of 16,000 of them now – and many of them are writing software. But as Jensen Huang, co-founder and chief executive officer of Nvidia explained to us last November, three quarters of Nvidia’s 22,500 employees are writing software. And it shows in the breadth and depth of the development tools, algorithms, frameworks, middleware available for CUDA – and how that variant of GPU acceleration has become the de facto standard for thousands of applications. If AMD s going to have the algorithmic and industry expertise to port applications to a combined ROCm and Vitis stack, and do it in less time than Nvidia took, it needed to buy that industry expertise.
That is why Xilinx cost AMD $49 billion. And it is also why AMD is going to have to invest much more heavily in software developers than it has in the past, and why the Heterogeneous Interface for Portability, or HIP, API, which is a CUDA-like API that allows for runtimes to target a variety of CPUs as well as Nvidia and AMD GPUs, is such a key component of ROCm. It gets AMD going a lot faster on taking on CUDA applications for its GPU hardware.
But in the long run, AMD needs to have a complete stack of its own covering all of the AI use cases across its many devices:
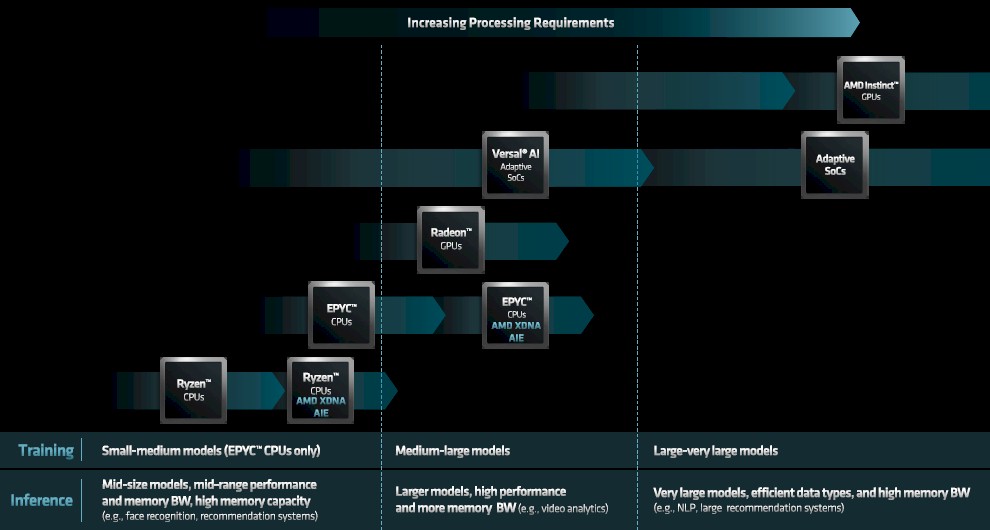
That stack has been evolving, and Peng will be steering it from here on our with the help of some of those HPC centers that have tapped AMD CPUs and GPUs as their compute engines in pre-exascale and exascale class supercomputers.
Peng didn’t talk about HPC simulation and modeling in his presentation at all and only lightly touched on the idea that AMD would craft an AI training stack atop of the ROCm software that was created for HPC. Which makes sense. But he did show how the AI inference stack at AMD would evolve, and with this we can draw some parallels across HPC, AI training, and AI inference.
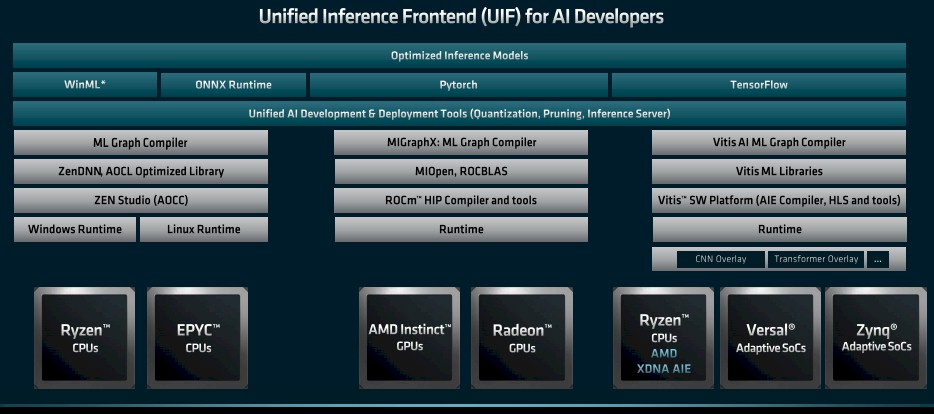
Here is what the AI inference software stack looks like for CPUs, GPUs, and FPGAs today at AMD:

With the first iteration of its unified AI inference software – which Peng called the Unified AI Stack 1.0 – the software teams at AMD and the former Xilinx are going to create a unified inference front end that can span the ML graph compilers on the three different sets of compute engines as well as the popular AI frameworks, and then compile code down to those devices individually.
But in the long run, with the Unified AI Stack 2.0, the ML graph compilers are unified and a common set of libraries span all of these devices; moreover, some of the AI Engine DSP blocks that are hard-coded into Versal FPGAs will be moved to CPUs and the Zen Studio AOCC and Vitis AI Engine compilers will be mashed up to create runtimes for Windows and Linux operating systems for APUs that add AI Engines for inference to Epyc and Ryzen CPUs.
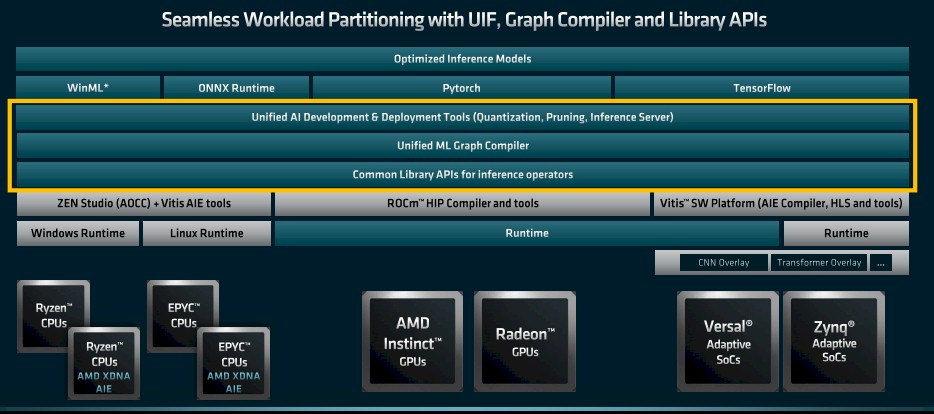
And that, in terms of the software, is the easy part. Having created a unified AI inferencing stack, AMD has to create a unified HPC and AI training stack atop ROCm, which again is not that big of a deal, and then the hard work starts. That is getting the close to 1,000 key pieces of open source and closed source applications that run on CPUs and GPUs ported so they can run on any combination of hardware that AMD can bring to bear – and probably the hardware of its competitors, too.
This is the only way to beat Nvidia and to keep Intel off balance.




Be the first to comment