

When you come to the crossroads and make a big decision about selling your soul to the devil to get what you want, it is supposed to be a dramatic event, the stuff that legends are made of.
In this case, with the announcement of a $105 million deal for Hewlett Packard Enterprise to build the “Crossroads” supercomputer for the so-called Tri-Labs of the US Department of Energy – that would be Lawrence Livermore National Laboratory, Los Alamos National Laboratory, and Sandia National Laboratories, who are, among other things, responsible for managing the nuclear weapons stockpile for the US government – the drama has more to do with the changes in the Intel Xeon and Xeon Phi processor and Omni-Path interconnect roadmaps than anything else.
The DOE supercomputer architects always have to hedge their compute, networking, and storage bets across the Tri-Labs and so do their peers at Oak Ridge National Laboratory, Argonne National Laboratory, Lawrence Berkeley National Laboratory, and a few other national labs. You want commonality because this drives down costs and complexity, but you want distinction so you can push the limits on several technologies all at the same time because that is what HPC centers are actually for and it helps balance out risks when roadmaps get crumpled.
The Advanced Simulation and Computing (ASC) program at the DOE has funded the development of so many different computing architectures over many years that it is hard to keep track of them all. There are several streams of systems that are part of the National Nuclear Security Administration, which runs simulations relating to the nuclear stockpile, and there is an interleaving of machines such that Lawrence Livermore gets the biggest one in what is called Advanced Technology Systems, or ATS, program and then either Los Alamos or Sandia gets the next one and they share it. Like this:
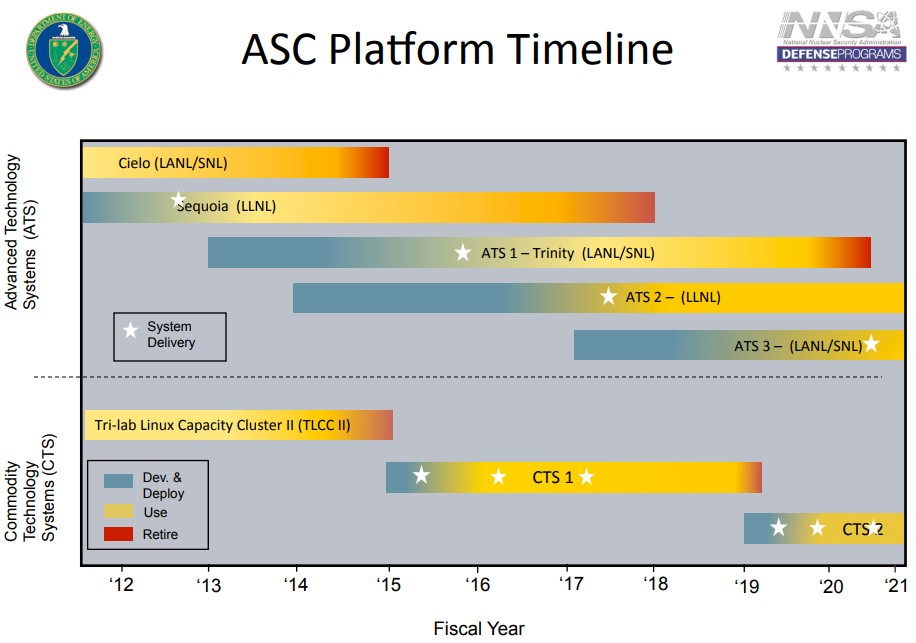
In the chart above, the ATS 2 system at Lawrence Livermore is the existing “Sierra” system, based on IBM Power9 processors and Nvidia V100 GPU accelerators hooked with Mellanox (now Nvidia) 100 Gb/sec InfiniBand interconnects. The ATS 4 system is Crossroads, the award for which is being announced now, and the ATS 5 machine, which is not shown on this old roadmap, is for the future “El Capitan” machine, built from future AMD Epyc CPUs and Radeon Instinct GPUs interlinked by a future rev of HPE’s Cray Slingshot interconnect, which we detailed back in March and which is expected to surpass 2 exaflops in peak 64-bit floating point processing capacity when it is installed in 2022. The Commodity Technology Systems are less about creating thoroughbred supercomputers than regular workhorses that can pull the HPC plows for less money than the Advanced Technology Systems, which are “first of a kind” systems that push the technology.
The current “Trinity” machine shared by Los Alamos and Sandia and installed at Los Alamos, is the one that is coming to the end of its life and the one that Crossroads will replace – ATS 1 in the chart above. The plan was to have the Crossroads replacement ready to go sometime about now, when Trinity would be sunsetted, but processor roadmaps at Intel have been problematic during the 10 nanometer generations of Xeon SP and Xeon Phi processors, to the point where Intel killed off the Xeon Phi line in July 2018 and deprecated its 200 Gb/sec Omni-Path interconnect a year later. The future Xeon SP, Xeon Phi, and Omni-Path technologies were the obvious and easiest choices for the compute and networking in the Crossroads system, given the Trinity all-CPU design and Intel’s desire to position Omni-Path as the successor to the Cray “Aries” XC interconnect used in the Trinity system. As it turns out, Intel has just this week spun out the Omni-Path business into a new company, called Cornelis Networks, founded by some InfiniBand innovators, and Omni-Path will live on in some form independent of Intel. So the technology used in Trinity will evolve and presumably be used in HPC and AI systems of the future. But that spinout did not come in time for Tri-Labs to not chose HPE’s Cray Slingshot interconnect, a variant of Ethernet with HPC extensions and congestion control and adaptive routing that makes a hyperscaler envious, for Crossroads. For whatever reason, InfiniBand from Mellanox was not in the running.
The existing Trinity system is an all-CPU design, and Tri-Labs has been sticking with all-CPU systems for the machines that go into Los Alamos and Sandia under the ATS program; obviously, Lawrence Livermore chose a hybrid CPU-GPU machine for the Sierra and El Capitan systems. Again, this is about hedging technology bets as well as pushing the price/performance curves on a number of architectural fronts among the DOE labs. Trinity was built in stages, and that was not an architectural choice so much as a necessary one, as Jim Lujan, HPC program manager at Los Alamos, told us back in July 2016 when the “Knights Landing” Xeon Phi parallel processors were first shipping. Trinity was supposed to be entirely composed of these Xeon Phi processors, but they were delayed and the base machine was built from over 9,486 two-socket nodes using the 16-core “Haswell” Xeon E5-2698 v3 processors and another 9,934 nodes based on the 68-core Xeon Phi 7250 processors, for a total of 19,240 nodes with 979,072 cores with a peak performance of 41.5 petaflops at double precision. Trinity had 2.07 PB of main memory, and implemented a burst buffer on flash storage in the nodes that had a combined 3.7 PB of capacity and 3.3 TB/sec of sustained bandwidth. The parallel file system attached to Trinity had 78 PB of capacity and 1.45 TB/sec of sustained bandwidth.
Importantly, the Trinity system had about 8X the performance on the ASC workloads compared to the prior “Cielo” system that predated it, which was an all-CPU Cray XE6 system installed in 2013 based on AMD Opteron 6136 processors and the Cray “Gemini” 3D torus interconnect.
As it turns out, Crossroads is running about two years late, and that is both a good thing and a bad thing. The bad thing is that this means Trinity has to have its life extended to cover between now and when Crossroads is up and running in 2022. The good news is that the processor and interconnect technology will be all that much better when Crossroads is fired up. (We realize that this is a big presumption.)
The DOE and HPE are not saying much about Crossroads at the moment, but we do know that it will be based on the future “Sapphire Rapids” Xeon SP processor from Intel, and that it will, like Trinity, be an all-CPU design. Sapphire Rapids, you will recall, is the CPU motor that is going into the “Aurora” A21 system at Argonne National Laboratory, but in that case, the vast majority of the flops in the system will come from six Xe discrete GPU accelerators attached to each pair of Sapphire Rapids processors, as we talked about in November last year. It will be based on the HPE Cray EX system design, formerly known as “Shasta” by Cray, and will use the Slingshot interconnect as we said as well as liquid cooling for compute cabinets to allow it to run faster than it otherwise might and cool more efficiently. The systems will run the Cray Programming Environment, including Cray’s implementation of Linux and its compiler stack.
The Cori supercomputer at Lawrence Berkeley and the Trinity supercomputer at Tri-Labs were based on a mix of Xeon and Xeon Phi processors and the Aries interconnect. So it was reasonable to expect, given past history, that the Crossroads machine shared by Los Alamos and Sandia would use similar technology to the “Perlmutter” NERSC-9 system at Lawrence Berkeley, since these labs have tended to move to technologies at the same time over recent years. But that has not happened this time.
The Perlmutter and Crossroads machines are based on the Shasta – now HPE Cray EX – systems and both use the Slingshot interconnect, but the resemblance ends there. Perlmutter is using a future “Milan” Epyc processor from AMD plus “Ampere” A100 GPU accelerators from Nvidia. The Perlmutter machine will be installed in phases, with the GPU-accelerated nodes with more than 6,000 GPUs coming in late 2020 and the over 3,000 CPU-only nodes coming in the middle of 2021. Crossroads has no accelerators and is using the “Sapphire Rapids” Xeon SPs only for compute – albeit ones that will support Intel’s Advanced Matrix Extensions for boosting the performance of machine learning applications.
HPE says that on applications, Crossroads will have about 4X the oomph of Trinity, which should mean somewhere around 165 petaflops at peak double precision. This is quite a bit of oomph for an all-CPU system, but then again, it is dwarfed by the 537 petaflops that the “Fugaku” supercomputer at RIKEN laboratory in Japan, built by Fujitsu using its A64FX Arm chip with wonking vector engines, delivers at double precision.




It seems I buy the same brand of potato chips every time I go grocery shopping (online now), so it makes sense some HPC people would buy Intel chips (again online) due to a similar habit. For an all CPU design it would have been much more exciting to get the Fugaku chips, with perhaps a dash of SerDes wasabi for doubling the size of the directly-connected high-bandwidth memory.
DOE is moving on from trinity, which is half cpu, half xeon-phi. So they have experience with high bandwidth memory. They clearly have decided it’s not worth the trade-off. The A64FX, at 32GB over 48 cores gives you less than 700MB per core to work with. It’s fast, but if your code ENOMEMs, fast doesn’t help.