

It is always an exciting time when there is a new compute engine coming into the market, and interest is particularly keen with any new Arm server chip entry. At this point, Amazon Web Services is by far the biggest consumer of Arm-based server processors in the world, with its homegrown Graviton lineup of CPUs and Nitro lineup of DPUs. The latter is in all of the company’s servers to offload network, security, and storage processing from server CPUs, and the former is becoming an increasingly large part of the AWS server fleet, which measures in the millions of machines.
At the AWS re:Invent conference this week, chief executive officer Adam Selipsky briefly talked about the next-generation of Graviton3 processors that the Annapurna Labs chip design division of the cloud computing giant has designed and gotten back from foundry partner Taiwan Semiconductor Manufacturing Co, but Selipsky didn’t give out a lot of the feeds and speeds that we like to see to make comparisons with prior Graviton generations, other Arm server chips, and other X86 and Power processors in the market today. Peter DeSantis, senior president of utility computing at AWS, gave a keynote that provided a little more detail on Graviton3, thankfully, and some other details have leaked out in another session that we have not been able to see as yet but which provides even more insight into what Amazon is doing.
In our impatience, as we wait for some feedback from AWS, we have taken a stab at trying to figure out how the Graviton3 might be configured and what impact it might have on the AWS fleet in the coming year when it is expected to be more broadly available through EC2 instances.
Let’s start with what we know. Here is the chart that Selipsky showed:

And here is a picture of a three-node Graviton3 server tray that DeSantis showed along with some basic feeds and speeds.

If you have been thinking that AWS was going to be getting on the Core Count Express and drive up to 96 cores or 128 cores with Graviton3, and use a process shrink to 5 nanometers to help drive frequency a little too, you will be surprised to learn that the cloud provider is instead standing pat at 64 cores and barely changing clock speed, with a 100 MHz bump up to 2.6 GHz in the move from Graviton2, which we detailed at launch here and which we did a price/performance analysis of there when X2 and R6 instances were available, to Graviton3.
Just to level set, here is a table we have cooked up showing the feeds and speeds of the three generations of Graviton processors:
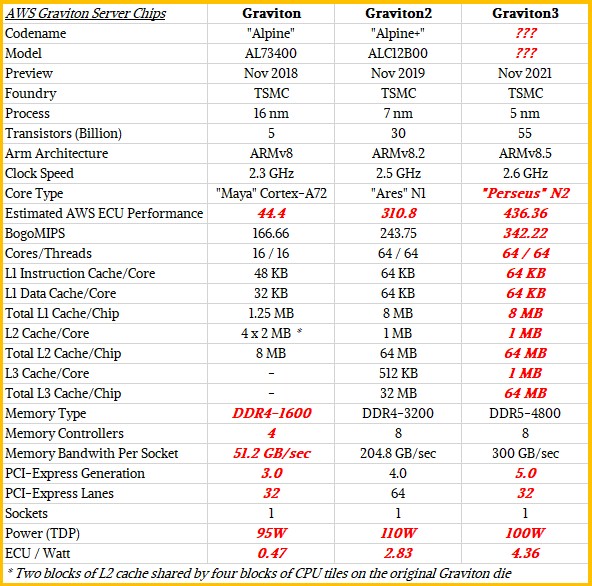
Items in bold red italics are estimates in lieu of data that AWS has not provided.
DeSantis was very clear why AWS is moving in the direction it did with the Graviton3 chip in his keynote address.
“As I said last year, the most important thing we are doing with Graviton is staying laser-focused on the performance of real-world applications – your applications,” DeSantis explained. “When you are developing a new chip, it can be tempting to design a chip based on these sticker stats – processor frequency or core count. And while these things are important, they are not the end goal. The end goal is the best performance and the lowest cost for real workloads.”
Wait a minute. That doesn’t sound like something Intel or AMD would say. … And that is why hyperscalers and cloud builders are designing their own silicon. They have the critical mass to be able to afford it, and they are interested in profiting on services and spending the least amount possible on silicon they control.
Rather than try to make the Graviton3 chip bigger with more cores or faster with more clock speed, what AWS did instead was make the cores themselves a lot wider. And to be very precise, it looks like AWS moved from the “Ares” Neoverse N1 core from Arm Holdings, used in the Graviton2, to the “Perseus” Neoverse N2 core with Graviton3.
There is some talk that it is using the “Zeus” V1 core, which has two 256-bit SVE vectors, but the diagrams we have seen only show a total of 256-bits of SVE, and the N2 core has a pair of 128-bit SVE units, so it looks to us like it is the N2 core. We are looking for confirmation from AWS right now. The V1 core was aimed more at HPC and AI workloads than traditional, general purpose compute work. (We detailed the Neoverse roadmap and the plan for the V1 and N2 cores back in April.)
AWS is also apparently moving to a chiplet design of sorts, but not in the way that AMD has done and Intel will be doing with their respective Epyc and Xeon SP CPUs.
The V1 core is wider on a lot of measures than the N1 core, and it is this fact that is allowing for AWS to drive more performance. There are also wider vector units, 256-bit SVE units to be precise, that allow for wider pieces of data to be chewed on, and often at lower precision for AI workloads in particular, thus driving up the performance per clock cycle by a lot.
The N1 core used in the Graviton2 chip had an instruction fetch unit that was 4 to 8 instructions wide and 4 wide instruction decoder that fed into an 8 wide issue unit that included two SIMD units, two load/store units, three arithmetic units, and a branch unit. With the Perseus N2 core used in the Graviton3, there is an 8 wide fetch unit that feeds into a 5 wide to 8 wide decode unit, which in turn feeds into a 15 wide issue unit, which is basically twice as wide as that on the N1 core used in the Graviton2. The vector engines have twice as much width (and support for BFloat16 mixed precision operations) and the load/store. arithmetic, and branch units are all doubled up, too. To get more performance, compilers have to keep as many of these units doing something useful as possible.
According to the report in SemiAnalysis, which is presumably based on a presentation given at re:Invent 2021, the 64 cores on the Graviton3 chip are on one chiplet, and two PCI-Express 5.0 controllers have a chiplet each and four DDR5 memory controllers have a chiplet each, for a total of seven chiplets. These are linked together using a 55 micron microbump technology, and the Graviton3 package is soldered directly to a motherboard rather than put into a socket. All of this cuts costs and, importantly, reduces the heat that might have otherwise been generated to push signals over much fatter bumps. We are circling back with AWS to learn more about this. Stay tuned.
The important thing to note in the Graviton3 design is not the cores, but the DDR5 memory and the PCI-Express 5.0 peripherals that will be used to keep those cores fed. The Graviton3 is the first to deliver PCI-Express 5.0 and DDR5, and the former can deliver high bandwidth with half as many lanes as its PCI-Express 4.0 predecessor while the latter can deliver 50 percent more memory bandwidth with the same capacity and in the same power envelope. When you are AWS, you can control your hardware stack and get someone to make a PCI-Express 5.0 controller and DDR5 memory sticks for you and be at the forefront of a technology. We think the L1 and L2 caches on the N2 cores that Graviton3 uses will be the same as with Graviton2, but that the L3 cache will be doubled up. But as the red bold italics shows, this is just a guess on our part.
Here is how the memory bandwidth stacks up per vCPU on the three different Graviton processors on the four different EC2 instances:
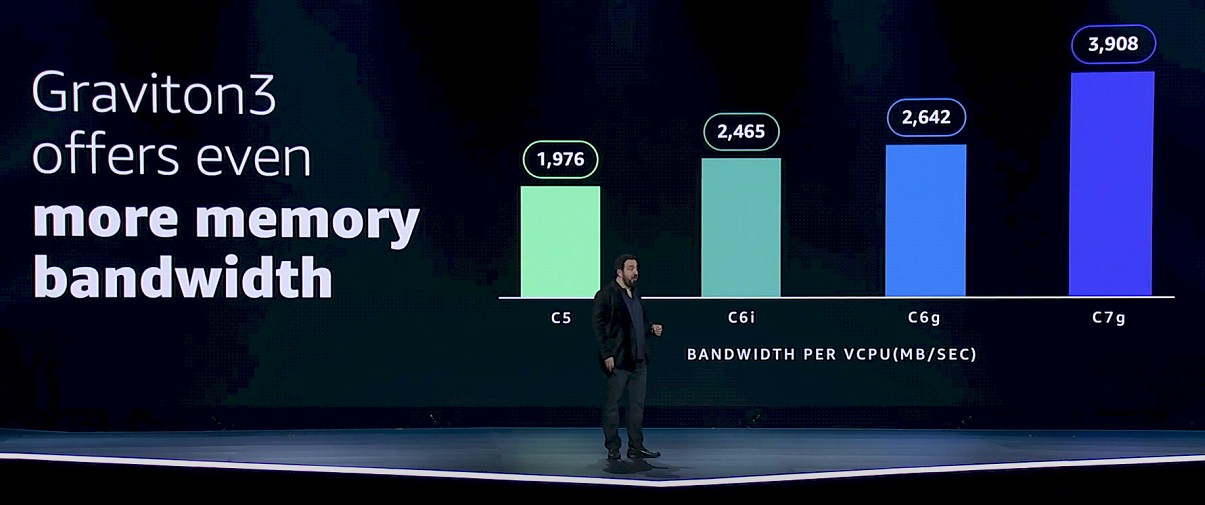
These appear to be measured bandwidth using a benchmark, not peak theoretical memory bandwidth. Our guess is that it is the STREAM Triad memory test.
There was talk about Graviton3 using 60 percent less power than Graviton2, but we think that this was talking about special cases and as far as we can tell, Graviton3 will be in about the same 100 watt thermal design point. We will try to get clarification on this from AWS. There is also a lot of talk out there that Graviton3 is an ARMv9 architecture chip, but it is not if it is using either the V1 core or the N2 core, which it is. ARMv9 is coming, but not quite yet. Look for that with Graviton4 perhaps.
The performance improvements for applications moving from Graviton2 to Graviton3 will vary according to the nature of the applications. Here is what the performance improvements look like for web infrastructure workloads:
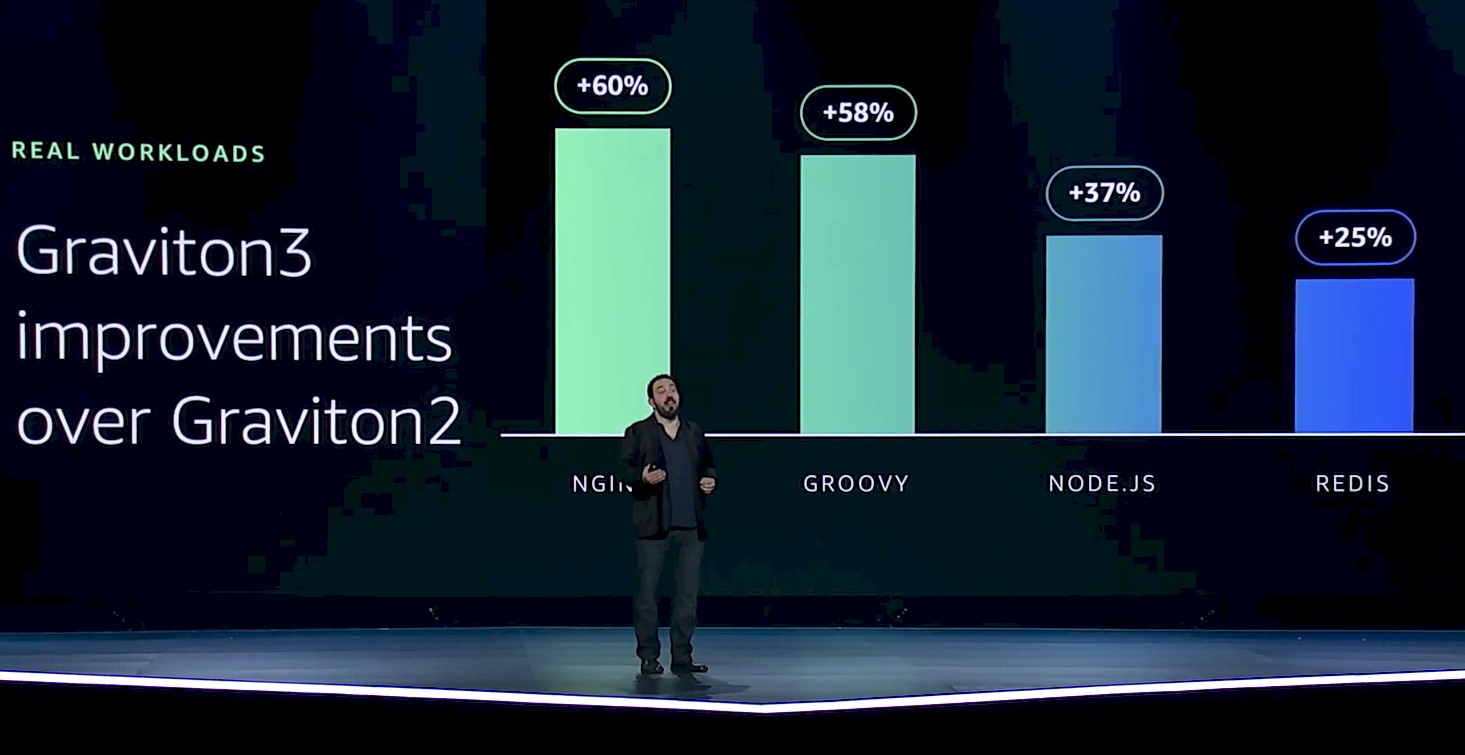
That 25 percent performance improvement cited was a low-end estimate, not an average to be taken literally. As you can see, the NGINX web server is seeing a 60 percent performance boost moving to the Graviton3.
There are similar performance improvements for applications that have elements of their code that can be vectorized, such as video encoding and encryption, and run through those SVE units:

One such workload that can be run through those SVE vector units is machine learning inference, and here is where Graviton3 is really going to shine with support for BFloat16 capability across those 256-bits of vector:

We strongly suspect that the middle bar in the chart above is supposed to read Graviton3 – FP32, not Graviton2 – FP32. And as people who move fast and make our share of typos, we are not going to judge at all. …
We look forward to providing a deeper dive on Graviton3 as soon as we can.


AWS Adopts Arm V2 Cores For Expansive Graviton4 Server CPU
For more than a year, we have been expecting for Amazon Web Services to launch its Graviton4 processor for its homegrown servers at this year’s re:Invent, and lo and behold, chief executive officer Adam Selipsky rolled out the fourth generation in the Graviton CPU lineup – and the fifth iteration …
Google Follows Suit With Microsoft On Ampere Arm Instances
A long time ago, when we first started The Next Platform, Urs Hölzle, then senior vice president of the Technical Infrastructure team at Google, told us that to gain a 20 percent improvement in price/performance it would absolutely change from the X86 architecture to Power architecture – or indeed any …

Finally: AWS Gives Servers A Real Shot In The Arm
Finally, we get to test out how well or poorly a well-designed Arm server chip will do in the datacenter. And we don’t have to wait for any of the traditional and upstart server chip makers to convince server partners to build and support machines, and the software partners to …
I think Marvell were the first to deliver PCI-E 5.0 and DDR5 on Octeon 10 DPU platform.
Until there’s a breakthrough in terms of memory density and performance, it doesn’t make sense to go beyond a 64 core count.
Considering the form factor of dual CPU sockets, that’s 128 cores. (virtual cores / hyper threading) could increase that to 256vCores. At that density, you’d need ~2TB of memory to get the most out of that high a count, not to mention other components like the bus architecture and networking. Considering power,heat, etc… 64 cores is a good stopping point.