
A long time ago, when we first started The Next Platform, Urs Hölzle, then senior vice president of the Technical Infrastructure team at Google, told us that to gain a 20 percent improvement in price/performance it would absolutely change from the X86 architecture to Power architecture – or indeed any other architecture – and even for one generation of machines.
While that may be true for internal-facing workloads like search or ad serving or video streaming where Google has built a system whereby its applications can automagically target X86, Power, or Arm CPU processors, the situation is a bit more complex for the infrastructure that the company puts up for sale on its Google Cloud. In this case, Google can be a little ahead of its customers, but not too far ahead, and it has to have a compelling reason to adopt a new compute engine.
That compelling reason to think about deploying Arm CPUs on Google Cloud is the fairly rapid pace at which Amazon Web Services is deploying its Graviton family of homegrown Arm server chips, culminating with the very respectable Graviton3 chiplet complex and their c7g instances that are now ramping. And in April, Microsoft recently partnered with Ampere Computing to bring its Altra Arm server chips to the Azure cloud, which we went into great detail about here. Now Google has joining the fight, event after explaining back in June 2021 that it could meet or beat the price/performance of the Graviton chips at AWS with its Tau instances, which started out with AMD “Milan” Epyc processors with the “golden ratio” of cores and clock speeds to be tuned up for the best bang for the buck.
So much for that idea, especially once the Graviton3 chips came out and Microsoft backed the Ampere Computing’s Altra. Which, by the way, had already been adopted by Alibaba, Baidu, Tencent, and Oracle for at least some of their server infrastructure. Who knows what Facebook is doing to complete the hyperscaler set, but they are not a cloud builder – unless they start showing some sense – so that doesn’t much matter. We suspect these clouds will all start peddling the 128-core Altra Max processors before too long and that they are eagerly engaged with the Ampere Computing roadmap for future processors.
Rumor had it that Google was going to adopt Ampere Computing’s Altra line of Arm server processors for its, and now that rumor has panned out with the Tau T2A instances, which are shown below next to the Tau T2D instances based on a custom Epyc 7B13 processor from AMD:
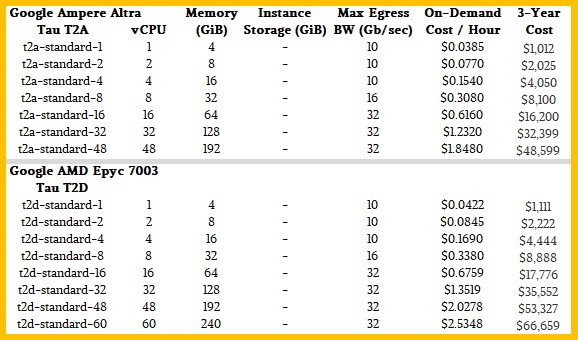
Google is putting 4 GB of memory per core on its Altra instances, but they top out at 48 cores and that means 48 vCPUs because Ampere Computing does not believe in simultaneous hyperthreading. The reason why is that it creates non-deterministic performance and that leads to long tail latencies on applications sometimes. That 4 GB per core is the same ratio of compute to memory that Microsoft Azure used with its instances based on the “Quicksilver” Altra processors. These Altra processors have eight DDR4 memory controllers, so it would be possible to build a very hefty memory configuration if either Microsoft or Google were so inclined – and in the future, they might be. The Graviton3 chips are only configured with 2 GB per core with the C7g instances that have debuted, and we don’t expect for that to double up to 4 GB per core until the M7g instances are launched by AWS sometime in the future.
Interestingly, neither Microsoft nor Google are selling instances that have the full 80 cores of the Quicksilver chips exposed on their largest instance. Microsoft tops out at 64 cores, and Google I stopping at 48 cores. They may be buying cheaper SKUs, Ampere Computing and its foundry partner, Taiwan Semiconductor Manufacturing Co, might not be able to make very many 64-core, 72-core, or 80-core parts, and hence they are not appropriate for the kind of volumes that the hyperscalers and cloud builders need. These companies like to have as few variations in their infrastructure as they can get, given the diverse needs their cloud customers have (and their internal hyperscaler workloads often require). Microsoft probably has a DPU of some sort attached to these, and Google might be using an early edition of the “Mount Evans” DPU on these server nodes, so do not jump to the conclusion that the extra cores are being used up by network and storage processing overhead. The Google Tau servers are based on single-socket designs – or at least were with the AMD Epyc version – and it is not clear if Microsoft is using a single-socket or two-socket variant in its Azure D and E series instances.
What we want to know, and what no one is talking about, is whether Google is using Arm server instances internally, and if that use predated the adoption of Quicksilver chips by Google Cloud. We suspect that to be the case, but it could turn out that Google is investing first in the cloud and then exposing it as an infrastructure type for its Borg and Omega cloud controllers, which manage the distribution of its search, ad serving, email, and other production workloads. Out guess is the tires get kicked on the server iron running internal hyperscale workloads before slices of that infrastructure are made available for public consumption. For instance, a 128-core “Siryn” Altra Max processor with relatively deterministic performance and all cores running at 3.5 GHz thanks to a fixed clock speed might make a nice search engine thresher.
Ultimately, what everyone wants to know is how the Arm server slices sold by the big three clouds in the United States and Europe compare to each other and to the X86 instances most similar to them from Google, Microsoft, and AWS. So we ginned up this little table, based on the performance information given by Microsoft Azure for its instance comparisons back in April. We extended this to cover the most similar instances for Google Cloud and AWS. Take a look:

There is a certain amount of witchcraft in those SPEC integer rate 2017 CPU benchmark estimates, shown in bold red italics, and we know that. But based on the custom processors and some relative performance metrics from Google and AWS, we can make some pretty intelligent guesses. Do not assume that performance and price/performance scale linearly up and down any vendor’s product line – in general, price does scale linearly as vCPUs are added across all of the vendors, and in the case of the Google Tau T2A instances and the Microsoft Azure D series instances, Google chose the same exact prices that Azure published using the same configurations of Altra cores and DDR4 memory. (That is the first time we have seen that.)
You will note in the chart above that the Arm server chips are offering the best bang for the buck in terms of raw integer performance, roughly around 40 percent to 45 percent better than the X86 variants. The M7g instances will cost more than the C7g instances shown because they will have a little more memory, or AWS will have to drop the price on the existing C7g instances to compete with the Altra instances at Google and Microsoft. (We think the latter.) The AMD Epyc 7003 can scale to 64 cores rather than to only 40 cores for the Intel “Ice Lake” Xeon SPs shown in the table, and therefore that allows a hyperscaler and cloud builder not only bigger instances, but a little more bin packing on a single box for smaller instances. (In theory, the 80-core and 128-core versions of the Ampere Computing chips should do the same.) And that is also why the 96-core “Genoa” and 128-core “Bergamo” chips from AMD are so important – they keep well ahead of the Intel roadmap, keep pace with the Ampere Computing Altra roadmap, and possibly with the AWS Graviton roadmap, too.
The other thing to notice is how close these systems are in cost from these three vendors. When you have all three vendors offering all three compute motors at roughly the same price points, you know what that is? Well, if it isn’t collusion, then it is a price war.

AI Powerhouses Choose The Nuclear Option
When you need to provide electricity to power and cool 100,000 accelerators, or maybe even 1 million of them in a few years, in a single location to run an AI model, you have to start thinking about the unthinkable if you also want to use carbon-free juice to power …

Azure Can’t Make Up For On Premises Profit Decline At Microsoft
If you think it might be difficult to sell companies general purpose servers when they are frenzied about GenAI and trying to figure out how to get GPU-accelerated systems, you ought to try to convince the same companies to upgrade to Windows Server 2025, which launched last November. Yes, that …
SambaNova Pits LLM Collective Against Monolithic AI Models
There is more than one way to get to a large language model with over 1 trillion parameters that can do lots of different things and enterprises can use to create AI training and inference infrastructure to extend and enrich their thousands of applications. One is to take a big …
SpecInt depends on memory latency and bandwidth as do real applications which are also affected by the speed of storage. It is further possible, due to contention between neighbouring VMs and NUMA effects, that not all identically-provisioned instances perform the same from any particular cloud provider.
It would be interesting to compare the consistency in real measured performance of identically provisioned VMs within a single cloud provider. I wonder whether any pattern would appear after about 100 samples per type per cloud.
How interesting! Only one little question: no doubt that Google and Microsoft priced their Altra instances strategically against Graviton. However graviton has been developed in-house over a number of years which means it may have a significant lower cost structure than Altra purchased by G and M. Without seeing real numbers, I wonder G&M as well as Oracle baidu etc will be able to make much money from Altra instances? Or they have to be there, because some customers or applications request them.
Oracle were the first to deploy ARM-Based, Ampere servers.
Yup. And Oracle owns a stake in Ampere Computing, too.